

"Semantic Caching with Spring Boot & Redis" with Raphael De Lio - JVM Weekly vol. 144
Today, we have a guest post from Raphael De Lio about cutting costs in LLM-based apps.



Last May, I announced that JVM Weekly had joined the Friends of OpenJDK (Foojay.io) family. Foojay.io is a dynamic, community-driven platform for OpenJDK users, primarily Java and Kotlin enthusiasts. As a hub for the “Friends of OpenJDK,” Foojay.io gathers a rich collection of articles written by industry experts and active community members, offering valuable insights into the latest trends, tools, and practices within the OpenJDK ecosystem.
So like last month, I have something special - a repost of a great JVM-related article, originally posted on Foojay.io. This week’s deep dive comes from Raphael De Lio, a Developer Advocate at Redis. In his article Raphael breaks down the concept of semantic caching - a technique that goes beyond simple key-value lookups to cache data based on meaning and context. A lot of interesting engineering inside.
PS: This is not a paid promo or anything (if I ever do that, you will know upfront 😉) - just me spreading knowledge about interesting concept.
Semantic Caching with Spring Boot & Redis
TL;DR: You’re building a semantic caching system using Spring AI and Redis to improve LLM application performance.
The Problem with Traditional LLM Applications
LLMs are powerful but expensive. Every API call costs money and takes time. When users ask similar questions like “What beer goes with grilled meat?” and “Which beer pairs well with barbecue?”, traditional systems would make separate LLM calls even though these queries are essentially asking the same thing.
Traditional exact-match caching only works if users ask the identical question word-for-word. But in real applications, users phrase questions differently while seeking the same information.
How Semantic Caching Works
Video: What is a semantic cache?
Semantic caching solves this by understanding the meaning behind queries rather than matching exact text. When a user asks a question:
The system converts the query into a vector embedding
It searches for semantically similar cached queries using vector similarity
If a similar query exists above a certain threshold, it returns the cached response
If not, it calls the LLM, gets a response, and caches both the query and response for future use
Behind the scenes, this works thanks to vector similarity search. It turns text into vectors (embeddings) - lists of numbers - stores them in a vector database, and then finds the ones closest to your query when checking for cached responses.
Today, we’re gonna build a semantic caching system for a beer recommendation assistant. It will remember previous responses to similar questions, dramatically improving response times and reducing API costs.
To do that, we’ll build a Spring Boot app from scratch and use Redis as our semantic cache store. It’ll handle vector embeddings for similarity matching, enabling our application to provide lightning-fast responses for semantically similar queries.
Redis as a Semantic Cache for AI Applications
Video: What's a vector database
Redis Open Source 8 not only turns the community version of Redis into a Vector Database, but also makes it the fastest and most scalable database in the market today. Redis 8 allows you to scale to one billion vectors without penalizing latency.
For semantic caching, Redis serves as:
A vector store using Redis JSON and the Redis Query Engine for storing query embeddings
A metadata store for cached responses and additional context
A high-performance search engine for finding semantically similar queries
Spring AI and Redis
Video: What’s an embedding model?
Spring AI provides a unified API for working with various AI models and vector stores. Combined with Redis, it allows developers to easily build semantic caching systems that can:
Store and retrieve vector embeddings for semantic search
Cache LLM responses with semantic similarity matching
Reduce API costs by avoiding redundant LLM calls
Improve response times for similar queries
Building the Application
Our application will be built using Spring Boot with Spring AI and Redis. It will implement a beer recommendation assistant that caches responses semantically, providing fast answers to similar questions about beer pairings.
0. GitHub Repository
The full application can be found on GitHub.
1. Add the required dependencies
From a Spring Boot application, add the following dependencies to your Maven or Gradle file:
implementation("org.springframework.ai:spring-ai-transformers:1.0.0")
implementation("org.springframework.ai:spring-ai-starter-vector-store-redis")
implementation("org.springframework.ai:spring-ai-starter-model-openai")2. Configure the Semantic Cache Vector Store
We’ll use Spring AI’s RedisVectorStore to store and search vector embeddings of cached queries and responses:
@Configuration
class SemanticCacheConfig {
@Bean
fun semanticCachingVectorStore(
embeddingModel: TransformersEmbeddingModel,
jedisPooled: JedisPooled
): RedisVectorStore {
return RedisVectorStore.builder(jedisPooled, embeddingModel)
.indexName("semanticCachingIdx")
.contentFieldName("content")
.embeddingFieldName("embedding")
.metadataFields(
RedisVectorStore.MetadataField("answer", Schema.FieldType.TEXT)
)
.prefix("semantic-caching:")
.initializeSchema(true)
.vectorAlgorithm(RedisVectorStore.Algorithm.HSNW)
.build()
}
}Let’s break this down:
Index Name: semanticCachingIdx — Redis will create an index with this name for searching cached responses
Content Field: content — The raw prompt that will be embedded
Embedding Field: embedding — The field that will store the resulting vector embedding
Metadata Fields:
answer: TEXT field for storing the LLM's response
Prefix: semantic-caching: — All keys in Redis will be prefixed with this to organize the data
Vector Algorithm: HSNW — Hierarchical Navigable Small World algorithm for efficient approximate nearest neighbor search
3. Implement the Semantic Caching Service
The SemanticCachingService handles storing and retrieving cached responses from Redis:
@Service
class SemanticCachingService(
private val semanticCachingVectorStore: RedisVectorStore
) {
private val logger = LoggerFactory.getLogger(SemanticCachingService::class.java)
fun storeInCache(prompt: String, answer: String) {
// Create a document for the vector store
val document = Document(
prompt,
mapOf("answer" to answer)
)
// Store the document in the vector store
semanticCachingVectorStore.add(listOf(document))
logger.info("Stored response in semantic cache for prompt: ${prompt.take(50)}...")
}
fun getFromCache(prompt: String, similarityThreshold: Double = 0.8): String? {
// Execute similarity search
val results = semanticCachingVectorStore.similaritySearch(
SearchRequest.builder()
.query(prompt)
.topK(1)
.build()
)
// Check if we found a semantically similar query above threshold
if (results?.isNotEmpty() == true) {
val score = results[0].score ?: 0.0
if (similarityThreshold < score) {
logger.info("Cache hit! Similarity score: $score")
return results[0].metadata["answer"] as String
} else {
logger.info("Similar query found but below threshold. Score: $score")
}
}
logger.info("No cached response found for prompt")
return null
}
}Key features of the semantic caching service:
Stores query-response pairs as vector embeddings in Redis
Retrieves cached responses using vector similarity search
Configurable similarity threshold for cache hits
Comprehensive logging for debugging and monitoring
4. Integrate with the RAG Service
The RagService orchestrates the semantic caching with the standard RAG pipeline:
@Service
class RagService(
private val chatModel: ChatModel,
private val vectorStore: RedisVectorStore,
private val semanticCachingService: SemanticCachingService
) {
private val logger = LoggerFactory.getLogger(RagService::class.java)
fun retrieve(message: String): RagResult {
// Check semantic cache first
val startCachingTime = System.currentTimeMillis()
val cachedAnswer = semanticCachingService.getFromCache(message, 0.8)
val cachingTimeMs = System.currentTimeMillis() - startCachingTime
if (cachedAnswer != null) {
logger.info("Returning cached response")
return RagResult(
generation = Generation(AssistantMessage(cachedAnswer)),
metrics = RagMetrics(
embeddingTimeMs = 0,
searchTimeMs = 0,
llmTimeMs = 0,
cachingTimeMs = cachingTimeMs,
fromCache = true
)
)
}
// Standard RAG process if no cache hit
logger.info("No cache hit, proceeding with RAG pipeline")
// Retrieve relevant documents
val startEmbeddingTime = System.currentTimeMillis()
val searchResults = vectorStore.similaritySearch(
SearchRequest.builder()
.query(message)
.topK(5)
.build()
)
val embeddingTimeMs = System.currentTimeMillis() - startEmbeddingTime
// Create context from retrieved documents
val context = searchResults.joinToString("\n") { it.text }
// Generate response using LLM
val startLlmTime = System.currentTimeMillis()
val prompt = createPromptWithContext(message, context)
val response = chatModel.call(prompt)
val llmTimeMs = System.currentTimeMillis() - startLlmTime
// Store the response in semantic cache for future use
val responseText = response.result.output.text ?: ""
semanticCachingService.storeInCache(message, responseText)
return RagResult(
generation = response.result,
metrics = RagMetrics(
embeddingTimeMs = embeddingTimeMs,
searchTimeMs = 0, // Combined with embedding time
llmTimeMs = llmTimeMs,
cachingTimeMs = 0,
fromCache = false
)
)
}
private fun createPromptWithContext(query: String, context: String): Prompt {
val systemMessage = SystemMessage("""
You are a beer recommendation assistant. Use the provided context to answer
questions about beer pairings, styles, and recommendations.
Context: $context
""".trimIndent())
val userMessage = UserMessage(query)
return Prompt(listOf(systemMessage, userMessage))
}
}Key features of the integrated RAG service:
Checks semantic cache before expensive LLM calls
Falls back to standard RAG pipeline for cache misses
Automatically caches new responses for future use
Provides detailed performance metrics including cache hit indicators
Running the Demo
The easiest way to run the demo is with Docker Compose, which sets up all required services in one command.
Step 1: Clone the repository
git clone https://github.com/redis-developer/redis-springboot-resources.git
cd redis-springboot-resources/artificial-intelligence/semantic-caching-with-spring-aiStep 2: Configure your environment
Create a .env file with your OpenAI API key:
OPENAI_API_KEY=sk-your-api-keyStep 3: Start the services
docker compose up --buildThis will start:
redis: for storing both vector embeddings and cached responses
redis-insight: a UI to explore the Redis data
semantic-caching-app: the Spring Boot app that implements the semantic caching system
Step 4: Use the application
When all services are running, go to localhost:8080 to access the demo. You'll see a beer recommendation interface:
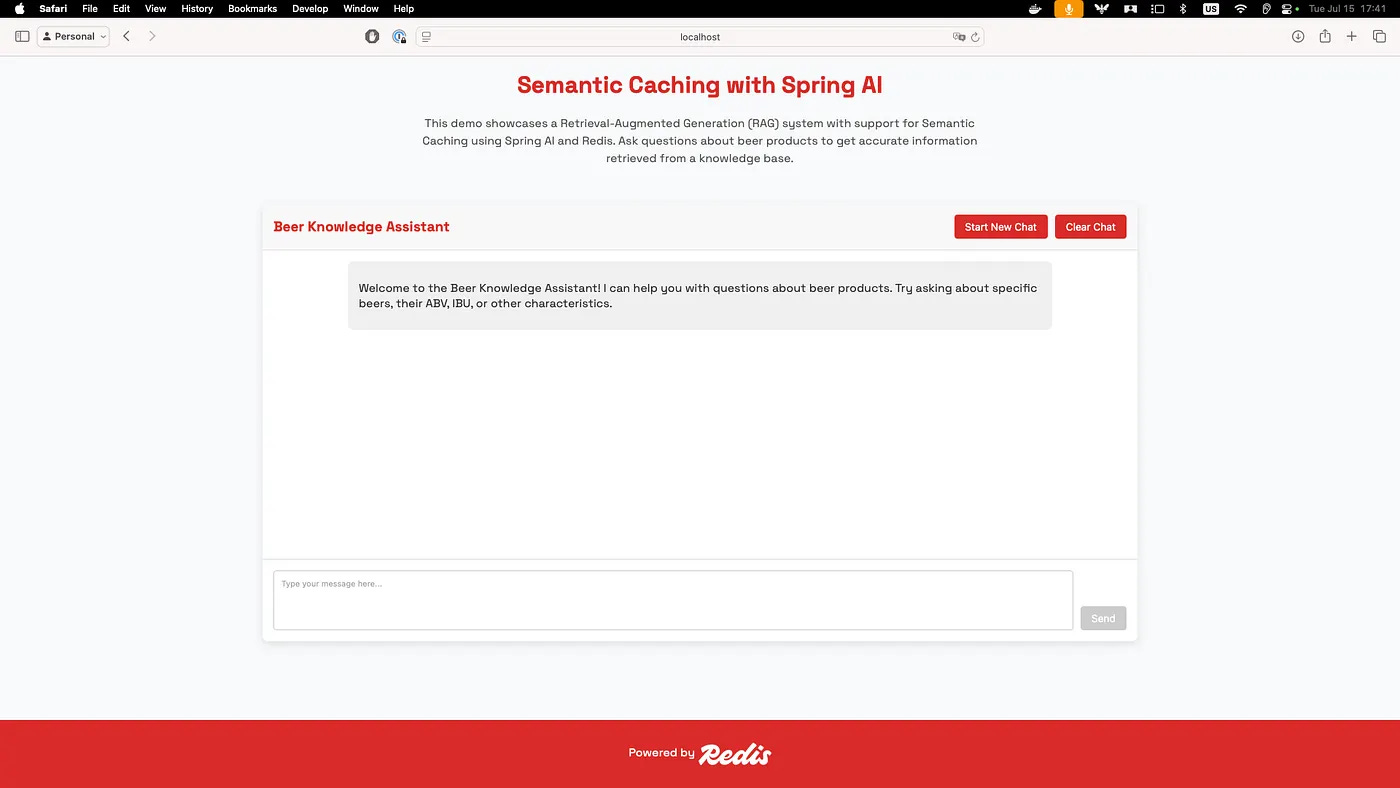
If you click on Start Chat, it may be that the embeddings are still being created, and you get a message asking for this operation to complete. This is the operation where the documents we'll search through will be turned into vectors and then stored in the database. It is done only the first time the app starts up and is required regardless of the vector database you use.
Once all the embeddings have been created, you can start asking your chatbot questions. It will semantically search through the documents we have stored, try to find the best answer for your questions, and cache the responses semantically in Redis:
If you ask something similar to a question had already been asked, your chatbot will retrieve it from the cache instead of sending the query to the LLM. Retrieving an answer much faster now.
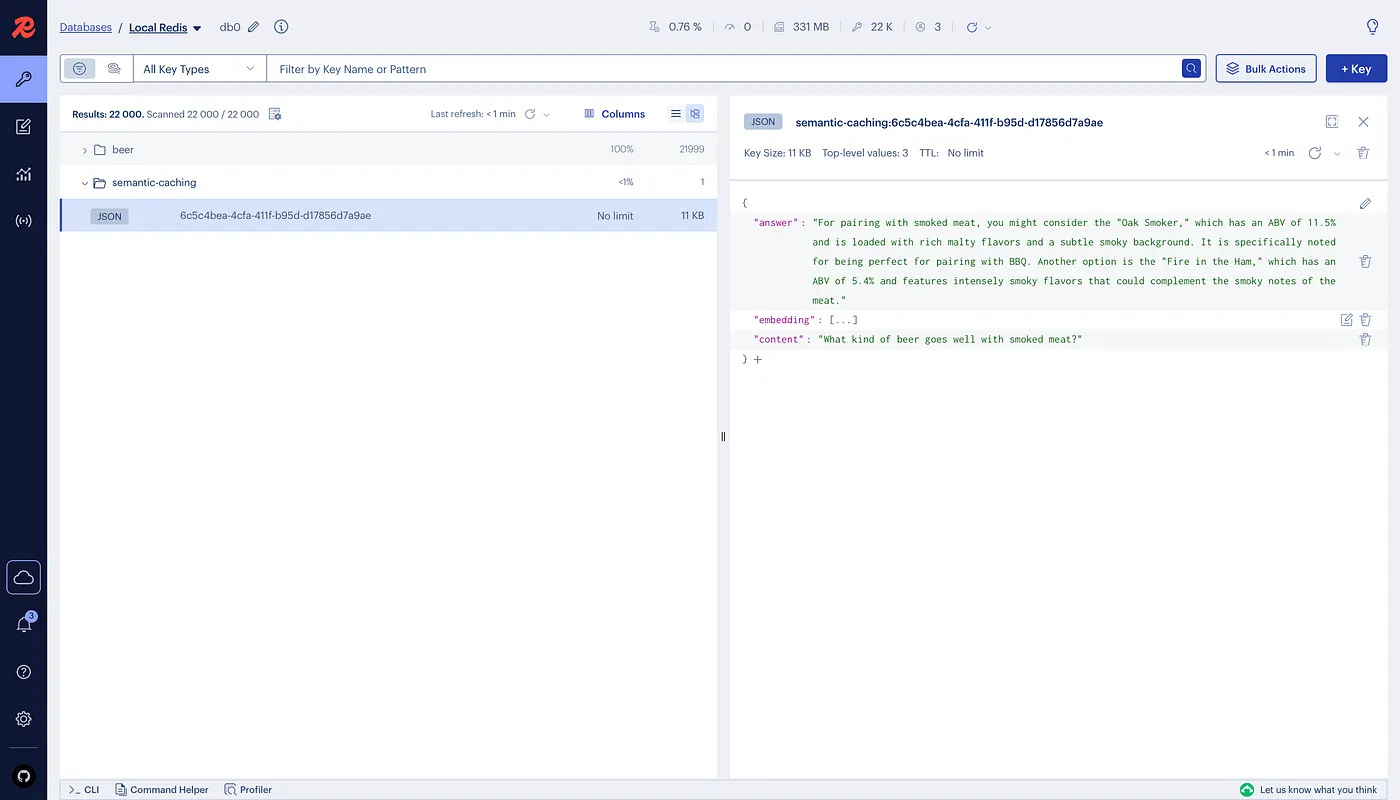
Exploring the Data in Redis Insight
RedisInsight provides a visual interface for exploring the cached data in Redis. Access it at localhost:5540 to see:
Semantic Cache Entries: Stored as JSON documents with vector embeddings
Vector Index Schema: The schema used for similarity search
Performance Metrics: Monitor cache hit rates and response times
If you run the FT.INFO semanticCachingIdx command in the RedisInsight workbench, you'll see the details of the vector index schema that enables efficient semantic matching.
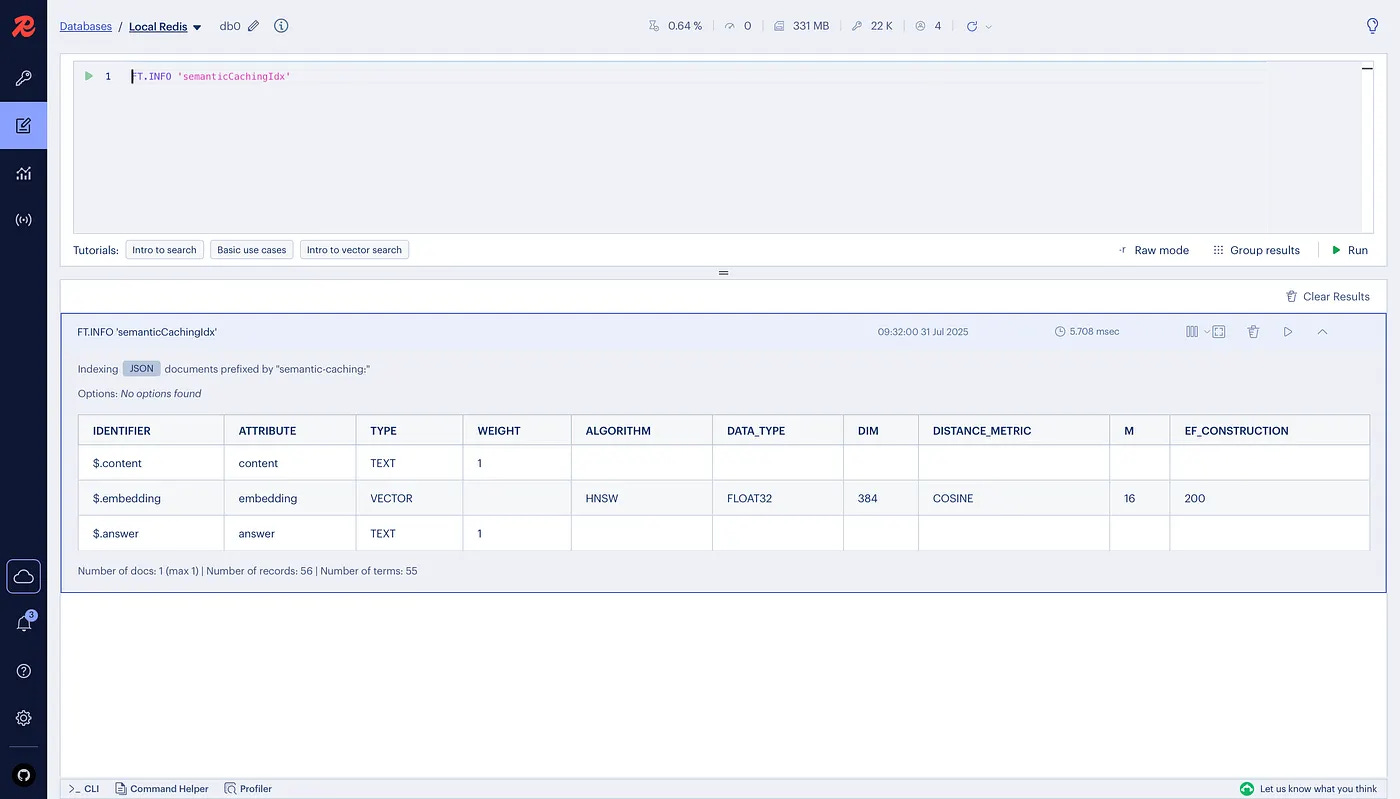
Wrapping up
And that’s it - you now have a working semantic caching system using Spring Boot and Redis.
Instead of making expensive LLM calls for every similar question, your application can now intelligently cache and retrieve responses based on semantic meaning. Redis handles the vector storage and similarity search with the performance and scalability Redis is known for.
With Spring AI and Redis, you get an easy way to integrate semantic caching into your Java applications. The combination of vector similarity search for semantic matching and efficient caching gives you a powerful foundation for building cost-effective, high-performance AI applications.
Whether you’re building chatbots, recommendation engines, or question-answering systems, this semantic caching architecture gives you the tools to dramatically reduce costs while maintaining response quality and improving user experience.
Try it out, experiment with different similarity thresholds, explore other embedding models, and see how much you can save on LLM costs while delivering faster responses!
And now, let's review some of the other cool things that appeared on Foojay.io last month 😁
Why Java is Still Worth Learning in 2025: A Developer’s 25-Year Journey
This piece is quite a journey! From C-hardened skeptic to Java advocate, Markus Westergren arc described in Why Java is Still Worth Learning in 2025: A Developer’s 25-Year Journey is a reminder that Java’s real moat isn’t shiny features but compounding ergonomics, boring-reliable backward compatibility, and a choice-rich ecosystem that avoids lock-in.
The piece walks through “brain-friendly” modern Java (records, pattern matching, enhanced switch), why code from the 1.4 era can still hum on 21, and how virtual threads and cloud-native stacks (Spring, Quarkus, multiple JDKs) make Java feel surprisingly new without breaking old investments. It’s a love letter to stability that still ships velocity.
AI Gives Time, Not Confidence: Developer Productivity Toolkit
There is old Rich Hickey saying
"Programmers know the benefits of everything and the tradeoffs of nothing" .
We’ve all been dazzled by AI tools that promise a revolution in productivity. But what’s the price of that convenience?
AI Gives Time, Not Confidence: Developer Productivity Toolkit by Jonathan Vila astutely points out that while AI may give us back time, it doesn’t necessarily build our confidence in problem-solving. The text is a grounded tour of where AI genuinely helps a Java dev across the SDLC - unblocking fuzzy requirements, blasting boilerplate, nudging CI/CD scaffolds - without pretending it replaces engineering judgment. Expect concrete IDE-level flows (Copilot, Cursor, Windsurf), codebase-aware context, and MCP-style integrations with repos and issues; balanced by the grown-up bits: security hygiene, review discipline, tests, and static analysis.
The mantra holds: AI returns hours, but you still own confidence. While this is probably something most of people is aware of , it’s an good analysis of the trade-off between quick “copy-paste” solutions and deep understanding of code - something every developer must confront.

OpenTelemetry Tracing on the JVM
In his OpenTelemetry Tracing on the JVM, Nicolas Fränkel 🇺🇦🇬🇪 tackles the often-confusing landscape of implementing OpenTelemetry tracing on the JVM. The article serves as a guide for developers faced with multiple "zero-code" options, each with its own trade-offs by comparing five distinct approaches, including using the standard OpenTelemetry agent, leveraging native integrations in frameworks like Quarkus, and utilizing Spring Boot's Micrometer Tracing. The goal is to demystify the process and provide a clear verdict on which method offers the best balance of ease-of-use and functionality for modern, reactive applications.
To ensure a fair comparison, Nicolas builds a consistent test case using a reactive stack with Kotlin coroutines, which effectively highlights the differences in how each setup handles context propagation in non-blocking code. After running through the implementation details and potential pitfalls of each method, the article arrives at a strong conclusion: for most use cases, the OpenTelemetry Java agent is the superior choice. It requires no code changes, seamlessly integrates with various frameworks and libraries, and correctly handles complex asynchronous scenarios, making it the most robust and straightforward path to gaining observability in a JVM environment.
Taking Java Arrays to Another Dimension
In Taking Java Arrays to Another Dimension, Simon Ritter takes a familiar topic - Java arrays - and reveals the surprising depth hidden beneath the surface. Moving far beyond basic syntax, he explores the nuances of how multi-dimensional arrays are actually constructed within the JVM. The piece explains why Java doesn't have true multi-dimensional arrays, but rather "arrays of arrays," a distinction that allows for the creation of powerful "jagged" structures. By looking under the hood at the specific JVM bytecodes used for array creation, Ritter provides a foundational understanding that is often overlooked in day-to-day coding.
The real takeaway, however, lies in the practical performance implications of this underlying structure. The article features a compelling benchmark that demonstrates a surprising difference in execution speed based on the order of iteration through a multi-dimensional array. By showing how a simple change in looping strategy can lead to significant optimization, the article proves to be useful reading for any developer serious about mastering Java and understanding how their code truly interacts with the virtual machine.
Do We Understand the Value of AI Knowledge?
In Do We Understand the Value of AI Knowledge? , Miroslav (Miro) Wengner delves into a philosophical question about the nature of knowledge within modern AI systems. The piece challenges the conventional view of LLMs as reliable repositories of information, drawing a compelling parallel between their non-deterministic outputs and the lost, irreproducible methods used to build ancient wonders like the pyramids. It argues that the true "gold" of these models - their calculated weights - are a product of processes so complex and opaque that we cannot guarantee consistent or even correctable results, raising fundamental doubts about the stability of the knowledge they produce.
This leads to a deeper exploration of the practical consequences of relying on such systems. The author questions the "self-repair" capabilities of AI, highlighting the immense difficulty in correcting biased or flawed information when the underlying reasoning is not transparent. Similary to Jonathan Vila 🥑 ☕️ one, this article serves as a reality check, urging readers to move beyond the surface-level capabilities of AI and consider the long-term implications of building a future on a foundation of knowledge that we don't fully control or understand.
I'm in the mood for such a stuff, currently reading The Metamorphosis of Prime Intellect. It is... intense one 😅

PS: Foojay.io and Miro are carrying on their AI newsletter.
And that’s all, folks! See you next week 😊

 | A guest post by
|