The Rest of the Story: June Edition - JVM Weekly vol. 181
From JetBrains and Microsoft placing opposite bets on the agent harness, through Spring AI 2.0 pulling the JVM’s agentic stack up to GA, June gave the platform no room to catch its breath.


Before we get into the technical weeds: is it this hot where you are too? I’m writing this from London, where the thermometer is closing in on 34 degrees, the sky is perfectly cloudless, and the islanders are reacting as if the apocalypse had begun (air conditioning here remains a largely theoretical concept - in the Kensington Event Center it was hot like in the the all-inclusive Hotel in Egypt).

But enough about the weather, because June in the JVM world ran just as hot.
This time the month split neatly into two halves. On one side, the JDK did that slow, unglamorous work that keeps Java in the game: a native Argon2 moved closer to the standard library, Babylon started lowering Java straight onto Tensor Cores, and the Vector API went through an honest, public reckoning with its own limitations. On the other side, the tooling layer reorganized itself around agents: JetBrains and Microsoft, in the same week, bet on almost perfectly opposite strategies, Spring AI reached 2.0 GA, and the enterprise MCP story I keep saying someone should finally write up keeps coming together. Let’s get started!
1. June: The Rest of the Story

I’ll start with a topic that, if you want to understand where AI-assisted programming is heading, says more than any chat-window demo: in that same stretch of June, JetBrains and Microsoft bet on almost perfectly opposite strategies for the agent harness, the layer that actually runs long, multi-step agent sessions.
JetBrains open-sourced Mellum2, a 12-billion-parameter coding model that activates only 2.5 billion parameters per token thanks to a Mixture-of-Experts architecture, routing each token through a subset of 64 experts. JetBrains’ Nikita Pavlichenko and Anton Semenkin call it a “focal model”: fast, specialized, and deliberately not racing the frontier models on breadth. The benchmarks back up that niche: on a single H100 it matches Qwen2.5-7B almost exactly in single-request mode (192 vs 193 tokens/s), but under concurrent load (and only that kind counts in production) it beats Qwen2.5-7B by 21% and Qwen3-8B by 79%, while its “thinking” variant hits 78.4% on EvalPlus.
A small model only needs one H100…

The technical report is honest about the cost: once you shift evaluation toward broad reasoning (GPQA Diamond, MMLU-Redux), the larger models take the lead again. Mellum2, though, runs on infrastructure you control. Claude Code and Codex run locally but route inference through the Anthropic and OpenAI APIs; Cursor’s work on Composer stays tied to Cursor’s platform (now with an xAI layer outside your walls). Mellum2 is a bet that ownership and on-prem will matter as AI moves deeper into the SDLC.

BTW: last Thursday I was at AI Tinkerers in Warsaw, where Damian Bogunowicz was talking about exactly this, Mellum2.
And then, as if for contrast, Microsoft went for full consolidation. Ji Dong, Senior PM on GitHub Copilot for JetBrains, announced that Copilot CLI is becoming the default agent harness in GitHub Copilot for JetBrains, with the IDE’s own local harness slated for deprecation. The reasoning is pure platform economics: maintaining a separate harness for JetBrains meant features and models landed there later than on Copilot’s other surfaces, so folding everything into Copilot CLI buys faster parity and (they claim) higher-quality results. CLI sessions run independently in the background while the IDE starts, monitors, and steers them, which incidentally makes parallel agent runs the default, and existing local sessions convert automatically.
Put them side by side and you have the whole tension of this moment. JetBrains: own your model, own your harness, run it yourself. Microsoft: one harness to rule them all, ship faster by not maintaining variants. Both approaches are reasonable and, interestingly, both can be the future at the same time
Remember how last month I joked that someone should write a roundup of the coalescing agentic JVM ecosystem? It keeps coalescing. And meanwhile Markus Eisele added an argument complementary to March’s MCP feature in Open Liberty: instead of rewriting a Jakarta EE 10/11 monolith into microservices, turn it into an MCP server, using the Adapter pattern to draw a hard trust boundary so agents get capability-scoped tools rather than raw access to the database and filesystem. He follows that with the Java Agent Skills Kit proposal, which lands squarely on the SKILL.md / SkillsJars thread we’ve been tracking: stop encoding agent behavior as one big, brittle prompt string, and start treating capabilities as separate, versionable, unit-testable components.
Bringing SOLID to agentic workflows is a sentence that’s either the future or a consultant’s slide. This month I’m leaning toward the former.
(It’s getting crowded - I really do need to finally write that roundup article, don’t I? 😉)
Sonatype is tightening the screws on OSS publishing to Maven Central. For now softly (the UI shows how far over the limit you are), and from August “for real.”
Brian Fox (CTO of Sonatype, and at one time chair of Apache Maven) laid it out on the company blog. The schedule is two-stage: from June 16 a “soft” phase with notifications only is underway, and from August 11, 2026 hard enforcement kicks in, meaning publishing is paused until usage comes down, an exception is approved, or a paid option is purchased. Three monthly metrics per organization are counted (file count, size, and number of releases), and as three-month averages at that, so a one-off spike or an urgent CVE fix won’t get you booted on their own.
Where this comes from: over the last 90 days, 10% of namespaces accounted for more than 88% of published files and more than 90% of the space taken by new releases, so the target is commercial-scale patterns (huge artifacts, very frequent releases, Central as the last-mile for SDKs), not ordinary OSS. For those over the threshold there are three routes: cut unnecessary publishing (Fox writes plainly that this is not the place for every CI build), request an exception for an unusual OSS project, or move to paid Maven Central Publisher Pro.
If you maintain anything with a regular release cycle, these two months until August are a good moment to look into the Usage Center and check which side of the threshold you’re sitting on.
That one of them happens to be my employer’s namespace, I can confirm firsthand: the problem isn’t purely theoretical. Both org.virtuslab and com.softwaremill, are already over the threshold, so we are observing development closely.
Nice shut out opportunity - VirtusLab is a team behind Scala 😉

On the security front, which always gets lost in the JEP noise, native Argon2 is becoming a Preview feature. JEP 8377081 moved from Draft to Submitted, bringing RFC 9106-compliant password hashing into the JDK itself.
All three variants (Argon2d, Argon2i, and the recommended Argon2id) come through the SecretKeyFactory SPI, and Argon2ParameterSpec exposes memory cost, time cost, and parallelism, so you can tune resistance to brute-force attacks from GPUs and ASICs. The practical benefit is one fewer reason to drag Bouncy Castle into your dependency tree just to hash a password like it’s 2015, and the JDK’s cryptographic foundation finally steps down from compute-bound PBKDF2 to something memory-hard.
Following March’s quietly impressive HPKE and ML-DSA bundle in JDK 26, the platform’s posture around post-quantum and modern hashing improves release by release.
The most interesting thing in Java’s AI/ML story that is not a wrapper over someone else’s API: Project Babylon is putting Java onto GPU Tensor Cores. Using Code Reflection and the Heuristic Accelerator Toolkit, Babylon can now lower Java functional interfaces to NVVM IR and PTX and perform half-precision matrix multiplication directly on the HMMA.m16n8k16.f16 instruction, with no JNI and no hand-written CUDA.
The HAT API introduces tensor types (hat.T16x16x16) that use CodeModel analysis to optimize tiling and data flow. Still very experimental, but the direction, namely a unified model in which OpenJDK lowers high-level Java straight to hardware-specific IR, is one I’d keep an eye on.
March gave us the “Java is fast, your code might not be” discussion; June gave us the JDK team admitting that the modern API doesn’t always win. Two threads on panama-dev are worth your time. The first is a scalability wall: VectorMask.toLong() and fromLong() rest on 64-bit primitives, capping masks at 64 lanes, which falls apart against ARM SVE’s ambitions reaching 2048 bits, unless the signatures change.
The second, more humble, is JMH audits showing that the Vector API still doesn’t confidently beat C2 auto-vectorization, with float-to-float conversions where the scalar loop C2 generated was leaner than the explicit Vector API version (drowning in guards and uncommon-trap paths). There’s even the counterintuitive finding that holding vector constants in static final fields costs more than building them locally inside the loop.

Speaking of Leyden, which gave us the GC-independent AOT object cache in JDK 26 (JEP 516), the project now wants AOT caching for custom class loaders. The proposal extends the AOT/CDS benefits beyond the system and platform loaders to “safe and reasonable” non-subclassed URLClassLoader instances, identifying them during training runs, recreating them in the assembly phase, and storing linked Class mirrors in the cache so that getClassLoader() resolves correctly in production.
On top of that, anything that deviates from standard URLClassLoader behavior is excluded for cache stability, which is just the usual CDS caution, but it’s a real step toward fast startup for the many frameworks that lean heavily on non-standard loading.
On the governance front: Thomas Stuefe nominated Robert Toyonaga (Red Hat and IBM) for OpenJDK Committer status on the basis of 17 non-trivial patches in HotSpot Runtime, centered on Native Memory Tracking and JDK Flight Recorder, which is exactly the diagnostics you appreciate at 2 a.m. during a production memory leak.
Two more things from the corners of language design and polyglottery. Project Amber debated erasure-based union types (Integer | Float reducing to the nearest common ancestor), a “fast path” with no JVM changes to exhaustive matching in switch without formal sealed hierarchies. The community is split on whether erasure-only convenience won’t later create friction with Valhalla’s long-term goals for specialized generics, which is a fair worry.
And in the “de-JVM-ing” genre of functional languages that gave us swc4j and WebAssembly4J last month, ClojureWasm is a from-scratch runtime in Zig and Clojure that skips both the JVM and GraalVM Native Image, targeting sub-1 MB Wasm binaries with an allocator tuned for persistent data structures.
Finally, a Quarkus cluster and a nice callback. Quarkus is moving to Vert.x 5 in version 4, reworking its reactive core and leaning on SmallRye Common I/O and a NIO.2 Zip filesystem provider to attack archive-scanning bottlenecks (the public API stays stable; internal SPIs and handler APIs will change).
On top of that, the new Quarkus Pi4J extension moves Pi4J context initialization and hardware providers to the build phase, giving CDI-injected GPIO/I2C/SPI/PWM and sub-second native startup on a Raspberry Pi, which is a credible “Java instead of Python or C++” argument for IoT (and a tidy continuation of Pi4J joining Commonhaus in March).
And here’s the promised callback: when Floci was a GitHub All-Star last month, I noted that the community wanted Quarkus DevServices integration. Markus Eisele delivered exactly that, wiring Floci in as Dev Services for S3, SSM, and SQS right into the quarkus dev loop, without LocalStack’s login-token tax. The ecosystem listens, as you can see.
Oh, and one more for the “human-readable text as a weapon” file: Ken Kousen described a delightfully malicious escalation of using property-based testing with jqwik on both sides of the prompt-injection war, namely engineers fuzzing LLMs for injection vulnerabilities with @Provide and Arbitraries, and, on the dark side, developers poisoning their own code with data-nuking payloads for when an autonomous “vibe coder” swallows them.
The lesson is unchanging and unspectacular: sandbox anything that lets an LLM touch your filesystem.
A small note to close on: 👩🏻💻 Marit van Dijk (Java Champion and Developer Advocate at JetBrains) has kicked off a new series on the IntelliJ IDEA YouTube channel, where she talks with people from the JVM community.
The first episode is a conversation with Moritz Halbritter from the Spring team about JSpecify, the standardized nullness annotations that, after being adopted in Spring Framework 7 and Spring Boot 4 (plus support in IntelliJ itself), are shifting from a curiosity into an everyday tool for null-safety in Java.
2. Release Radar

Kotlin 2.4.0
Kotlin 2.4.0 is the release where the headline feature of the last few versions stops being preview. It promotes context parameters to Stable, and the opt-in -Xcontext-parameters flag disappears, so if you have @OptIn(ExperimentalContextParameters::class) scattered around, you can clean it up. They were still experimental when I covered 2.3.20 in March, so this is the moment they move into the “put it in your public API” zone. The use case is the one that’s hit everyone: dragging a logger, a transaction handle, or a tenant ID through five layers of functions just so the deepest one can read it. The compiler injects the context as the first argument at compile time (zero runtime overhead versus a plain call), it works with suspend functions, and unlike ThreadLocal it survives on iOS and JS targets in KMP, because there’s no thread-local there to break:
// Context parameters - Stable in 2.4.0; the -Xcontext-parameters flag is gone
context(tx: DatabaseTransaction)
suspend fun saveOrder(order: Order) {
tx.persist(order) // tx is resolved from the surrounding context, not passed in
}The second genuinely pleasant quality-of-life change is explicit backing fields going Stable, collapsing that “private mutable plus public read-only” dance every Compose and StateFlow codebase is full of into a single declaration:
// Before: standard Compose/StateFlow boilerplate
private val _uiState = MutableStateFlow(UiState())
val uiState: StateFlow<UiState> = _uiState
// After (2.4.0): one declaration, explicit backing field
val uiState: StateFlow<UiState>
field = MutableStateFlow(UiState())Beyond the language there’s plenty here: kotlin.uuid.Uuid is now Stable in the common standard library (with new isSorted() / isSortedBy() checks), Kotlin/JVM can emit Java 26 bytecode with annotations in metadata enabled by default, and Kotlin/Native gains Swift Package Manager dependencies via a swiftPMDependencies block, closing out the CocoaPods-replacement story I flagged in March, plus Swift export (now in Alpha) mapping suspend functions to Swift async and Flow to AsyncSequence.
Kotlin/Wasm incremental compilation is Stable and on by default, and experimental WebAssembly Component Model support lands for cross-language Wasm interop. One administrative morsel worth knowing: each kotlin-stdlib release line on the JVM now gets an 18-month security support window with backported fixes. Compatible with Gradle 9.5.0.
Kotlin Toolchain 0.11 (formerly Amper)
Kotlin Toolchain 0.11 (covered by Joffrey Bion ) is the release where Amper stops being Amper. If you missed the KotlinConf keynote, the headline goes like this: Amper grew into Kotlin Toolchain and jumped straight to Alpha, which in JetBrains-speak means “we’re committing to maintaining this, so test away.”
TLDR:

At the heart of the change is a single kotlin command, conceived as one entry point into all of Kotlin: with it you create a project, build, run, test, package, and publish, and in the future also format your code and generate documentation. No build-tool decisions up front, no plugin wiring before you write your first line. The CLI can now be installed globally (sdk install kotlintoolchain) and called from outside the project directory, with the wrapper still pulling the version matched to a given repo. The long-awaited publishing of JVM libraries to Maven, including Maven Central, also enters preview, where the Toolchain takes on the whole tedious ritual (sources and javadoc JARs, PGP signatures, POM metadata, checksums) and reduces a release to kotlin publish mavenCentral, or with publishingMode: auto to a fully automated pipeline.
My favorite little detail, very on-theme for this edition: the new generated section in plugin.yaml, which registers generated sources, resources, classes, and cinterop definitions in one readable place, designed so these artifacts are recognizable at a glance not only to humans but also to AI agents and other tools. This is exactly the same thinking as JobRunr’s context7.json (more on that shortly), just built straight into the plugin model. The rest, for extension authors, is new checks and commands declarations (with the kotlin check and kotlin do commands), public entry points to tasks that are private by default, and a few fresh references like ${project.rootDir}.
One migration gotcha to close on: you can’t upgrade automatically from old Amper - the wrappers have to be swapped manually via kotlin update --create.
Spring AI 2.0
The third heavyweight release: Spring AI 2.0 reached GA, and being Spring, it came with a small cloud of accompanying articles. The core is the exit from experimental to stable: ChatModel, EmbeddingModel, and VectorStore are now a provider-neutral abstraction layer, so switching between OpenAI, Anthropic, and a local Ollama stops being a refactor, while the polished VectorStore abstractions and automatic metadata filtering aim squarely at cutting RAG boilerplate.
On that base, two newer things stand out: SelfCorrectingStructuredOutputConverter, which closes the feedback loop around malformed JSON (when the output fails schema validation, it packs the original instruction, the bad output, and the exception into a new prompt and retries up to a configurable retryCount)...

…and a composable tool-calling API, which replaces imperative tool binding with declarative ToolCallback beans, automating schema generation and threading state through ToolContext.
Craig Walls also documents the edges, namely ElevenLabs’ SpeechModel for streamed TTS and the Embabel abstraction layered over Spring AI and LangChain4j. Spring AI didn’t arrive alone, by the way: in the same window Spring Boot 4.1.0 shipped (more in the Radar below).
Spring Boot 4.1.0 & Spring Data 2026.0.0
Spring Boot 4.1.0 shipped alongside Spring AI 2.0 GA and is a fairly routine bump. For me the strongest point is first-class Spring gRPC support, now with reference documentation and a @GrpcAdvice annotation for centralized gRPC exception handling, which finally gives gRPC the same autoconfigured “convention over configuration” treatment REST has enjoyed for a decade.
On the security side, both reactive and blocking HTTP clients can be equipped with an InetAddressFilter that blocks outbound requests to specific addresses, a built-in hardening primitive against SSRF that you’d otherwise write by hand or pull from a library. The observability story keeps deepening (updated OpenTelemetry support, including OTel SDK environment variables, plus KafkaListenerObservationConvention beans applied automatically to the container factory), there’s file rotation support for Log4j, context now propagates automatically to @Async methods on separate threads, and a new @AutoConfigureWebServer slice annotation helps tests that need a real embedded server.
On the cleanup side: everything deprecated in 4.0 is removed, the layertools jar mode is gone, the withdrawn Apache Derby integration is deprecated (migrate to H2 or HSQL), and LiveReload in Devtools is deprecated with no replacement. It also rolls up all the fixes from 4.0.7. Treat it and Spring Data 2026.0.0 as one coordinated upgrade.
Gradle 9.6.0
Gradle 9.6.0 is a minor update. It improves Configuration Cache hit rate by precisely tracking project properties supplied via the org.gradle.project.<name> system properties and ORG_GRADLE_PROJECT_<name> environment variables: previously, changing any such value invalidated the cache, even if that property was never read during configuration.
There’s also a neat fix with an infrastructural flavor that fits perfectly with Gradle’s own AWS migration story (worth reading the writeup of the AWS-powered build engine behind 200 million plugin downloads a month): Gradle’s log files generated a large volume of I/O, and on network block storage like AWS EBS that triggered IOPS throttling and real slowdowns. 9.6.0 reworks that implementation, delivering significant gains on low-IOPS storage.
Looking toward Gradle 10, both implicit and explicit (findProperty(), property(), hasProperty()) lookups resolved from parent projects now emit deprecation warnings, with an opt-in NO_IMPLICIT_LOOKUP_IN_PARENT_PROJECTS preview to adopt the future behavior early, and lazy property types relax the requirement for an exact type match in the Groovy DSL.
Helidon 4.5.0
Helidon 4.5.0 is a release on the 4.x line following the solid LTS 4.4 (the one that brought Java Verified Portfolio support, LangChain4j agentic patterns, MCP 1.1, and the plan to rename the next line to Helidon 27 in step with JDK 27). 4.5.0 itself delivers hardened value encryption for shared-secret configuration in Helidon Config, closes out the project’s effort around API stability with dedicated stability annotations, and carries the usual fixes and dependency updates. Java 21 remains the floor, Java 25 recommended.
JobRunr 8.7.0
JobRunr 8.7.0 (announced by Nicholas D’hondt) makes the library noticeably easier to embed.
And since ClawRunr is built on it, “easier to embed” now reads as “a better foundation for the agentic JVM stack.”
The headline is lazy server initialization: JobRunr ships full starters for Spring, Quarkus, and Micronaut, but everyone else had to fight a greedy Fluent API that started the Background Job Server and Dashboard the moment you called useBackgroundJobServer().
Now both start on initialize(), the new getBackgroundJobServer() / getDashboardWebServer() accessors hand you the servers to manage their lifecycle, and the old configuration-ordering constraints disappear (builder calls can go in any order). On top of that: the dashboard adopts the system color scheme by default and links directly to each release’s release notes, and Jackson3JsonMapper now deserializes common collection types (List.of(...), Set.of(...), HashMap, and friends) out of the box.
My favorite little detail, very on-theme for this edition: the repo added a context7.json so that AI coding assistants pull the exact, up-to-date JobRunr configuration.
JobRunr Pro adds batch continuations created from within a batch, plus a round of dashboard security hardening (the license key validated server-side, authorization enforced on Server-Sent Events streams, stricter API key checks for the Multi-Cluster Dashboard).
A2A Java SDK 1.0.0
The A2A Java SDK reached GA at 1.0.0, and it matters, because Agent2Agent (an open standard under the Linux Foundation) is a protocol that lets agents from any language, framework, or vendor discover each other’s capabilities, delegate tasks, and collaborate over JSON-RPC, gRPC, or HTTP+JSON. Getting to 1.0 required a real spec-conformant transition: AgentCard now advertises a supportedInterfaces list instead of separate url/transport fields, kind type discriminators are gone, the entire spec module was modernized onto Java records, and JSpecify null-safety annotations were adopted throughout - the Maven coordinates also moved to org.a2aproject.sdk on Maven Central.
The 1.0.0 release itself adds a new integration test kit, a Quarkus-based agent for testing interoperability between SDKs, and exposes HTTP response headers through the A2AHttpResponse interface and A2AClientHTTPError.
Following it comes A2A SDK for Jakarta Servers 1.0.0-RC1 (WildFly integration, under org.wildfly.a2a), Both ADK for Java and the Spring AI A2A integration already use this SDK, so it’s effectively the interop layer for the agentic ecosystem this whole edition is circling.
3. GitHub All-Stars

June was a strong month for the “zero-config Java” itch and the “look inside the JAR” genre. Four picks.
jhostty - “Probably the Most Portable Terminal in the World,” in One File
Here’s JBang itself reminding everyone why it still sets the bar. jhostty, from Max Rydahl Andersen is a full-featured terminal emulator in a single Java file (~940 lines) on Java 25, embedding the Ghostty engine as a hardware-accelerated JavaFX control via GhosttyFX (0.1.169) by vlaaad. No build system, no IDE, no project setup, just JBang and one file: jbang jhostty@maxandersen (JBang pulls Java 25 automatically).
The feature list is absurdly complete for a script the author says was written “in a few hours a Sunday morning”: freely nested horizontal and vertical splits, ten themes switchable on the fly (the whole UI adapts, context menus and split dividers included), independent per-pane zoom (keyboard, scroll wheel, trackpad pinch, with the percentage in the title bar), every system font (terminal favorites like JetBrains Mono and Fira Code listed first), drag-and-drop of files and URLs, clickable link detection, shell integration (⌘F/Ctrl+F), and a native macOS menu bar.
A perfect “signal” project for how far GhosttyFX and JBang have come: native-quality, low-latency desktop UI tucked into one file you launch with a single command.
Nuts - “The Package Manager Java Never Had”

After nine years of development, Nuts (Network Unified Tool System) reached a round 1.0.0.0, and its author describes it without false modesty as “the package manager Java never had.” The idea: manage dependencies at runtime, not build time, by reading Maven descriptors directly and solving the perennial fat-JAR problem at the source, since only the JARs and dependencies (and, for native binaries, only the assets) actually needed land on the target machine.
Nuts requires no custom descriptors or build tool and doesn’t change classloading behavior: it just resolves the dependency tree, builds the classpath, and runs the app. What makes it distinctive is a shared workspace across all applications, the ability to keep multiple versions of the same app side by side, and automatic provisioning of the required JDK, so nuts install myapp pulls the latest version along with its dependencies and runtime while optimizing network and disk. The author offers the best analogy himself: it’s npm/nvm or uv, but for the Java ecosystem.
The ecosystem is still firmly in container-and-fat-JAR territory, so approach it as a thought-provoking alternative rather than a Monday-morning migration, but the nine-year gestation and a 1.0 milestone show.
Jet - A Turnkey Java HTTP Client and Server, Without the Kotlin Runtime
Jet, by Jacob Peterson, is, in its own words, “a simple, lightweight, modern, turnkey Java web client and server library” (Java 25, MIT-licensed, already on Maven Central at 3.3.0). The contrarian “Java-first” pitch: Javalin-style fluent DX without the mandatory kotlin-stdlib dependency. The architecture is modular: Common provides native HTTP header models and data structures (something the author flags competitors lack), URL building, and I/O utilities; Server is JetServer.Builder, a Handle/Handler/Router/Route system, session support, and, nicely, built-in Let’s Encrypt certificates; on top of that sit a dedicated OpenAPI annotations module and a Gradle plugin that generates the spec (with a README section arguing why a plugin rather than an annotation processor). A Client module is on the roadmap. A detail very on-theme for this edition: the README has its own “Personal Note About AI” section where the author addresses AI’s role in building the library.
Early days (~5 stars), but the niche for Java purists who find Spring Boot overkill and Javalin’s Kotlin roots a dealbreaker is real.
Marshal - Behavioral Supply-Chain Security for JVM Dependencies
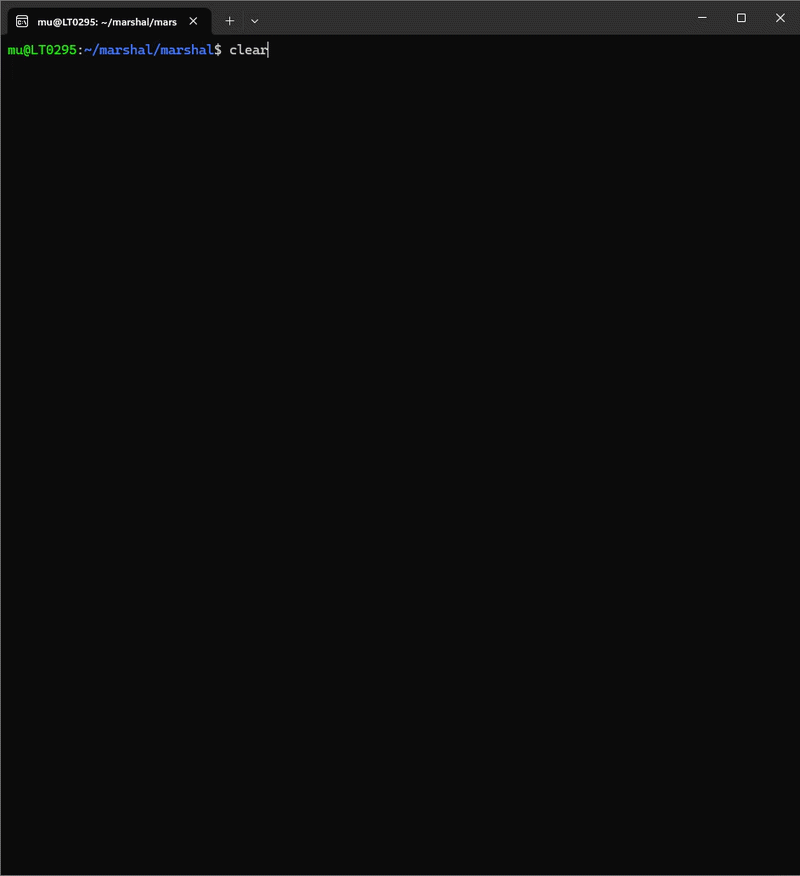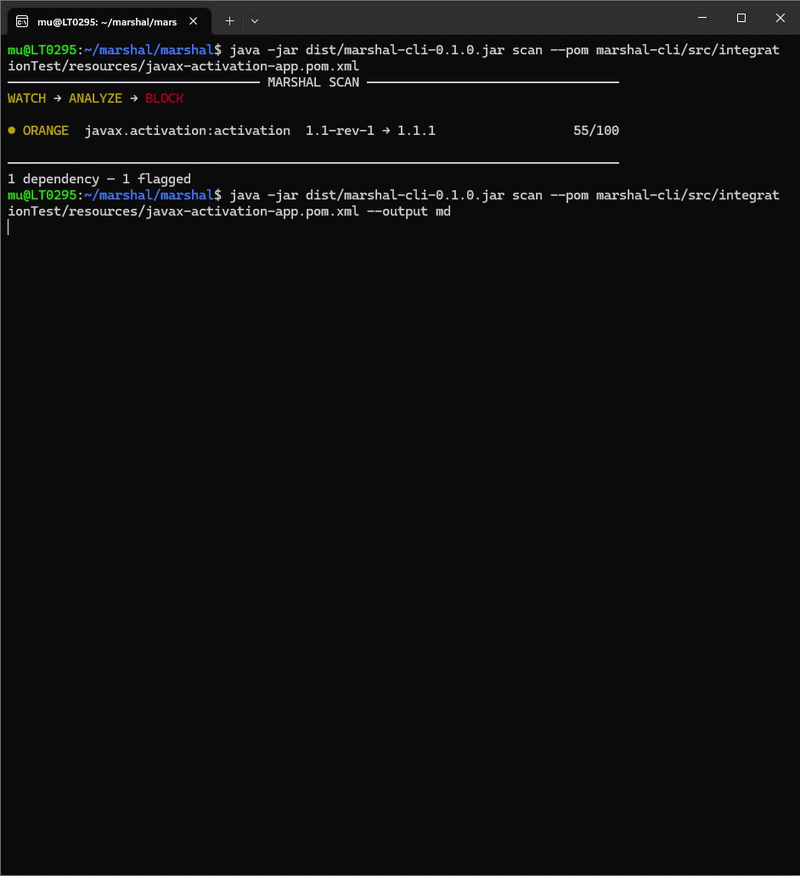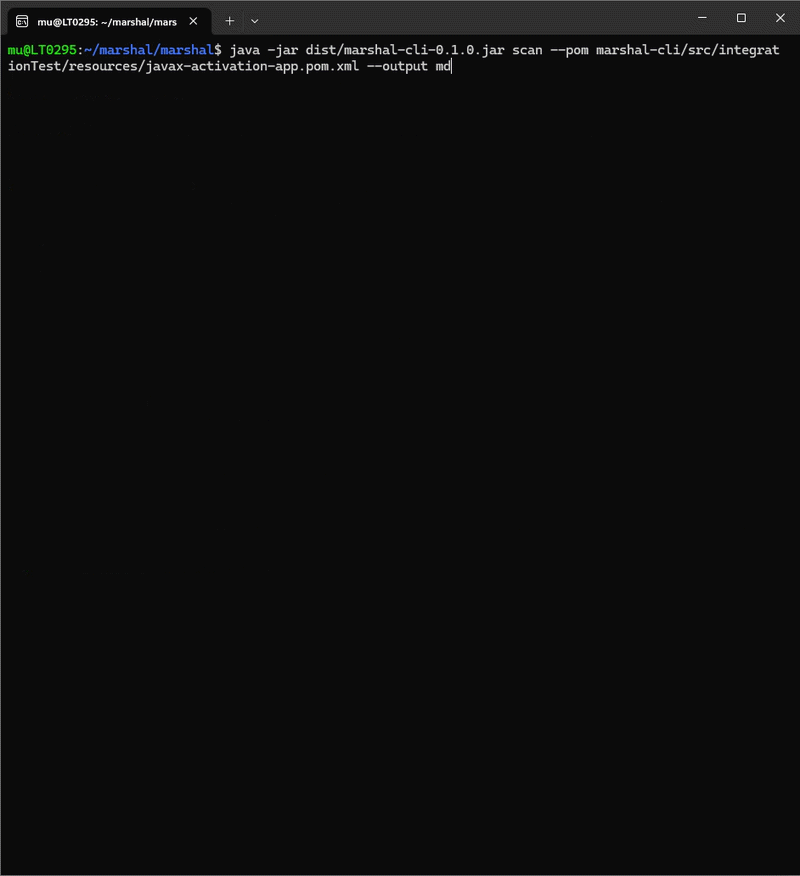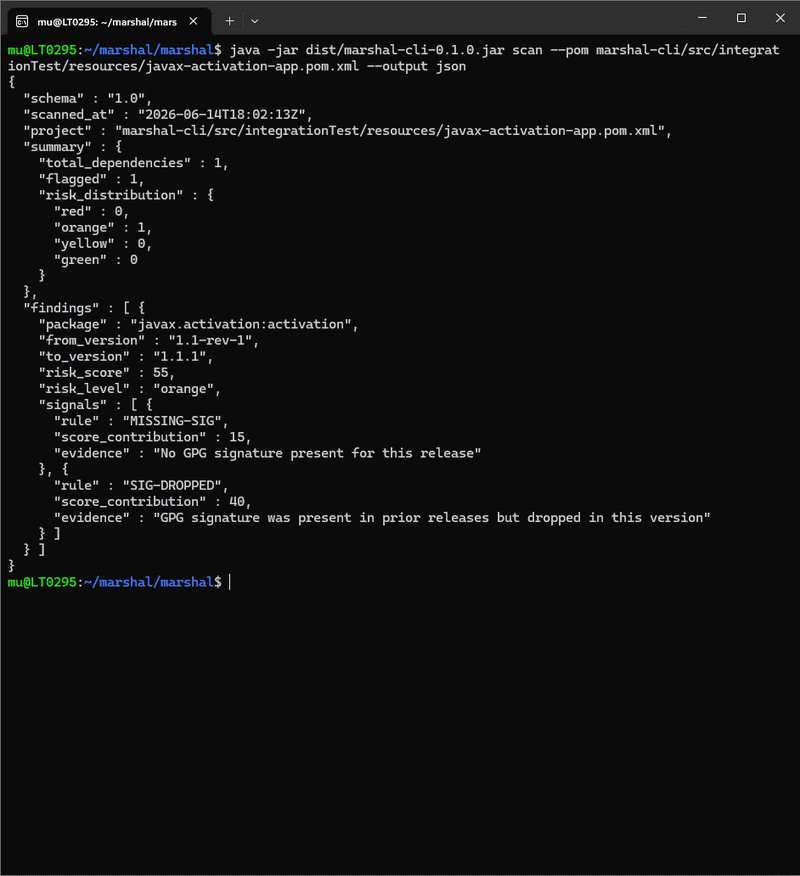
Marshal does behavioral supply-chain security for JVM dependencies, with a very concrete model: it watches how packages change on Maven Central and scores every update on a 0-100 risk scale. A maintainer swap, a dropped GPG signature between versions, a sudden jump in dependency count, these all surface the day a version is published, long before a CVE exists.
It plugs in as a GitHub Action on pull requests touching pom.xml or build.gradle(.kts): it detects the build tool, scans the dependency changes, and comments on the PR with a finding (e.g. “javax.activation:activation, ORANGE 55/100, GPG signature dropped between versions”), and with threshold: red plus a required check it can block the merge. Crucially, if dependencies can’t be resolved (because the build fails), the check fails rather than passing silently, on the principle that a scanner that can’t analyze your project shouldn’t report it as clean.
It targets teams that auto-merge dependency updates directly. Still early (v0.1.0, a handful of stars), but the direction, catching the intentional backdoors that CVE-scanning alone misses, is the right one.
PS: And yes, I’m finally accepting that the JVM’s agentic ecosystem has coalesced enough that I have to stop joking about writing that overview and just write it. Consider this your warning. 😉
PS2: JVM Weekly landed at the top of Hacker News last Friday. Wow! Thank you all ❤️
PS3: From the “JVM Weekly in strange places” series - Stansted Express.