

November: The Rest of the Story - JVM Weekly vol. 154
I’ve gathered many interesting links in November that didn’t make it into previous issues. Many aren’t extensive enough for a full section, but they still seem compelling enough to share.


Just a week ago I wrote that “Spring has come”, and now it’s snowing in Poland...
1. Missed in November

But let’s actually start with some Spring-related topics.
The article Null-safe applications with Spring Boot 4 by Sébastien Deleuze brings good news: with the arrival of Spring Boot 4 (and Spring Framework 7), most of the Spring portfolio has gained full support for null-safety. This means that key APIs have been explicitly annotated with JSpecify, which allows developer tools (such as IntelliJ IDEA or Eclipse) and the Kotlin compiler to precisely detect potential NullPointerException (NPE) issues. These changes are backwards compatible for Java, but drastically improve code safety, so if you want to learn more details (and certainly if you use Spring), it’s really worth a read.
Staying with the most popular framework, the post OpenTelemetry with Spring Boot by Moritz Halbritter is a guide to the native integration of OpenTelemetry in the Spring Boot 4 ecosystem. The authors explain how the latest version of the framework moves away from the need to use a heavy Java Agent in favor of built-in instrumentation based on Micrometer Tracing. Thanks to this, applications can now “out of the box” generate and propagate traces, metrics and logs in an OTel-compliant format, while retaining better performance and control over the code.
In the article Modularizing Spring Boot, the Spring Boot team describes a fundamental architectural change in version 4.0: splitting the monolithic spring-boot-autoconfigure.jar file (which had grown to 2 MiB) into smaller, more focused modules. The goal is not only to reduce artifact size and the application memory footprint, but above all to improve IDE “hygiene” – developers will no longer be bombarded with code completion suggestions for technologies they’re not using (e.g. Reactive Web classes in a pure MVC project).
Each supported technology (e.g. Flyway or Spring Security) now gets its own dedicated starter, which pulls in only the configuration modules it actually needs. What’s more, analogous test starters have been introduced for each module, making it easier to configure your test environment.
For teams worried about a painful migration, Classic Starter POMs are preserved. They emulate the old behavior by pulling in all modules at once, allowing for a gradual transition to the new, leaner architecture.
As you can see, there’s a lot going on - so to round off the Spring section, I’ve got a migration guide for you.
The article Spring Boot 4.x Migration Guide from Moderne shows that moving to Spring Boot 4 is much more than just bumping a version number. It comes with fundamental ecosystem changes: Java 17 as a minimum (with Java 25 recommended), full adoption of Jakarta EE 11, and integration with Spring Framework 7. The authors highlight the removal of as much as 88% of deprecated classes (including MockBean and SpyBean), the introduction of Jackson 3.x with its breaking changes, and the need to adapt your code to the new (and cool!) null-safety standards.
The main goal of the piece, however, is to show how to automate this process using OpenRewrite. Moderne has prepared ready-made “recipes” that can automatically update dependencies, replace removed APIs, and even perform complex code refactorings (e.g. switching to modular starters or adding JSpecify annotations). Thanks to this, a migration that could take weeks manually becomes a predictable and scalable process, one that can be rolled out across an entire organization.
As always, I highly recommend trying out OpenRewrite – it’s a neat piece of software.
And since we’ve wrapped up the Spring topic… for once I’ve got something for Android fans.
Google has introduced Cahier - a new open-source sample app meant to serve as a reference for developers building productivity and creativity tools for large screens (tablets and foldables). The name comes from the French word for “notebook”, which perfectly captures the app’s purpose: combining text, drawings (using the low-latency Ink API) and images into cohesive notes.

Cahier demonstrates a modern offline-first architecture based on Room, as well as the use of Material 3 Adaptive libraries to create UIs that smoothly adapt to different device form factors.
Now for something more lighthearted - Java Mascot Generator by Ethan M. is a fun, lightweight web tool that lets you generate random, unique variations of Duke – Java’s iconic mascot.
Here’s mine.
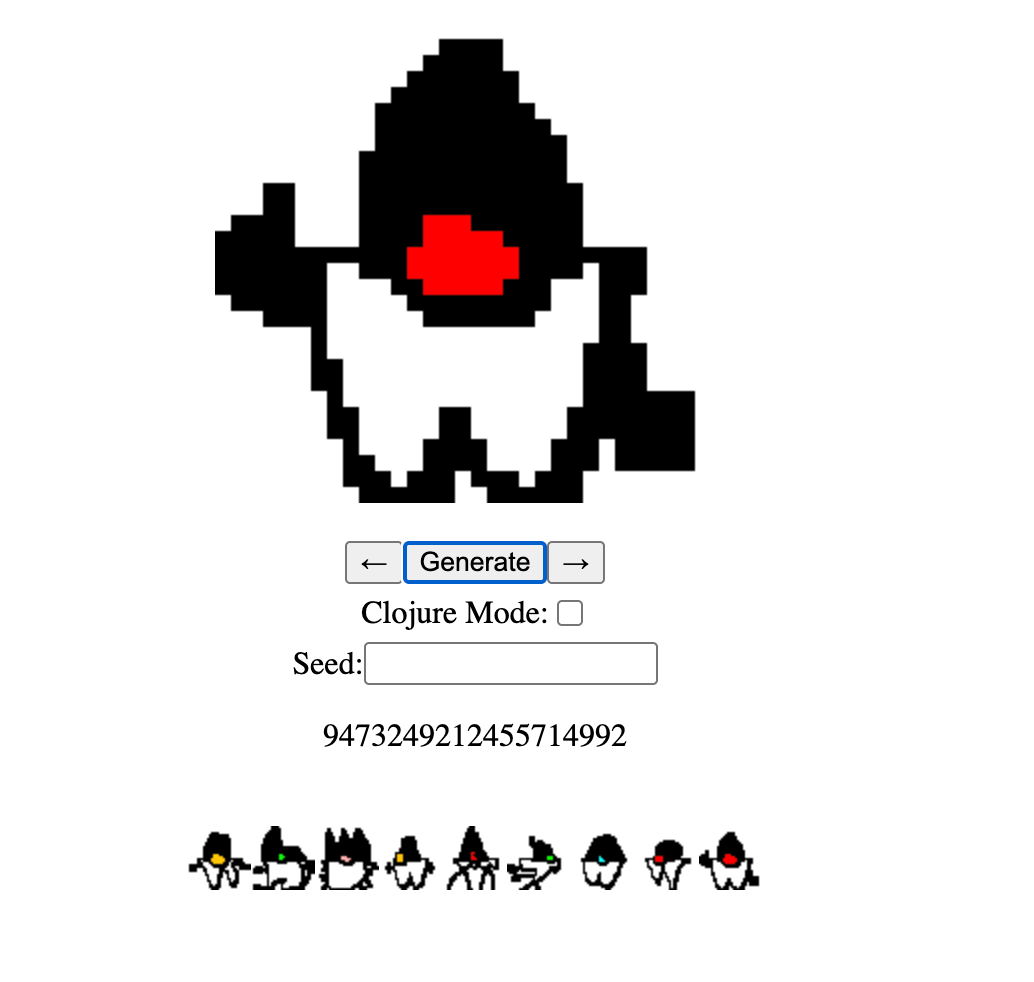
The app runs directly in the browser thanks to CheerpJ, which makes it possible to run classic Java code in a WebAssembly environment without installing any extra plugins.
The whole thing is built around a simple interface where a random seed is used to generate a new version of the mascot. Although it’s an unofficial project, it’s a great demo of how to bring older UI technologies into the browser, and at the same time it lets every developer “grow” their own unique Duke.

Awesome J2ME by Harsh Sethi is not so much a repository as a sentimental journey back to the era of flip phones and games distributed as .jar files. The author has prepared a curated list of emulators, developer tools, documentation and software collections dedicated to the Java 2 Micro Edition (J2ME) platform. You’ll find everything you need to run classic mobile titles on modern systems.
The discussion on Hacker News proves that J2ME still sparks strong emotions. Users swap memories of cult games (like Doom RPG) and share technical tidbits about the hardware fragmentation of that time. It’s a great resource for digital archivists and retro-gaming fans who want to see what Java in your pocket looked like before the smartphone era.
PS: It genuinely warmed my heart. If you’re from Poland (though YouTube will probably happily generate UI dubbing for you), I’ve got a great video for you about classic mobile games. And personally, I always liked Gameloft titles.
Deal with this, Candy Crash.
Staying in the mobile world, just a bit more modern this time, the article Java on iOS by Ben Evans discusses the latest advances in running Java applications on iOS, made possible thanks to full integration of Java 25 with GraalVM Native Image technology. The new solutions allow for direct AOT compilation of Java code to native machine code, eliminating long-standing performance issues and Apple’s restrictions on JIT compilation on mobile devices.
Ben highlights the growing role of frameworks like Gluon, which leverage these improvements to enable developers to build high-performance, cross-platform user interfaces in pure Java. As a result, porting modern backend and desktop applications to iPhones and iPads is becoming feasible, opening the Java ecosystem to the mobile market in a way that was previously reserved mainly for fully native solutions.
The article First Look at Java Valhalla: Flattening and Memory Alignment of Value Objects by Joe Mwangi is a nice analysis of the latest Valhalla build (JEP 401), focusing on the memory “flattening” mechanism for Value Class objects. The author ran an experiment comparing an array of classic objects with an array of the new Value Objects. The results show that by giving up object identity, the JVM can store data directly in the array, rather than as references on the heap. In a test with 10 million records, memory usage dropped from ~309 MB to ~138 MB, which drastically improves cache locality and eliminates the overhead of object headers.

The more interesting part of the analysis, however, is memory alignment. The author noticed that an object with a size of 6 bytes takes up 8 bytes in memory. It turns out the culprit is the “null marker” – because Value Object arrays support null values by default, the JVM adds a hidden marker byte plus padding to align the structure to the atomicity boundary (typically 64 bits). You can already see this starting to conflict with Project Lilliput.
Elliot Barlas shared an update to his tool for browsing and searching OpenJDK mailing lists. The site has gained indexes for additional lists (including javadoc-dev, jmh-dev, mobile-dev), bringing the total to over 400,000 email messages and 70 million phrases. The update also adds visual highlighting for records that originate from GitHub activity, as well as improved documentation, making this unofficial archive even more useful for the community.
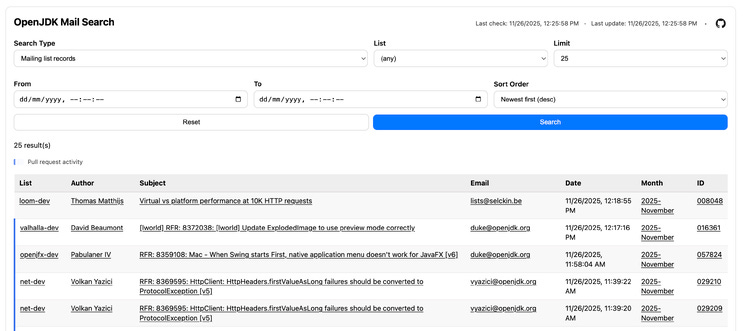
The tool lets you quickly find historical discussions without having to dig through raw mail archives, and I’ve already used it a few times myself when trying to track down early mentions of various projects. So thanks Elliot – you’ve definitely contributed something to this newsletter 🙇
And to finish, two talks from JetBrains.
In Kotlin Notebook Meets IntelliJ Platform, 🥑 Jakub Chrzanowski at Plugin Dev Conf 2025 showcases the capabilities of Kotlin Notebook – hopefully familiar to you as an interactive environment reminiscent of Jupyter Notebook, but running directly inside IntelliJ IDEA. The video shows how to create notes with embedded code, visualize results and – most interestingly – run IntelliJ Platform code directly from the notebook, without having to compile and launch a full plugin. It’s a huge convenience for plugin authors, allowing them to quickly test IDE APIs and experiment with new features in an isolated, safe REPL environment.
The second talk is Learning Modern Java the playful way by 👩🏻💻 Marit van Dijk & 🥼Piotr Przybył , who address the problem of “decision paralysis” that can hit developers moving from older Java versions (e.g. Java 8) to modern releases. Instead of dry theory, the speakers focus on “play” and a practical approach to learning new features such as Structured Concurrency and Pattern Matching.
The session focuses on how to use a modern IDE to discover these features organically while writing code - and on top of that, it’s freaking hilarious. Highly recommended 😁
2. Release Radar

Spring Modulith 2.0 GA
Lots of Spring today… but what can I do when the whole ecosystem is modernizing at once 🤷.
With the dawn of the Spring Boot 4 era, Spring Modulith has reached version 2.0. The main changes include adapting to the new bean lifecycle in Spring Framework 7 and native support for JSpecify, which enables better null-safety verification inside application modules. This release also introduces the “Module Canvas” – an interactive tool for visualizing dependencies between domains, generated directly from your code.
The update also puts a strong emphasis on event handling. Spring Modulith 2.0 automates the “event externalization” process with even greater precision, now natively supporting newer versions of brokers such as Kafka 4.0 and RabbitMQ. Thanks to this, developers can focus on the business logic inside a module, knowing that asynchronous communication with the rest of the system (or other microservices, if you later extract them) is safe, transactional, and aligned with the agreed architectural rules.
jMolecules 2.0
Staying with architecture: jMolecules 2.0 is another step toward “architecture visible in code.” The library provides annotations and models that let you express DDD concepts (like @Entity, @Repository, @AggregateRoot) and other architectural stereotypes directly in code, not just in diagrams. The new release cleans up the package structure, better separating the stereotypes themselves from their implementations (for example, the ByteBuddy-based one), and also strengthens support for the just-mentioned Spring Modulith.
PS: Oliver Drotbohm is the author and main creator of both jMolecules and Spring Modulith, which is why the two projects complement each other so well. jMolecules provides the DDD semantics (aggregates, entities, events), and Spring Modulith uses that semantics to build and enforce modular architecture in Spring applications.
Quarkus 3.30
Quarkus 3.30 is a classic “small but mighty” release – short changelog, but all very practical building blocks for everyday backend work.
You get @JsonView support on the REST Client side (until now it was server-only), so you can use a single set of views to control what you send to and receive from external services, instead of gluing together separate DTOs for every case. On top of that, Hibernate Validator is bumped to 9.1 with solid performance improvements, and there’s a new config decrypt CLI command that decrypts secrets previously encrypted with quarkus config encrypt - finally a clean, official secret-management flow for configuration, without custom scripts.
MongoDB Extension for Hibernate ORM
The new extension from MongoDB lets you use Hibernate ORM directly with MongoDB, translating familiar annotations and entity lifecycle concepts into operations on BSON documents. This makes migrations from relational databases (RDBMS) to Mongo significantly less painful, and developers don’t have to learn a completely new API to start working with documents.
The solution, currently in Public Preview, supports key Hibernate features such as lazy loading, first- and second-level caching, and multi-document transaction management. Although the impedance mismatch between the relational and document models (which, to be fair, is just as present in SQL/code itself) still exists, the extension tries to minimize it, offering a pragmatic bridge for enterprise applications that want to combine MongoDB’s schema flexibility with the maturity of the Hibernate ecosystem.
Apache Fory 0.13.0
Apache Fory (in incubation) continues its mission to be the fastest serialization framework on the JVM, and version 0.13.0 brings further performance optimizations thanks to better use of the Foreign Function & Memory (FFM) API. The new version drastically speeds up the serialization of objects that do not implement the Serializable interface, using real-time (JIT) code generation in an even more aggressive yet memory-safe manner than before.
A key highlight is improved compatibility with GraalVM Native Image. Earlier versions required a complex reflection configuration, whereas 0.13.0 introduces automated metadata generation, making Fury an ideal choice for serverless applications where every millisecond of startup time and payload deserialization counts. This release cements Fury’s position as a modern alternative to standard Java serialization or Kryo – I use it, highly recommend it.
Infinispan 16.0
The sixteenth release of this distributed cache and data grid focuses on full integration with the AI ecosystem and Vector Search. Infinispan 16.0 can now store and index vectors (embeddings) directly in memory, enabling lightning-fast similarity search queries in RAG (Retrieval-Augmented Generation) applications without having to reach out to external vector databases. That’s a huge convenience for Java systems built with LLMs in mind.
From an operational perspective, version 16.0 brings a revamped admin console and native support for Virtual Threads. There are also improvements in the Hot Rod protocol that reduce latency in Cross-Site Replication topologies, which is crucial for globally distributed systems.
Reactor 2025.0.0
Project Reactor has released a fresh release train, 2025.0.0 – under this umbrella we get, among others, Reactor Core 3.8.0, Reactor Netty 1.3.0 and refreshed reactor-kotlin-extensions 1.3.0, while reactor-netty5, reactor-kafka and the reactive-streams artifact officially step off the train (the API itself still lives on in Flux/Mono; it’s just no longer managed by the BOM). In Core itself, the most important change is the switch to JSpecify for describing null-safety, which improves IDE and Kotlin integration, plus moving RepeatSpec from addons into core, bumping Micrometer and Context Propagation, and a few sensible contract tightenings (e.g. no longer letting map pass through null).
Reactor 2025 is a signal that Reactive Streams isn’t dying but evolving toward a hybrid concurrency model – I wish them the best of luck 😊
Personal note: the only scientific paper of my career was actually about Reactive Streams.
JobRunr 8.2 and 8.3
JobRunr is an easy-to-use Java library by Roland for durable background jobs – from fire-and-forget, through delayed jobs, to recurring CRONs – built on plain Java methods and your existing database. In November they shipped two new releases!
In the 8.2 branch, the team mainly reinforces the foundations: full support for Kotlin 2.2.20, updates for newer framework versions (including Quarkus), simplified metrics configuration via the new useMetrics() API instead of the deprecated useMicroMeter(), and a heavy hardening of dashboard security – including CSP headers, disabling CORS from the browser, and a mechanism for defining allowed origins in Pro. JobRunr Pro 8.2 adds observability for rate limiters (a dedicated tab in the dashboard, automatic cleanup of unused limiters) and a range of workflow improvements.
Version 8.3 is more clearly “pushing forward” the tech stack: it adds support for Spring Boot 4 and Jackson 3 (which seems to be the main theme of this whole edition), while still staying compatible with Spring Boot 3 and Jackson 2 thanks to being published as a Multi-Release JAR (separate classes for Java 8 and Java 17+). Along the way, the dashboard got a major refresh (dark mode, a new “Control Center” for settings, better responsiveness on small screens), Error Prone was enabled in the pipeline, and the multi-release JAR is treated as a strategic step that in future releases should ease the move to the Java Class File API from JDK 24 and ultimately remove the dependency on ASM.
Apache NetBeans 28
The latest release of this classic IDE primarily brings full support for JDK 25, which has just seen the light of day. NetBeans 28 integrates the new language features, such as compact source files and module imports, offering full support for them in code completion and refactoring. The team also focused on improving application startup performance and reducing memory usage, in response to growing competition from lighter editors.
Another important part of this update is the refreshed integration with build systems. Support for Gradle 9.0 and Maven 4 has been improved, ensuring smoother synchronization of multi-module projects. NetBeans 28 also introduces new tools for debugging cloud and containerized applications, making it a more attractive choice for developers working in Cloud Native environments who don’t want to move to paid solutions.
Old but gold 😁 It always amazes me how much life there still is in this old-timer.
Amper November Update
Amper, an experimental project configuration tool from JetBrains, in its November 2025 update is entering a new phase. The team focused on going beyond the Kotlin Multiplatform ecosystem, wanting to turn Amper into a real alternative to Gradle also for typical Java/Spring backend projects. The new version introduces an advanced build caching system and improved integration with IntelliJ IDEA, where YAML configuration files get support on a level similar to what we’re used to from the Kotlin DSL.
This update also brings “Amper Modules” – a simplified way of defining dependencies between modules that automatically resolves version conflicts without having to write complex scripts. Although Amper is still fighting for its place in a market dominated by Maven and Gradle, the November release shows that JetBrains is serious about creating a tool that favors declarativity and simplicity over infinite configurability. We’ll see how that plays out.
Compose Hot Reload v1.0.0 by JetBrains
And finally, for everyone working with Compose Multiplatform, Compose Hot Reload 1.0.0 is a small milestone. The tool lets you make changes to UI code and see the effect almost in real time, without a full rebuild and app restart – JetBrains Runtime “intelligently” reloads the changed code, which makes UI iteration much faster.
Compose Hot Reload is said to particularly shine in larger projects, where the classic “build → run → click to the right screen” cycle costs minutes instead of seconds.
3. Github All-Stars

Clique
If you build CLI tools and you’re tired of fighting with ANSI codes or heavy dependencies, Clique can be a breath of fresh air. It’s an ultra-lightweight, dependency-free library for styling console output in Java – focused on a simple API for coloring and formatting text without hand-writing ANSI escape sequences.

It’s nice when tools built by developers for developers are not only functional but also aesthetic. Clique is a great fit for small utility scripts or installers where you want nice-looking logs without pulling in big frameworks like JLine or Lanterna.
Lanat
The Java CLI argument parser space is already crowded, but Lanat is trying to carve out its place by focusing on modern design and a highly configurable user experience. It’s a Java 17 argument parser with annotations, auto-generated help, and a very polished error-message system that’s clear and user-friendly.
public static void main(String[] args) {
// example: david +a20
var myProgram = ArgumentParser.parseFromInto(MyProgram.class, args);
System.out.printf(
“Welcome %s! You are %d years old.%n”,
myProgram.name, myProgram.age
);
// if no surname was specified, we’ll show “none” instead
System.out.printf(”The surname of the user is %s.%n”, myProgram.surname.orElse(”none”));
}
The library lets you define complex commands and subcommands, custom argument types, and rich, colorful descriptions and messages in the terminal. If you want your CLI to look modern, provide sensible feedback to users, and at the same time leverage Java types instead of plain Strings, Lanat is worth a try.
Fray by CMU Pasta Lab
Fray targets one of the hardest areas of our daily work – concurrency. It’s a research tool from Carnegie Mellon University for controlled testing of multithreaded code on the JVM, helping detect race conditions, deadlocks, and other “heisenbugs” that usually show up only in production.

Fray takes control over thread interleaving, using modern concurrency-testing techniques and enabling deterministic replay of specific scenarios. It integrates with JUnit 5, so you can mark a test as concurrent via an annotation instead of building your own stress-testing infrastructure.
JedisExtraUtils
I think for many developers Jedis is the lightweight, default Redis client, but its fairly “bare” API forces you to write a lot of boilerplate. JedisExtraUtils is a set of utilities that wrap Jedis into ready-made patterns: iterators for scanning keys and structures, a simple read-through/write-through cache, a distributed RateLimiter, and a messaging system based on streams.
The project was born out of the need to simplify code in applications that don’t use heavier frameworks (like Spring Data Redis), want to retain control over the connection, but at the same time avoid copy-pasting the same utilities between repositories.
Bonus point: the author also supports Valkey, so you’re not welded to a single key-value server.
JBLIS
In the AI ecosystem, efficient linear algebra is a critical topic. JBLIS is a Java wrapper around the BLIS library (BLAS-like Library Instantiation Software), built on top of the Foreign Function & Memory (FFM) API. This lets you use native, highly optimized linear algebra from plain old Java code – without having to touch FFM yourself.
The library targets High-Performance Computing scenarios and compute-heavy backends: matrix and vector operations are performed with performance close to C/Fortran code, while you still stay in the JVM world. It can be a useful building block for projects that want to write logic in Java but don’t want to give up the performance of native numerical libraries.
rockpaperscissors-java25
Bruno Borges created the repo rockpaperscissors-java25, which is more than just a simple game. It’s a small, self-contained demonstration of how lean and modern Java 25 can be: minimal boilerplate, concise syntax, and a reminder that Java is suitable not only for giant enterprise machines, but also for small scripts and educational examples.
The code is a great starting point if you want to quickly show someone what modern Java looks like – without historical noise and using the latest language constructs.
Cajun
Cajun is a lightweight actor framework for Java, designed for JDK 21+ and modern concurrency paradigms (including virtual threads). The goal is to simplify building distributed, actor-based systems while focusing on a simple API, high performance, and easy integration with existing infrastructure (e.g., different communication backends).
It’s an interesting alternative to heavier reactive frameworks when you need a light actor layer but don’t want to go all-in on full-blown, “does-everything” platforms. Not every project will meaningfully benefit from something as large as Akka.
BTW: The README is a great introduction to the actor concept, but it’s also really long – it even made me wonder how much of it was generated by an LLM.
K-Random
K-Random is a library for generating random objects in Java and Kotlin – a fork of Easy Random, further developed with newer Java versions in mind and additional extensions (e.g., bean validation modules).
KRandom kRandom = new KRandom();
MyObject obj = kRandom.nextObject(MyObject.class);
With a single call, the library can create fully populated instances of domain classes, DTOs, or entities, filled with random data. It’s highly configurable – you can set generation rules for specific fields, types, or ranges, and plug in your own randomizers. It also has Kotlin support.
Querity by QuerityLib
Querity is an ambitious project aiming to solve the age-old problem of dynamic queries: how to accept a rich set of filters, sorting, and pagination from an API and then translate it consistently into SQL and NoSQL.
Query query = Querity.query()
// customize filters, pagination, sorting...
.filter(
not(and(
filterBy(”lastName”, EQUALS, “Skywalker”),
filterBy(”firstName”, EQUALS, “Luke”)
))
)
.sort(sortBy(”lastName”), sortBy(”birthDate”, DESC))
.pagination(1, 10)
.build();
The library provides an abstract API and its own query language that you can expose in a REST interface and then map to specific dialects (JPA, MongoDB, etc.).
curl ‘http://localhost:8080/people?q={”filter”:{”and”:[{”propertyName”:”lastName”,”operator”:”EQUALS”,”value”:”Skywalker”},{”propertyName”:”lastName”,”operator”:”EQUALS”,”value”:”Luke”}]}}’
For backend and API-layer developers, Querity can be a lifesaver: it removes the need to write custom code for each new filtering requirement, promotes clean architecture, and separates domain logic from persistence details. With add-ons (like integration with Spring Web/Spring Data) it drops nicely into existing projects. I’ll admit that out of all the projects mentioned today, this one has the highest chance of ending up in my own dependencies.
PS: This is probably the last “Rest of the Story” this year. December is going to come with a slightly unusual schedule 😁.
PS1: Happy Thanksgiving for the US readers!
PS2: Greetings from Amsterdam and Kotlin Dev Days 😊
