

"Brokk: AI for Large (Java) Codebases" with Jonathan Ellis - JVM Weekly vol. 132
Today, we have a guest post from Jonathan Ellis, a long-time CTO of DataStax, contributor of Apache Cassandra, creator of JVector and (finally) creator of Brokk.



Last May, I announced that JVM Weekly had joined the Foojay.io family. Foojay.io is a dynamic, community-driven platform for OpenJDK users, primarily Java and Kotlin enthusiasts. As a hub for the “Friends of OpenJDK,” Foojay.io gathers a rich collection of articles written by industry experts and active community members, offering valuable insights into the latest trends, tools, and practices within the OpenJDK ecosystem.
So just like last month, I’ve got something special lined up - a fresh repost of a JVM Foojay.io article. This time the keyboard belongs to Jonathan Ellis - the original co-creator and long-time CTO of Apache Cassandra, creator of JVector and veteran of DataStax. Yes, the piece takes Brokk - his shiny new product I described week ago - as its narrative hook, but don’t mistake it for a product plug: it’s a nice tour of just how hair-raisingly complex high-scale code migration can be when millions of rows and thousands of nodes are on the line. I find the knowledge important in 2025.
Brokk: AI for Large (Java) Codebases
There are two reasons that AI makes mistakes writing code:
The LLM just isn't smart enough to tackle the problem effectively, and it simply gets the answer wrong.
The AI doesn't know enough about the relationships and dependencies of the code it's editing, so (best case) it hallucinates APIs that don't exist or (worse, because more subtle) it solves the problem in an awkward way that increases technical debt.
The first category is small, but it does still exist; e.g., concurrent data structures remain challenging for today's models to get right the first time. AI labs will continue to make progress on this.
The second category is the overwhelmingly dominant one for almost every large codebase today. I experienced this myself when I moved from writing the JVector library, where AI was very useful, to integrating it with Cassandra, where AI tools struggled because of the codebase size. Brokk is designed to solve this problem.
Brokk is a standalone application, not a VSCode or IntelliJ plugin, because it's designed around letting you supervise the AI effectively instead of writing code by hand. AI is faster and more accurate at the tactical level of writing and even reading code line-by-line; you need new tools to supervise effectively at a higher level.
Part of effective supervision is being able to understand why the AI (inevitably) makes mistakes, so you can prevent and fix them. Since category 2 errors are caused by the AI not having enough information to make optimal decisions, to fix them you need to know what information the AI sees. Here's how Brokk makes this possible.
Sidebar: Under the Hood
Brokk is built with Java Swing for the UI, Joern for advanced code analysis, Jlama for local inference, and langchain4j to access LLM APIs. Read more about what makes Brokk tick here, or check out the source on GitHub.
A Quick Introduction to Brokk
When you start Brokk, you'll see five main areas:

From left to right, starting at the top, these are:
Instructions: Code, Ask, Search, and Run in Shell specify how your input is interpreted. Stop cancels the in-progress action. Deep Scan recommends relevant source files to add to the Workspace to accomplish the given task.
Output: Displays the LLM (or shell command) output.
Activity: A chronological list of your actions. Can undo changes to the Workspace as well as to your code.
Workspace: Lists active files and code fragments. Manipulated through the right-click menu or the top-level Workspace menu.
Git: The Log tab allows viewing diffs or adding them to context; Commit tab allows committing or stashing your changes
The Workspace
The Workspace is the core of Brokk's approach to managing context. Here's an example of (most of) the different types of context that Brokk can manipulate:

From top to bottom, these are:
An image file added from local disk
An ordinary source file marked read-only
Summaries of all the classes in the langchain4j-core library (more on how Brokk deals with dependencies below)
A pasted image (the description is automatically generated)
A pasted stacktrace
A diff of a Git commit
A page of langchain4j documentation, acquired by pasting the URL
Usages of Brokk's GitRepo::getTrackedFiles method
An ordinary, editable source file
You can right-click on any of the referenced files on the right to add them individually or as a group to the Workspace. This is particularly useful to instantly pull all the files touched by a Git commit into the Workspace.
Brokk also enriches context with what it knows about your code. Here, I've double-clicked on the stacktrace (on the left) and the getTrackedFiles usages (on the right) to show their contents:
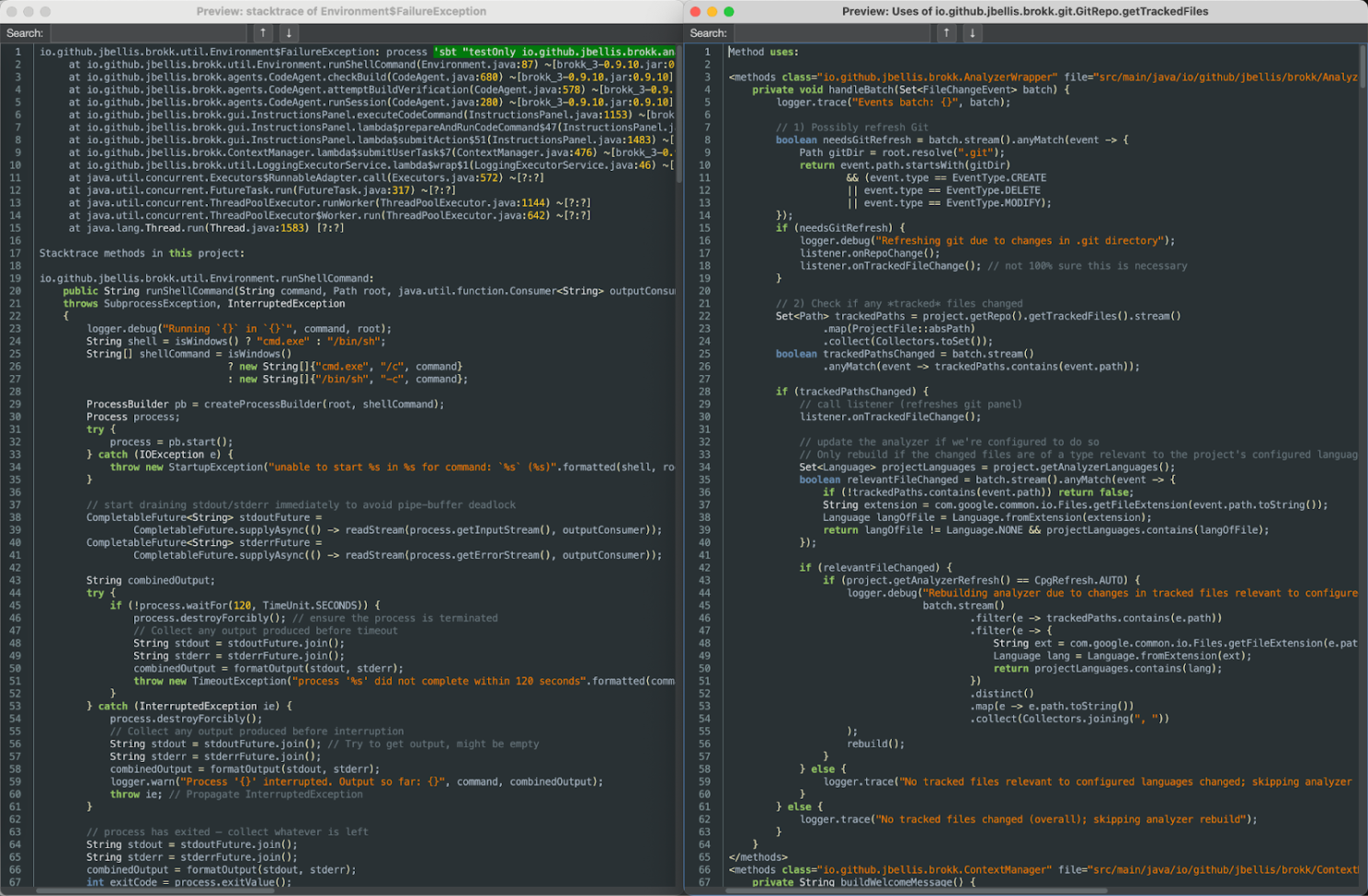
For the stacktrace, Brokk includes the full source of any method in your project. For the usages, it similarly shows not just the call site but the source of each calling method. This lets Brokk perform refactoring across your codebase without having to load entire files into the Workspace. Smaller contexts mean faster and cheaper calls to the LLM.
The other main tool that Brokk uses to slim down the Workspace is summarization. Here is what a Brokk summary of a source file looks like:

Brokk extracts the signatures and declarations to show the LLM how to use this class without hallucinating. Brokk also includes private fields and methods to give a hint of how the implementation works under the hood. This means that you almost never need to include full source files in the Workspace unless they are going to be actively edited.
Recommendations
Brokk's goal is to make context management explicit (you always know what's in the Workspace) but not manual (you don't have to add each file by hand or even know what the right files are).
We already covered how Brokk links referenced files in the Workspace so you can easily add related code. Brokk also offers similar recommendations as you type your instructions in realtime.

This is called Quick Context, and it's optimized for speed. If you want to trade that speed away for a more in-depth analysis, click on Deep Scan:

This is a solid set of recommendations for the serialization refactor, although not perfect; I would change Json.java and ContextFragment.java from Summarize to Edit.
Working with Git
The Git Panel, located at the bottom of the Brokk interface, is your primary interface to bring Git-based historical context into the Workspace. It's divided into two main tabs: Log and Commit. The Commit tab is fairly self-explanatory, so we'll focus on the operations available in the Log.

Capture Diff: This is the most commonly used integration point, useful for asking questions, troubleshooting regressions, and performing merges.How it works: Right-click any set of commits or file changes, in the log and select Capture Diff. This adds a unified diff of the selected changes to your Workspace.Best for: Providing the LLM with focused context about a past bug fix, feature implementation, or refactor. You can also right-click on the diff to add all (or some) of the affected files to the Workspace in their entirety or as summaries.

Capturing Older Revisions: Primarily used to give the LLM an anchor point for a particularly complex diff.
Compare with Local: Opens a human-readable diff window from which you can revert changes by chunk.
With these tools, Brokk allows you to easily pull Git's knowledge of your code's history into the Workspace to improve the LLM's ability to solve problems.
Actions
The Instructions panel is where you provide your textual input to Brokk. The buttons below it (and related features like Deep Scan) determine how Brokk interprets and acts upon those instructions.
Code: Executes your instructions to directly modify the code files currently in the Workspace.
Ask: Allows you to ask questions about the code in your Workspace or general programming concepts.
Search: Performs an "agentic" search across your entire project (even files not currently in the Workspace) to find code relevant to your instructions.
Run in Shell: Executes shell commands.
Architect: Engages an agentic system capable of performing multi-step, complex tasks.
Sidebar: LLM Models
Brokk allows configuring both default models for each of the main actions, and a selection of commonly-used overrides. This allows the best of both worlds with a default you use most frequently, without having to reconfigure things (or worse, restart) when you want to use a different option.

See this article for more on how to choose which models to use.
The Edit Loop
After each set of changes to your code (whether via manual invocation of Code, or via the Architect), Brokk attempts to compile your code and run tests; it then automatically takes build and test failures back to the LLM for revision.
To do this effectively, Brokk asks the LLM to infer details about your build when you first open a project. This works particularly well with Gradle and Maven projects, but it can also handle more obscure systems like ant and sbt.
By default, Brokk runs only the tests in the Workspace after each set of changes to your code; if your test suite runs quickly enough, you can change that to run all tests instead, in File -> Settings -> Build:

You can also (ab)use the Run All Tests option to specify an arbitrary shell command; any non-zero exit code will be treated as a failure and sent to the coding LLM for revision. For example, when I was debugging tree-sitter parsing I changed it to tree-sitter query … && sbt "testOnly …"
Activity History
The Activity panel is designed to allow you to solve side quests, like a quick refactor or a bug fix, and come back to where you were without losing your flow or confusing the AI with irrelevant context. There are three options when you right-click on an earlier state:

Undo to Here: This action reverts both your file changes on disk and the Workspace to the state they were in at that selected point in history. Any file modifications made after that point will be undone. (But Git history is not touched.)
Copy Workspace: This option reverts only the Workspace to the selected point. Critically, this action does not affect any changes made to your files on disk. This is ideal for scenarios where you've completed a side quest, committed those file changes, and now want the AI to refocus on your main task as it was before the diversion, while keeping the code from your side quest intact.
Copy Workspace with History: Copies the Workspace contents and also the Task History from the previous state; useful for when you need to continue building on your conversation thread from the main development line.
Dependencies
Often, you'll work with dependencies that are poorly documented or for which your LLM lacks sufficient version-specific knowledge, leading to API hallucinations. Brokk addresses this by allowing you to pull these dependencies into your project, where they can be manipulated like any other source file.
To do this:
Use File -> Import Dependency... and select the appropriate JAR file for your dependency.
Brokk will decompile the JAR. You'll see a message like "Decompilation completed. Reopen project to incorporate the new source files."
Reopen your project as prompted.
Once reopened, the decompiled source code from the dependency is available to Brokk. You can interact with these decompiled files much like your own project source:
They can be read, searched, and their symbols can be used for operations like "Symbol Usage" or "Call graph."
They can be summarized. To get an overview of an entire imported library, you can use the Summarize action (from the Workspace menu or Ctrl+M), and in the Summarize Sources dialog, enter the path to the decompiled dependency JAR followed by the recursive glob pattern ** (e.g., .brokk/dependencies/langchain4j-core-1.0.3.jar/**.java) to summarize all classes within it. You don't need to memorize this path; just give the name of a class in the library and hit ctrl-space to autocomplete it. This is how I summarized the langchain4j-core library in the first Workspace screenshot.
These decompiled files are treated as read-only; you cannot edit them directly.
The key benefit is that the LLM (and Brokk's code intelligence features) gain access to the precise API and structure of the exact version of the library you are using. The decompiled source is highly effective for LLM comprehension—often 99% as useful as the original source would be—and this drastically reduces the chances of the AI hallucinating non-existent or incorrectly used APIs from the dependency. That said, automating the download of sources jars to avoid decompilation is on the roadmap as well.
Putting it all together
Lutz Leonhardt has recorded a video showing his workflow using Brokk to solve a "live fire" issue in jbang. Check out how he uses Deep Scan to get a foothold in the code, then Ask and Search to refine his plan of attack before executing it with Code:
Conclusion
Today's models are already smart enough to work in your codebase and make you 2x to 5x more productive; the reason that it doesn't feel that way is because they doesn't know your specific codebase. Brokk fixes this. It's a standalone Java application, not an IDE plugin, designed to let you find and feed the LLM only the relevant context (files, summaries, diffs) via its Workspace. This makes the AI faster, cheaper, and less prone to hallucinating or writing awkward code. Tools like Deep Scan, agentic Search, Git integration, and dependency decompilation help you build this focused context efficiently.
We created Brokk to let you supervise an AI assistant at a higher level than autocompletion.
PS: If you're wrestling with AI in a large Java project, see how Brokk can improve its accuracy and your productivity. JVM-Weekly readers will get a $10 credit towards LLM usage with the following link. Try it out and let us know what you think!
PS2: The text was originally published on Brokk.ai blog.

And now, let's review some of the other cool things that appeared on Foojay.io last month.
Foojay Podcast #72: JCon Report, Part 1
Fresh from the corridors of JCON in Cologne, Foojay Podcast #72, hosted by Frank Delporte, kicks off a multi-part “JCON Report” with a lightning-round of seven mini-interviews that feel like speed-dating for Java minds:
Richard Fichtner - conference host - sets the scene
Bruno Souza dishes straight-talk advice on plotting your career rocket-launch
mentor-in-chief Markus Westergren explains how to level-up to senior without the imposter-syndrome baggage
Snyk’s 🧑🏼💻 Brian V. proves that a mic and a keyboard are still a dev’s sharpest weapons, sharing tactics for public speaking and writing via NLJUG
Aicha Laafia reminds us that greener code is the new black
🎩 Baruch Sadogursky time-travels through 30 years of Java before forecasting how AI will reshuffle our job descriptions
Dmitry Yanter visualises the open-source spider-web to show who’s really pulling the strings.
It’s a breezy, 53-minute sampler, ideal while you wait for Part 2 to drop 😄
How to send prompts in bulk with Spring AI and Java Virtual Threads
Raphael De Lio latest Foojay tutorial, How to send prompts in bulk with Spring AI and Java Virtual Threads is for anyone stress-testing OpenAI rate limits: he shows how to lash Spring AI to Java 21’s virtual threads, letting you shotgun hundreds of prompts in parallel without frying real OS threads.
The recipe is dead simple - grab your text list, filter, slice into 300-ish chunks, fire each batch through a newVirtualThreadPerTaskExecutor() via CompletableFuture, catch any problematic calls so one 5xx doesn’t torpedo the fleet, then persist the good stuff in bulk. Text is proving that with lightweight fibers, “slow I/O” finally bends the knee to synchronous-looking code.
Building a Real-Time AI Fraud Detection System with Spring Kafka and MongoDB
This is not the only text covering Spring AI. Tim Kelly tutorial Building a Real-Time AI Fraud Detection System with Spring Kafka and MongoDB shows how to use a Java 21 Spring Boot app that seeds synthetic customers, pipes their transactions through Kafka, dumps them into MongoDB, and - powered by OpenAI-generated embeddings plus Atlas Vector Search - flags anything shady. By the end, you’ve got runnable code, a pipeline diagram, and a roadmap to production(ish)-grade fraud-busting — proof that Spring AI isn’t just for chatbots; it can keep your ledgers squeaky-clean while the JVM purrs.
Tim Kelly also has another article, Understanding BSON: A Beginner’s Guide to MongoDB’s Data Format, which lifts the JSON veil to show how MongoDB’s binary, type-rich BSON accelerates queries, packs extra types like ObjectId and Decimal128, and - via Java code samples - walks you through building, nesting, querying, and even raw-byte hacking of BSON documents so your apps run leaner and cleaner.
Building Autopo: An AI-powered Open Source Application to Manage .po Files
In Building Autopo: An AI-powered Open Source Application to Manage .po Files, Andrea Vacondio recounts how the demise of Zanata and the tedium of Google-Translating stray strings pushed him to spend ten weeks crafting Autopo - a JavaFX desktop tool that forks and modernizes jgettext into Potentilla, dresses the UI with AtlantaFX, and plugs in LangChain4j so OpenAI (or any pluggable model) can batch-translate, validate, and score gettext .po entries while keeping everything version-controlled locally.
The article traces this journey from pain points and requirements through architecture and AI prompts to real-world wins like translating PDFsam into new languages, ultimately proving that with modern JavaFX and a dash of AI, DIY localization can be both slick and sustainable - as long as humans still sanity-check the bots.
PS: This week I'm in New York for the TECH WEEK by a16z, however, I made a two-day detour to Boston to visit one of my company's clients.
And like any sensible person, instead of sightseeing downtown Boston, I headed off to visit the hospital viewpoint up on Fidelis Way Park. For all you "Infinite Jest" fans (do we have any here?) - I'm standing right where David Foster Wallace placed the Enfield Tennis Academy.

I was such pumped that I decided I needed to share that with you 🤷.
 | A guest post by
|