

Jakarta EE Politics, Java-oriented AI Benchmarks and FloatPoints: Not quite a “Sezon ogórkowy” - JVM Weekly vol. 142
Sezon ogórkowy == Cucamber Season == Summer lull 😁


I was hoping we’d talk today about the videos from the latest JVMLS, but unfortunately, they’re still not out. So this week’s edition will be a bit more… gossipy, straight from the Jakarta EE community mailing lists 😁.
But we’ll also touch on AI benchmarks and a major new feature that was once meant to be part of Valhalla, but along the way seems to have been adopted by Panama.

1. The Soul of the Specification: Jakarta EE and MicroProfile in a Political Grip
The health of a mature technology ecosystem can be measured by its simultaneous growth on three distinct fronts: corporate governance, which defines the rules of the game; specialized tools, which provide the “means of production” (terminology intended, to get you into the right political mood); and the base platform, which serves as the fundamental engine. This week’s events in the world of Jakarta EE are a perfect example of this multifaceted maturity – we’re witnessing an intriguing debate about the philosophical soul of the project. The Jakarta EE community saw the eruption of a discussion focused on a proposal that touches the very core of the platform’s identity: its commitment to vendor neutrality.
The debate, sparked David Blevins of Tomitribe , is an interesting dialogue about the long-term credibility and governance structure of enterprise Java standards. It began with Blevins’ email to the WG list, in which he proposed a significant restructuring of the Jakarta EE Working Group. This ties into an ongoing discussion about formally “hosting” the MicroProfile specification within Jakarta EE - a topic raised on WG mailing lists and meetings. Blevins made it clear: his coalition, including Tomitribe, Payara, Red Hat, and IBM, has enough votes to block the merger. However, they are willing to change their stance and ensure it succeeds - but only under one fundamental condition: that the community moves toward stricter, real vendor neutrality.
At the heart of the proposal lies the argument that, despite neutrality being declared in the charter, the WG’s current structure creates a clear conflict of interest. Blevins argues that the WG’s marketing, budget, and community initiatives are disproportionately used to promote and support its own implementation project - @GlassFish (historically used for referential implementation) - at the expense of equal opportunity for other vendors like Payara, Open Liberty, WildFly, or Apache TomEE. The EE4J umbrella was created before the WG was formalized, and the WG rules explicitly state vendor-neutral marketing and processes. Also OpenLiberty's Emily Jiang supports moving GlassFish out of the Jakarta EE WG in the name of implementation neutrality and suggests the WG should focus on API/Spec/TCK, while implementation projects should live outside the WG (as other Eclipse ecosystem projects do). At the same time, she doesn’t see the need for a new WG just for GlassFish - maintaining its development under existing foundation structures should suffice.
OmniFish has now joined the discussion - an important voice as the steward of GlassFish (historically used to run the Platform TCK) - so their stance carries practical weight. They supports moving EE4J out from under the Jakarta EE Working Group without creating a new group (a top-level project is enough), and firmly disputes the allegations of GlassFish being “privileged”. They stress there is no deliberate marketing endorsement or preferential resources; any traces are historical leftovers being phased out. Pragmatically, they note the Platform TCK has to run on some implementation - so far GlassFish has helped - but broader participation would only strengthen the ecosystem. At the spec level, pluralism is already happening (e.g., Jakarta Data on Hibernate; Core Profile on Open Liberty and WildFly). Bottom line: unwinding EE4J-Jakarta EE dependencies makes sense and if that’s a condition for moving MicroProfile, waiting is acceptable, but dragging it out risks putting work on both project into limbo due to dimishing public interes.
As I’m writing this, the discussion is still ongoing, but it feels like we haven’t had such an open conversation about governance in this community for a long time. Interestingly, similar tensions and transparency questions often arise in other dynamic ecosystems, such as Node.js governance or Rust governance, where balancing the influence of big companies with the community’s voice is particularly delicate.Well, I’ve got my popcorn ready and I’m waiting to see what happens.

2. More than Generic Rankings: Java Takes AI Measurement Seriously
In the AI world, the true proving ground and “gold standard” has become SWE-bench - a benchmark built from thousands of real GitHub issues, where the model not only writes code but must actually fix a bug in a repo and pass unit tests. This is the framework nearly every model now “flexes” on in presentations: from OpenAI to Anthropic and Mistral AI , everyone shows off their SWE-bench results because it’s today’s gold standard for proving whether AI can handle real software engineering, not just academic puzzles.
The problem is that SWE-bench and its variants - Verified, Live, reBench - rely heavily on the Python ecosystem. Models are thus learning to patch small snippets in a scripting, dynamically typed world that doesn’t reflect JVM complexity. And that’s a whole different category of problem: large, multi-module projects, complex builds, static typing, and enterprise dependencies. So the question keeps coming up: if Python has its sandbox, when will Java, Kotlin, and Android get benchmarks that truly test whether AI can handle those ecosystems - not just LeetCode or snake language challenges.

This trend toward realism is showing up in new tools. For JVM, Kotlin-bench from Firebender and Aman Gottumukkala has emerged, a benchmark for evaluating LLMs on 100 real-world Kotlin and Android tasks. Like SWE-bench, it uses actual GitHub issues, but checks success objectively by running existing unit tests. It also revealed how much output format matters - models generating full files performed much better than those producing diff patches (which often had errors). Also, the sheer size of Android projects often exceeded even large context windows, favoring models with the largest memory. A nice deep dive can be find there here.
That’s Kotlin and Android. But in JVM frameworks, a new benchmark has landed that could shake things up - the Brokk Power Ranking. Brokk by Jonathan Ellis (which you may remember from one of our previous Friends of OpenJDK (Foojay.io) editions) uses 93 real-world tasks pulled from repos like JGit, LangChain4j, Apache Cassandra, or Lucene. Instead of abstract puzzles, it tests models in realistic settings - reading existing code, fixing fragments, navigating large projects.
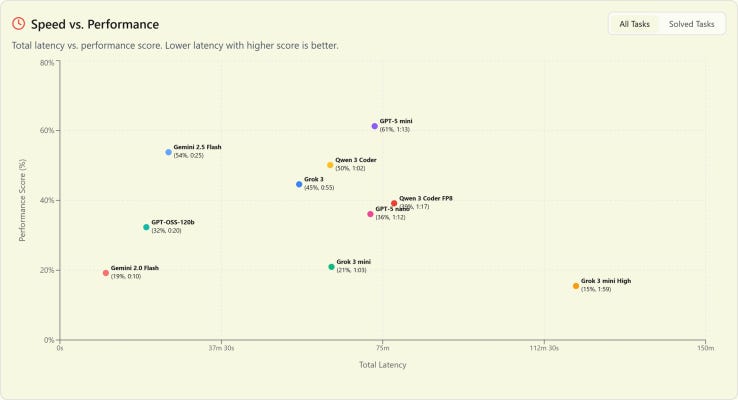
The results are interesting. GPT-5 dominates - best quality, best cost-effectiveness, though relatively slow. Models like Sonnet 4 or Opus 4.1 are faster, but less accurate. Another insight: as task length grows (up to 108k tokens), most models’ performance drops (unsurprising to anyone following Context Engineering related topics), though top ones - GPT-5 and Gemini 2.5 Pro - degrade more gracefully. Interestingly, only some models truly benefit from “reasoning mode,” and Chinese models underperform on Java compared to other benchmarks.
The whole thing is open source, updated biannually, and Brokk invites the community to add more JVM repos. This could be the start of a truly “Java-native” benchmark, in a space long dominated by Python - and I’ll definitely share future editions here.
One more curiosity: generic benchmarks themselves are evolving toward realism. A recent paper introduces AutoCodeBench, proposing a stricter approach to fully autonomous code generation, with 3,920 tasks in 20 languages, hidden tests, and a black-box methodology. The authors criticize existing methods for oversimplification and reliance on manual checking, and instead push for a contest-like approach: the AI model only gets a problem description (a la LeetCode or AtCoder), and must produce working code that passes hidden unit tests. The study shows no single model dominates, with leaders like GPT-4 and Claude 3 Opus showing different strengths depending on task complexity.
You just need to know which ones should be used when!

3. Project Panama targets native AI performance gains
Finally, staying in AI topics - but this time in the context of the JVM itself!
Back in December I wrote for the Java Advent Calendar an article: JVM in the Age of AI: A Bird’s-Eye View for the Mechanical Sympathizers. It’s a survey of initiatives around running AI workloads on the JVM. One of the key points was Project Panama and its Vector API, still in incubation, which lets the JIT compiler reliably translate computations into optimal SIMD instructions on modern CPUs. The latest panama-dev mailing list proposal is to add native support for the Float16 (FP16) data type directly into the Vector API - no need to wait for Valhalla anymore.
Why is this important (if you don’t want to read the full 21-minute deep dive 😁)? FP16 is a 16-bit format that trades some precision (about 3-4 decimal digits, range ±65504) for huge performance gains: halving memory and bandwidth requirements, while doubling computational throughput on modern hardware. High precision is crucial during training, but often excessive during inference, where small losses rarely impact output quality. The proposal adds a new Float16Vector type and - critically - a deterministic fallback mechanism ensuring code portability even on older hardware (though not always with the same performance).
And why does this matter? Because of quantization. FP16 is the natural “stop” on the road to lighter formats (INT8, INT4). Switching from FP32 to FP16 halves model size, unlocks specialized units (e.g., Tensor Cores), and makes further safe precision reduction possible - though INT8 and INT4 are integer-only formats. In practice: a model like Llama 3.1 8B fits in ~16 GB VRAM with FP16 and runs at almost no quality loss versus FP32, with INT8 it drops to ~8 GB (often with negligible quality loss) and INT4 makes it possible to run on GPUs with 4–6 GB or even on edge devices (laptops, some phones) - which is why Gemma and Mistral already ship INT8/INT4 variants.

FP16 is critical because it sets the “upper quality ceiling” for quantized versions: it provides a fast baseline, a deterministic fallback to higher precision when INT8/INT4 degrade results (e.g., in long outputs or tricky operators), and enables mixed-precision execution — critical paths in FP16, the rest in INT8/INT4. Adding it to the platform ensures compatibility across libraries and frameworks.
So that every library doesn’t reinvent it on its own.

PS: And wrapping up, I have some small announcement for you!
Level Up Your Skills: A Look at QCon San Francisco and QCon AI New York
This week, I want to talk about something a little different. We spend a lot of time discussing the nitty-gritty of the JVM, but it's also crucial to zoom out and look at the bigger picture of software development and our careers. That's where conferences like QCon come in, and there are two fantastic ones on the horizon that I think you'll find incredibly valuable.
For those of you who aren't familiar, QCon is a conference designed for senior software engineers, architects, and team leads. It's not about marketing fluff or high-level overviews. QCon is about deep, practical insights from senior practitioners who are in the trenches, building and scaling real-world systems. You'll hear from the folks at companies like Netflix, Google, and eBay, who will share their hard-won lessons and innovative solutions.
Attending a QCon event is more than just a series of talks. It’s an opportunity to connect with peers who are facing the same challenges as you, to have those "hallway track" conversations that spark new ideas, and to return to your team with a renewed sense of purpose and a fresh perspective. You'll leave feeling inspired, more confident in your technical decisions, and better equipped to lead your team through the ever-changing landscape of software development.
Personally, I love QCon and all there talks. Their Youtube Channel is particularly on of the best available.
However, youtube recordings will not allow you to understand the vibe of the real thing. So here are the two upcoming events I'm particularly excited about:
QCon San Francisco (November 17-21, 2025)

This is the flagship QCon event, and for good reason. It covers a broad range of topics, from "Architectures You've Always Wondered About" to "Innovations in Data Engineering" and "Engineering Leadership for All." If you're looking to get a comprehensive overview of the latest trends and best practices in software development, this is the conference for you. It’s a chance to step away from your daily tasks, immerse yourself in a learning environment, and come back with a wealth of new knowledge and connections.
As a reader of JVM Weekly, you can get a $100 discount on your ticket. Use the promo code JVMSF100 when you register.
QCon AI New York (December 16-17, 2025)
The world of AI is moving at a breakneck pace, and it can be hard to separate the hype from what's actually working in production. That's what QCon AI is all about. This conference is specifically designed for senior practitioners who are using AI to accelerate the software development lifecycle. You'll hear from engineers who are building and scaling AI systems in real organizations, sharing their proven patterns, responsible governance practices, and hard-won lessons.
This is a newer, more focused QCon event, and it's a fantastic opportunity to get a deep dive into the practical side of AI. If you're looking to move beyond experimentation and adopt AI that works, this is the place to be.
I'm happy to info that QCon also here provide a $35 discount for JVM Weekly readers. Use the promo code JVMAI35 at checkout.
I truly believe that investing in your own learning and development is one of the best things you can do for your career. QCon is a great way to do that 😊.
Now you need to decide which one. Maybe both 😁?

Hi, the link for OmniFish in this article goes to a broken LinkedIn link. Shouldn’t it link to their website, https://omnifish.ee ?