

The Hitchhiker’s Guide to AI in the Java Galaxy - JVM Weekly vol. 148
One theme this week, but explored from (literally) every angle 😁


It all started so innocently - with last week’s benchmark on energy consumption across programming languages. The data is genuinely impressive and confirms what many of us have long sensed: modern Java can be ruthlessly efficient. But as soon as you dig into the details, it becomes clear that “AI Applications” are much more than a CPU prime-number test. Real-world workloads are about memory bandwidth, I/O, linear algebra… and, above all, GPUs.
That’s why, in this edition, I’m turning the dial to “real world.” We’ll talk about DJL and Deeplearning4j, TornadoVM and Babylon/HAT, GraalPy (with a brief Sulong cameo), and for dessert: how Spring AI and Quarkus + LangChain4j meet around MCP… plus IBM’s new Coding IDE. That’s what happens when I have a 13-hour flight and in-flight internet 😁.
TLDR: Quoting Paul Sandoz from Devoxx Be (which I’m not able to attend this year 😢):

So without further ado - because this won’t be a short read - let’s dive in.

We’ll start with a small erratum. As I mentioned, the spark for this piece was the publication Measuring Energy Consumption in Programming Languages for AI Applications. I still think Miro’s paper is impressive methodologically - rigorous, automated energy measurements, 15 iterations per test, and accounting for idle consumption is solid work - and the results strongly confirm what many of us have felt for a long time: the modern Java platform is a master of efficiency. The data makes it clear how it trounces interpreted languages like Python in cost and performance, especially for parallelized tasks on modern multicore hardware.
However - and this is the crucial “but” that made me remove “from AI Applications” from the title of the latest JVM Weekly after publishing - while the conclusions about CPU-bound performance are valid, the chosen benchmark - the prime-checking algorithm - is a fundamentally flawed model for modern AI workloads, even if the goal is to measure energy. First, artificial intelligence is primarily about processing huge datasets, not raw compute speed. The benchmark misses critical bottlenecks like I/O operations and memory bandwidth, which are the real choke points. In addition, AI workloads are dominated by floating-point linear algebra operations (mainly matrix multiplication), not simple integer arithmetic. Third, memory-access patterns in AI models are far more complex than a linear array walk. But the biggest omission is the GPU. Modern AI training and inference happen on graphics processors. By limiting tests to the CPU, the authors measure a configuration that’s becoming less relevant to the field, making conclusions about “AI Applications” incomplete.
That said, it’s not the benchmark’s fault - the topic is just extremely complex. So today’s edition is devoted to how Java maps onto modern AI challenges.

Modern ML workflows on the JVM (we’ll get to LLM integration in a moment, be patient) now follows two mature paths: first, integration with the Python ecosystem via Java adapters; and second, a native, “pure-JVM” stack for training and inference. Each offers different levers - and different land mines.
The first path is a native JVM stack (no Python). For many companies, choosing a native AI stack on the JVM is a strategic decision... with concrete trade-offs. On one hand, developers face challenges like a smaller ecosystem (however, growing like hell, as you will see in the moment). In return, you gain major advantages in enterprise environments like: full architectural consistency, where the entire solution lives in one ecosystem - simplifying security management, dependency control, and audits.

The core are libraries like the DL4J/ND4J/SameDiff trio - Java’s answer to NumPy and TensorFlow - providing efficient n-dimensional array operations (ND4J) and a complete framework for building and training neural networks (DL4J), often integrated with Big Data systems. Complementing classic ML tasks like classification or regression is also Oracle’s Tribuo, which emphasizes experiment repeatability and data provenance.
The other is pragmatic integration with the Python ecosystem - e.g., using DJL as a bridge to PyTorch, TensorFlow, or ONNX - which lets a JVM application leverage mature models without rewriting business logic in Java. Cause as we know, everybody is using Python.

It does, however, require wrangling the native layer: CUDA dependencies, ABI and driver version compatibility, multi-platform packaging, keeping behavior consistent across backends, and smooth “DevOps × DataOps” (container builds, image sizes, cold starts).
In practice, that means DJL tying Java to models trained in Python, with inference via ONNX Runtime - the ability to swap backends without touching business logic and plugging into existing MLOps pipelines while preserving the JVM’s production stability.
Now that we’ve brought up Python - what about GraalPy?

The current state of GraalPy (a production-ready Python implementation running on GraalVM) can be described as mature… yet still highly specialized. The project has reached stability and is ready for production use, offering compatibility with the Python 3 API. Its strength rests on two pillars: performance for long-running, compute-intensive workloads written in pure Python - where its advanced JIT can significantly outperform standard CPython - and seamless, low-overhead integration with the Java ecosystem, letting you invoke Python libraries with ease.
try (Context ctx = Context.newBuilder(”python”)
.allowAllAccess(true)
.build()) {
ctx.getPolyglotBindings().putMember(”greeter”, new Greeter());
ctx.eval(”python”, “”
+ “import polyglot\n”
+ “greeter = polyglot.import_value(’greeter’)\n”
+ “msg = greeter.greet(’Artur’)\n”
+ “result = msg.upper()”);
// Read a Python variable back in Java
String result = ctx.getBindings(”python”).getMember(”result”).asString();
System.out.println(result); // -> Hi, ARTUR!
}
}That second pillar, combined with the unique ability to compile applications into standalone, instant-startup binaries (i.e. the JDK’s well-known Native Image), positions GraalPy as a powerful tool for extending existing Java systems and deploying in cloud architectures. But...
Despite these advantages, GraalPy faces a fundamental challenge that defines its current limitations: performance at the boundary with native extensions. Wherever Pandas, NumPy, and SciPy reign, there’s a cost to crossing between managed and native worlds - one that’s hard to “optimize away” without trade-offs. This is where Sulong comes in - a project for running LLVM code on GraalVM. Sulong—the LLVM runtime used to run such extensions - enables broad compatibility, but it isn’t a universal performance fix: crossing between managed and native code can dominate runtime in some workloads. In recent releases, GraalPy introduced a C-API implementation with fully native execution and options to build against the system toolchain, which can improve native-heavy paths while acknowledging trade-offs for boundary-heavy code. That approach improves compatibility and predictability while accepting that some boundary-heavy workloads won’t see “magical” speedups.

In the context of AI, GraalPy’s status is therefore nuanced. On the one hand, its primary goal is support for key AI and data-science libraries like PyTorch, SciPy, Pandas, and Hugging Face Transformers - and that goal is actively pursued (just follow the release notes). This makes it attractive for Java-centric organizations that want to integrate advanced AI capabilities without leaving their technology ecosystem. However, because of the performance considerations around C extensions, GraalPy is not currently the optimal choice for typical, compute-heavy AI tasks that depend heavily on libraries like Pandas. In the AI world, this positions GraalPy not as a CPython “killer” for training and raw numerics, but as an integration bridge for JVM-first organizations.
The ideal scenario is embedding ready-made models in the same process as your Java business logic - fewer moving parts, fewer network hops, simpler operations. Where heavy Pandas ETL or accelerator-driven training is needed, it’s more sensible to run standard Python (CPython) alongside and split responsibilities via a simple service contract.
Closing the hardware gap: Java’s pursuit of the GPU
Okay, since Python isn’t a perfect fit, let’s return to the second path—pure Java. Today’s AI demands smooth access to hardware accelerators, which has historically been Java’s biggest weakness.
Before we dive into modern solutions, it’s worth recalling Project Sumatra—one of the first serious attempts to “bring” GPUs into the Java world by automatically offloading Java 8 lambdas and streams to accelerators (using early Graal). Sumatra never reached broad production use, but it mapped the minefield brilliantly: data transfer costs between memories, driver variability, differences in memory models, and the tough trade-off between portability and performance.
Sumatra’s lessons proved invaluable - they shaped today’s approaches, where instead of “magical” offload we favor explicit, controlled programming models and tighter JVM integration.
Building on those experiences, two current pillars have emerged: Project Babylon and TornadoVM, which directly tackle Java’s last barrier in AI - access to accelerators.
Project Babylon is developed under OpenJDK and treated as part of the language and JVM’s official evolution. Its key deliverable is the concept of Code Reflection: a unified API for introspecting and transforming code at an intermediate representation level, rather than “after the fact” at bytecode. In practice, that means safer, more predictable metaprogramming (compared to ad-hoc ASM, agents, or annotation-only tricks), generating specialized function variants for specific data or hardware, and the ability to export fragments of logic to other execution forms.
PS: Still waiting for full JVMLS playlist guys 😊
That’s why Code Reflection is crucial for GPUs: it gives library authors access to a high-level, semantic representation of a function fragment before it becomes bytecode. You can check purity and side effects, recognize parallel patterns (map/reduce/stencil), determine memory layout and aliasing, and then safely “lower” that fragment into a kernel (e.g., SPIR-V/PTX) along with a data-transfer plan and work-distribution heuristics. In practice, optimizations for a given card, tensor sizes, or vectorization are produced automatically and predictably, with the option to fall back to the CPU - and to debug and test within the same Java code.
HAT (Heterogeneous Accelerator Toolkit) naturally follows from this style of code reflection: it lets you write kernels in “plain” Java (with clearly defined constraints) and transpile them into code executable on heterogeneous devices. From a developer’s perspective, it’s a single, coherent programming model (Java types, control flow, collections/buffers), while under the hood a translation layer picks the right backend for the GPU/accelerator and handles data transfers and work scheduling. One language and one tool ecosystem (profilers, tests, CI/CD) while still accelerating tasks like vectorization, image processing, numerical algorithms, or selected ML operations - without JNI, hand-rolled C++, or kernels in foreign DSLs.
For architects, this is a strong strategic signal: investing in Java for AI and hardware-accelerated computing aligns with the platform’s roadmap, not a side path. In practice, it’s worth planning an abstraction layer for numerical ops today (to “plug in” HAT where it pays off), avoiding hard dependencies on native libraries, separating control code from compute kernels, and providing CPU fallbacks for portability.
While HAT is still in progress, we already have TornadoVM, which has appeared often in this newsletter. TornadoVM is a production-grade “JIT accelerator” that runs today as an add-on over the JVM (via JVMCI), compiling Java bytecode on the fly to OpenCL/PTX/SPIR-V and executing on GPU/FPGA/CPU-SIMD. Developers annotate existing loops (@Parallel/@Reduce) or define tasks in a Task Graph; the runtime chooses the device, manages transfers (keep-on-device, reuse), and provides automatic CPU fallback. The effect: fast, practical speedups on real workloads (including Llama2/Llama3 inference, vector/image processing) without JNI and without rewriting to CUDA - while keeping your existing CI/CD and tests.
If you have three hours, you can watch a three hours video from the this year Devoxx, happening in the Antwerp right now 😁. I dare you not to!
The programming model is intentionally pragmatic. You get APIs for defining tasks and task graphs that indicate what should be moved to the accelerator and how to structure the computation steps.
Operationally, three elements matter: device selection, memory management, and safe fallbacks. TornadoVM offers runtime backend/device selection (e.g., NVIDIA via PTX, Intel/AMD via OpenCL or SPIR-V), lets you pin task graphs to specific GPUs, and keep data on the card between calls to minimize PCIe transfer costs. When a fragment isn’t suitable for acceleration (due to unsupported language constructs, too-small datasets, or heavy branching), execution can fall back to the CPU with no change to higher-level code.
That’s why, in AI use cases, TornadoVM acts as a booster for the “heavy” numeric blocks: matrix-vector ops, convolutions, attention operations, softmaxes, quant-dequant - it can pick the fragments that are truly worth running on the GPU. Good examples - like GPULlama3.java or llama2.tornadovm.java - show you can accelerate real inference paths without leaving the Java ecosystem, which simplifies integration with existing architecture (telemetry, security, resource management).
Sidequest: Valhalla and Memory-Management
Speaking of long journeys, the community is buzzing because the holy grail of JVM optimization - Project Valhalla - has finally taken a monumental step forward. After more than a decade of work, the first major JEP from this project has been officially proposed: JEP 401: Value Classes and Objects (Preview).
It addresses a fundamental problem in Java: the memory and performance overhead of objects. JEP 401 introduces “value classes”—a special kind of class that gives up object identity in exchange for massive performance benefits. It’s the realization of “write like a class, behave like an int.” The main advantage is memory “flattening.” Without a header and pointer, the JVM can lay out values in memory as densely as primitives - for example, arrays become one continuous block of data. This drastically reduces memory usage, improves cache locality, and lowers pressure on the garbage collector. For AI workloads operating on millions of vectors and tensors, this is a complete game-changer. While it’s a giant milestone, it’s still the beginning: JEP 401 is currently in “preview” and won’t make JDK 25, but there’s hope for JDK 26 or 27.
Practically speaking, Valhalla is a turbo-boost for memory and CPU across the JVM: value classes let you “flatten” complex data structures in arrays and collections, improving locality of reference. In addition, with Project Panama it becomes simpler and faster to map such flattened layouts to off-heap memory and native libraries, and tools like Babylon/HAT will find it easier to generate GPU/TPU kernels because the data has a predictable, dense layout. Sum of sums: the same Java code will sit closer to the metal - without losing type safety or language ergonomics.
Stepping off the Virtual Machine - What about LLM Integration?
In reality, most of us won’t be running large models locally - even Python folks don’t do that day-to-day in production. That’s why in 2025 Java has two equally strong paths into LLM-based applications: Spring AI and the nimble duo Quarkus + LangChain4j.
Spring AI brings the spirit of Spring to the world of models: familiar idioms, auto-configuration, integration with Spring Boot 3, and full observability via Micrometer. The keys are unified clients (Chat/Embedding), “structured outputs” mapped directly to Java types, and ready-made RAG blocks—from document ETL to a VectorStore with metadata filtering. Developers “think in Spring,” so switching an LLM provider or vector database is usually configuration, not a code refactor—just like swapping relational databases.
Quarkus with LangChain4j takes a different route: minimal overhead, fast startup, low memory use, and strong “developer joy.” Declarative AI services via CDI strip boilerplate to the bone, while hot reload, Dev UI, and Dev Services accelerate prototyping. A natural complement is GraalVM native compilation, which delivers millisecond cold starts and great efficiency on Kubernetes and serverless. An extra perk is integration with Jlama - a pure-Java inference engine for smaller models - letting you run AI in the same process as your app, which benefits privacy and latency.
If you’re deeply invested in the Spring ecosystem, Spring AI is a safe, predictable step forward. If cloud costs, microservice scale, rapid iteration, and tapping into the dynamic LangChain ecosystem are paramount, Quarkus + LangChain4j is evolving even faster—and fits the overall direction of travel.
Most importantly, both paths are now “production-ready,” with mature support for RAG, function calling/agents, and integrations with popular vector stores. Crucially, both converge on support for a rising standard that’s revolutionizing how AI agents talk to external tools - the Model Context Protocol. At its core, MCP is an open protocol that acts as a universal intermediary language between language models and any application. Instead of building bespoke, often complex integrations for each tool, MCP standardizes communication, allowing an AI agent to dynamically discover available functions and safely invoke them in a structured way.
In the Spring AI ecosystem, this support takes a characteristically Spring approach - automatically exposing existing beans as tools that agents can safely call. Meanwhile, the Quarkus + LangChain4j duo offers a dedicated extension that quickly turns CDI services into a full-fledged, efficient MCP server - perfectly aligned with the philosophy of minimal code and maximum productivity.
In both cases, developers get a powerful mechanism for exposing business logic to language models in a standardized way. And support for MCP on the JVM doesn’t stop with these two frameworks.
The broader MCP landscape for Java - connecting the ecosystem for agents

Java developers are moving fast to explore MCP’s possibilities. At the front of the pack are projects like quarkus-mcp-server which, leveraging Quarkus, provide ready-to-use MCP servers to interact with resources as varied as databases via JDBC or the local file system. Imagine issuing natural-language commands to search files in your home directory or query a database without writing a single line of SQL.
One of MCP’s most exciting aspects is the simplicfication of access to advanced tools. Projects like the Java MCP Server Config Generator turn complex configuration steps into simple, intuitive wizards, enabling even those without deep technical knowledge to spin up their own server. This is a fundamental shift - lowering the barrier to entry and opening the door to new, creative uses. Instead of spending hours on setup, developers can focus on what matters: business logic and building valuable AI interactions.
MCP’s potential goes far beyond typical business apps. It’s pushing into developer tooling and diagnostics. Examples include WildFly MCP - managing an application server through conversation - or JVM Diagnostics MCP, which turns analysis and debugging into an interactive dialog. It’s a glimpse of a future where complex tasks like heap-dump analysis or performance monitoring become far simpler and more intuitive. Thanks to MCP, instead of sifting through logs, we’ll be able to simply “ask” our application what’s going on.
And while we’re on developer tools, we can’t skip the delightfully simple javadocs.dev by James Ward. This service - a lightweight frontend over Maven Central documentation - has just gained its own MCP server. What does that mean in practice? No more relying on outdated LLM knowledge of Java libraries! Instead of manually searching docs, an AI agent can directly query javadocs.dev/mcp for a class description, method signatures, or API usage examples, receiving structured and - crucially - up-to-date answers. It’s a seemingly small tweak that’s actually a huge step toward code assistants grounded in facts rather than “hallucinations.”
Migration Tools
Another increasingly popular use case is migrating large amounts of code. In Java’s world of automated modernization, the discussion almost has to start with OpenRewrite by Moderne . This open-source heavyweight, powered by precise “recipes” and operating directly on the AST, has become the de facto industry standard. Its strength lies in surgical precision and a vast community-driven library of transforms - covering everything from JDK upgrades to patching critical vulnerabilities across entire portfolios. It’s the foundation of modern refactoring - but the arena is getting crowded as major players enter with powerful solutions.
What if, instead of selecting and running pre-baked recipes, we could simply describe a migration problem in natural language? That’s the vision GitHub is delivering with tools like GitHub Copilot app modernization. Rather than focusing on single transforms, Copilot takes a holistic approach. A developer can open an issue that says, “Migrate this project from Java 11 and Spring Boot 2.7 to Java 17 and Spring Boot 3.1,” and Copilot will produce a plan, propose code and config changes, and even run tests to verify the migration. It’s a paradigm shift - from programmatic control to an intelligent dialog with an AI assistant.
While GitHub targets the developer’s daily experience, Amazon has stepped in with Amazon Q Code Transformation. Tailored for large enterprises and deeply integrated with AWS, it focuses on high-value, concrete migrations—flagship example: upgrading applications from Java 8 or 11 to 17. Amazon Q automatically analyzes source code, identifies outdated dependencies, replaces them, and makes the necessary refactors to be compatible with the new environment.
Of course, it’s worth noting that in practice both of these tools rely on OpenRewrite under the hood to perform many of their migrations.

Naturally, Oracle - the steward of Java- is in the picture too, with a somewhat different approach focused on deep analysis before migration. Tools like Java Management Service (JMS) Migration Analysis don’t automatically rewrite code. Instead, they conduct a thorough audit - scanning for deprecated APIs, problematic constructs, and potential compatibility issues - just the thing to feed into an AI-assisted prompt context.

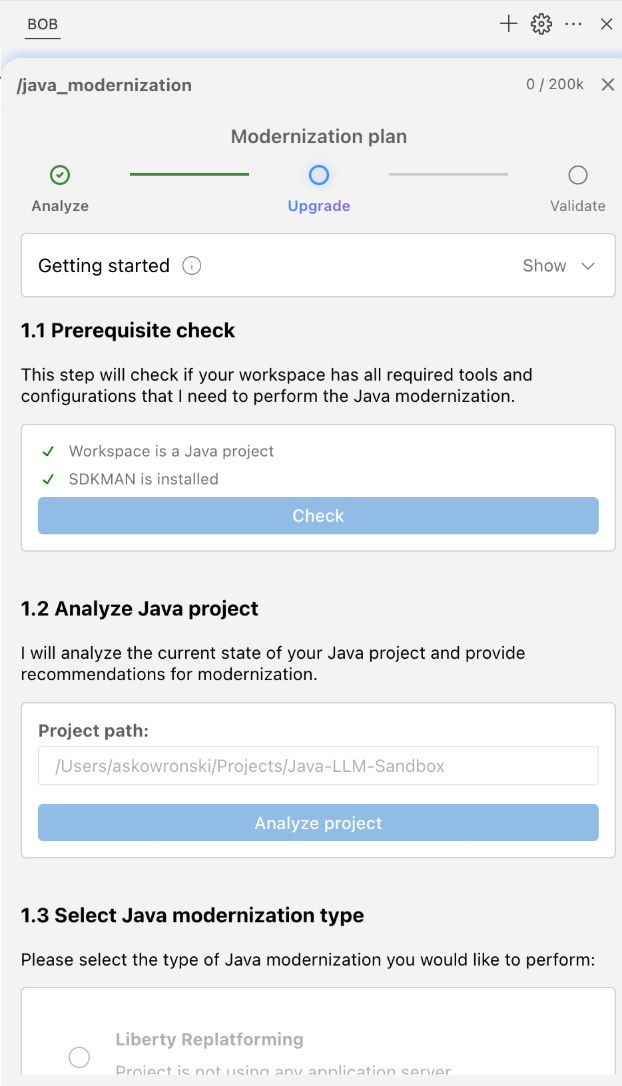
Finally, IBM (for those who missed that - the company recently merged RedHat Java division is now responsible for e.g. Quarkus) has announced a new initiative: Project Bob, a new IDE based on Visual Studio Code designed to act as an intelligent partner for developers.

Like Cursor, Bob can decompose complex tasks - such as modernizing an entire application - into smaller, coordinated steps. It understands project context and organizational standards, allowing engineers to focus on more strategic work.
Interestingly, it’s the first tool of its kind to treat Java as a first-class citizen. For Java developers, Project Bob delivers tangible benefits by automating the most time-consuming tasks. The tool includes specialized, ready-made flows that speed modernization - migrating to newer Java versions or updating frameworks like Spring. It also automates daily chores such as generating unit tests, writing boilerplate, and managing dependencies. There’s built-in security scanning too, analyzing code in real time and suggesting fixes for early removal of potential vulnerabilities. Everything is using Anthropic models, running on Sonnet.
The project has a waitlist, but I had the chance to play with Bob in its EA version before the official launch. Its plugin approach reminds me of the Cline/Roocode philosophy - in a good way. In typical migration scenarios, the assistant performs surprisingly well - I tested it on several projects - though it’s important to note that it requires Maven or Gradle (pure “vanilla Java” won’t migrate, at least so far). Under the hood it uses OpenRewrite - just like Amazon Q and GitHub Copilot Migrator - which I think is a sensible choice.
Overall, the tool works very well and captures the modernization intent. The UX still has a few early-stage rough edges, but the interface is pleasant, and the migration wizard finally gives me, as a Java developer, the feeling that in augmented-coding tools I’m no longer a second-class citizen in a Python-centric world.
I definitely recommend joining the waitlist and giving it a try.
PS: When you search for it online, note that “Bob” isn’t a new name for IBM - it comes from “Better Object Builder,” an earlier open-source tool appreciated for improving the build process on IBM platforms. The new Project Bob continues that philosophy, bringing the idea of boosting developer productivity into the AI era... and clash with the old one in SEO results.
Somebody just like to make their live harder… and more expensive 😁

Well, I let myself get a bit provoked - but remember, I had a 13-hour flight to write this (and I still managed to watch Celine Song’s Materialists - love that director), so this is how it ends up. The Java ecosystem looks pretty well prepared for the reality developers live in today.
PS: I’m writing this from TECH WEEK by a16z in San Francisco, where the words AI/Agent/LLM are used in every possible context, so the vibe is very conducive to a piece like this.
PS2: A great new episode with from my favourite series - JVM Weekly in strange places. This time, Pier 39 in San Francisco. I had also one from Union Square, but never bet against Seals 🦭

Hey Artur, there's a subtle typo "simplicfication", thanks :)
Interesting analysis! I've been dabbling in the space for some time now and I feel like the data analysis and data visualization aspects of AI are often overlooked in Java.
The tooling is not well consolidated, for instance there are at least 5 different Java Jupyter kernel competing and no charting library that comes close to what exists in julia, python and R. It is similar for DataFrame libraries, even though tablesaw seems to dominate. The AI developments are also a matter of community and it feels like the ones who build and innovate in AI simply don't find the tooling they need to create and experiment in Java.
I've recently been building an alternative to Streamlit for Java that I think is a missing piece in the Java ecosystem: https://github.com/jeamlit/jeamlit. Quarkus and Spring are not designed for "data work" per se and require frontend work for anything that touches data viz. Curious what you think of such tools and the ecosystem in general in the context of quick experimentation, data viz and building data apps that consume AI / AI results, and that are easy to use for AI builders.