

June: The Rest of the Story - JVM Weekly vol. 135
The new edition of JVM Weekly is here and... and like always, there is a lot of "Rest" in "Rest of the Story".


This issue is sponsored by Bufstream - an innovative Kafka alternative focusing on Protobuf schema validation at the broker level. They invite you to a free workshop on July 10 to learn more about this technology.
TLDR: I’ve gathered many interesting links in June that didn’t make it into previous issues. Many aren’t extensive enough for a full section, but they still seem compelling enough to share. And to wrap things up, I’m adding a few (this month - a lot…) of releases and updates.

1. Missed in June

Usually, when a new JDK shows up, the talk is mostly about the JEPs (guilty as charged), but the changes reach much deeper, as Java picks up a ton of larger/smaller APIs and fixes. For example in JDK 25, built-in web server: jwebserver --directory now accepts relative paths, and CharSequence (and CharBuffer) gets a bulk getChars(int,int,char[],int) method, so you no longer have to cast to String when reading blocks of characters. Staying on that topic, the JDK will also get a system property stdin.encoding, so you can find out what encoding System.in uses without acrobatics, and in Javadoc we can enable --syntax-highlight, which bundles Highlight.js into the generated docs and highlights Java, JSON, or HTML snippets on the spot.
At the same time, jar --validate now warns about duplicates and suspicious entry names, and javac stops ever modifying JARs on the classpath, once and for all eliminating the “magical” artifact overwrites during compilation.

Meanwhile, from JDK 20 → 21 you could enable a richer, JLine-based java.io.Console ((JLine is a Java library for handling console input) and in JDK 22 it became the default. However, maintaining that implementation proved costly (issues with JLine updates, exotic terminals, and containers), so JDK 25 reverts to the old setting: System.console() again returns the “plain” console, and JLine is opt-in. If you need advanced line editing, history, or colouring, just start the JVM with the right flag.
The JSSE library gains TLS Keying Material exporters, so applications can generate keys for further protocols (RFC 5705/8446) without poking around in OpenSSL, JDK now cuts out SHA-1 from TLS 1.2 and DTLS 1.2 handshake signatures by default, and ML-DSA speeds up on AArch64 and AVX-512 by up to 2×.
As I wrote in the JEP roundup, the UseCompactObjectHeaders option comes out of hiding (no more UnlockExperimentalVMOptions), but I also learned that its old opposite, UseCompressedClassPointers, moves to deprecated-for-removal - time to remove it from your startup scripts. On top of that comes the deletion of the obsolete PerfData sampler and a series of clean-ups in certificates and Permission classes tied to the disabled Security Manager, thanks to which JDK 25 starts faster and has a smaller memory footprint.
Sticking with the theme, Erik Gahlin post What’s new for JFR in JDK 25 walks through the incoming JFR changes. Besides the JEPs we’ve already covered, I've realized I missed JEP 518: JFR Cooperative Sampling . Now I have opportunity to fix that error.
JEP 518 gives Java Flight Recorder a safer, lighter sampling method. Instead of a separate sampler thread pausing other threads at random to peek at their stacks, each thread now just drops a tiny "please-sample-me" flag. When that same thread soon reaches a normal safepoint, it records its own stack trace. This cooperative hand-off avoids forced pauses, reduces overhead, and keeps profiling stable.
This removes the risky heuristics, increases stability, scales better (the sampler does far less work), and still keeps safepoint-bias low, giving developers more reliable, low-overhead profiling data in JDK 25.
Apart of that, we’re getting a handful of CLI candy:
jfr scrubnow counts the events it strips out,jfr print --exactprints nanoseconds with no rounding,the
report-on-exitflag spits out a ready-made GC-pause or boot-time report as the JVM shuts down.
Cherry on top: the @Throttle annotation tamps down flood-level event spam, while @Contextual lets every lock carry the request context - debugging on easy mode.
And for dessert: tossing the Security Manager nuked ~3 000 lines of JFR code, so cold-starts are lighter and the dev team’s headaches fewer. All of this lands in JDK 25.
PS: Johannes Bechberger created experimental frontend that can be used to easily test JFR queries. You can find it on Github.

On 23 June, a commit prepared by Alex Shipilev added a markdown file with the disarmingly simple name Custom Schedulers to Project Loom’s fibers branch. The document walks you through replacing the default ForkJoinPool with your own Executor, letting you decide which virtual threads land on which carrier threads. It is the first public specification of the feature Ron Pressler talked about back in 2020 as “pluggable schedulers” — a flexible alternative to kernel-level time-sharing.
The linchpin is Thread.VirtualThreadTask, a Runnable that encapsulates a frozen thread state and is passed to the custom executor’s execute() method. When a carrier thread calls run(), the task “mounts” the virtual thread, restores the stack, and keeps going until the next blocking point; after an unpark, the scheduler receives the same task back.
Executor mySched = command -> { … };
ThreadFactory tf = Thread.builder()
.virtual(mySched)
.factory();Any thread created from that ThreadFactory obeys the scheduling algorithm you choose, whether it is single-core affinity or priorities derived from Scope Variables.
For anyone wondering whether someone can do better than classical work-stealing, the discussion on r/java suggests that frameworks like Quarkus or Netty could finally line up their I/O loops with the JVM’s scheduler, or enforce strict pinning-free policies for long-running jobs. It is only a draft for now, but the very fact that the API has landed in the repository is a green light for tailored-concurrency experiments well before JDK 26. Project Loom clearly still has a few words left to say.
What’s up Doc? Now it’s a time for a Carrot

Carrot Data the folks chasing “smarter caching” - quiet-released their code on 30 January 2025, turning Carrot Cache into an Apache 2.0 project on GitHub. The banner now reads “In-Out-Process Java cache (L1/L2 off-heap, ZeroGC) with full SSD support,”
The pitch is simple: in Carrot’s own benchmarks the cache needs 2–6 × less RAM than Caffeine or EHCache to hold the same object count - so if your heap is ballooning, it might be worth a look.
That head-room comes from a fully off-heap design. Metadata weighs just 6–20 bytes per entry, the store scales to 256 TB with only an 11 B/item overhead, and you can splice RAM with SSD in a hybrid tier. Writes are strictly sequential (DLWA ≈ 1.1–1.8), and a “Herd Compression” trick squeezes memory even further. Snapshots of the entire cache are touted as up to 150 × faster than Redis, chopping restart or migration time down to seconds.
Caffeine stays entirely on-heap, while EHCache still leans on BigMemory - both can trigger GC hiccups - so Carrot’s zero-GC angle is its calling card (Persona reference here!). Modes span RAM-only, SSD-only, hybrid, or tandem-compressed; eviction algorithms include Segmented LRU, LRU, and FIFO; and the Memcarrot side-project speaks the full text Memcached protocol out of the box. Minimum requirement is JDK 11, but the team warns that the beta digs into Unsafe.
Roadmap-wise, Spring Boot starters and deeper tiering experiments are already on deck, so the Java crowd just gained a carrot-coloured excuse for some high-performance cache tinkering.
Continuing with ultra-performant libraries - remember Apache Fury? It is - well, was, but we’ll get to that - an ultra-fast framework for serialising and deserialising data in Java. More details you will find in the old JVM Weekly edition:

According to project lead Shawn Yang, after a heated discussion with Apache Software Foundation Brand Management, Apache Fury has re-christened itself Apache Fory -“Fast Serialization Framework FOR You.”
The motive? Conflicting trademarks and a desire to dodge legal skirmishes, so a sound-alike name with a clean slate was chosen. It’s a textbook case of how even an Incubator project can stumble into naming hell, where a “minor touch-up” turns into a full re-brand of the codebase, docs, and comms channels.
Every JVM package had to migrate from org.apache.fury to org.apache.fory; classes like FooFury are now FooFory, and the GitHub repo lives at apache/fory. If you depend on Quarkus-Fury, Camel-Fury, or other wrappers, you’ll need to swap the artefacts or Maven won’t find the deps. The move should be painless—URL redirects are active, the old v0.10 docs stay online, and mailing lists are now on @fory.apache.org.
Still, it’s probably worth the hassle: Fory keeps all those “20–170× faster than Avro/Protobuf” benchmarks and pledges an uninterrupted release cadence, so if top-end serialisation speed matters to you, best to swallow the frog and migrate.
And talking about Protobuf…

…now, we’ll dive into Bufstream - a Kafka alternative that is worth your attention, especially because of its unique approach to schema validation right at the broker level. Having been deeply involved with Kafka for years and organizing the Kraków Kafka User Group, I usually meet new “Kafka-killers” with healthy skepticism. But Bufstream’s focus on enforcing Protobuf schema rules on every message before it even reaches consumers is something worth highlighting for anyone working with streaming data on JVM platforms.
Bufstream rethinks Kafka’s architecture by replacing traditional stateful brokers and expensive storage with stateless brokers that write data directly to S3-compatible storage in Parquet format, managed with Iceberg metadata. This allows near real-time querying via tools like Athena or Spark without connectors or data copying, while ensuring exactly-once delivery through careful metadata coordination in external databases like Spanner or Postgres. You can find a detailed technical overview of this architecture in their excellent blog post here: Cheap Kafka is cool. Schema-driven development with Kafka is cooler.
What truly sets Bufstream apart is its schema-driven validation: instead of just checking schema IDs like typical schema registries, Bufstream inspects every Protobuf message fully, enforcing strict validation rules. If any record in a batch is invalid, the entire batch is rejected at the broker level - no more downstream regex hacks or dead-letter queues to clean up messy data.
Moreover, Bufstream supports live redaction of sensitive fields and plans dynamic field-level masking based on role-based access control (RBAC), which is a game-changer for industries with strict privacy and compliance requirements.

If this sounds interesting, the Buf team will host a free workshop on July 10 showing how to implement schema validation in real-world streaming clusters. It’s a rare chance to see how schema-driven development can improve data quality, pipeline reliability, and compliance for JVM users. You can sign up here.
Disclaimer and FullTransparency (TM): this part was created as part of a paid collaboration with Buf, but no one looked over my shoulder - the only things they asked for were matters related to the Workshop and a referral link to the blog post, the rest is my own creation and result of digging around 😃. Moreover, they were fine with me writing about it, which for me is always a key topic before starting any collaboration, as those who disliked this condition have experienced.
And now, after the commercial break (always wanted to say that 😁) it’s time for a little Jakarta EE 11 curiosity: the release was formally closed on 17 June, the jakarta.platform:11.0.0 artifacts are already hanging out in Maven Central, but - according to Ivar Grimstad - the full-blown PR fireworks and the “official announcement” are only coming in the next few days. So, strictly speaking, the new platform has just “landed,” but nobody has cut the ribbon yet. By the time you read this, the headlines may have popped; I promise we’ll dive in right after the launch.
Lately I’ve been deep into ARM, so I can’t skip the news that Graviton 4 has just picked up fresh benchmarks from Azul. In his post Give Your Java Applications a Performance Boost with AWS Graviton, Frank Delporte notes that simply swapping vanilla OpenJDK for Zing (the heart of Azul Platform Prime) delivers about 30 % more throughput on r8g instances, and Graviton 4 itself can be up to 45 % faster than G3. Two environment tweaks sprint ahead before you touch a single line of code.
Some results look almost too good, yet they’re worth quoting. Between Zing builds 4079 → 4805 the authors squeezed out another 3.45 % just by updating the runtime, and on Graviton 4, Zing 21 beats OpenJDK 21 by 31.7 %. In a straight c7i.x86 versus r8g.arm matchup the delta is +9 % performance with –33 % annual cost.
The takeaway is clear: if your JVMs run on AWS and the compute bill is growing faster than you’d like, it’s time to give them ARM wings - preferably, Azul says, with a dose of Zing.
Here’s a real “rest of the story” moment. Only a week ago I wrote that TornadoVM had added support for Llama3.java, and now we already learn that the latest release brings the promised full support for Mistral 7B. That means you can run
./llama-tornado --gpu --model Mistral-7B-Instruct.fp16.gguf --prompt "tell me a joke"and watch an RTX gulp down the full 20 GB of VRAM. Don’t have a 20 GB card? The very same binary will start in plain Java on the CPU - no JNI acrobatics needed - just drop the --gpu flag.
And sticking with the AI theme, Ken Kousen , in the latest issue of his Tales from the jar side newsletter, recounts his appearance on Junie Live.
Together with Anton Arhipov, he showed on YouTube how JetBrains’ agent, in just a few rounds, gathers a project’s context, plans the refactor, and even runs the tests on its own - while he just watches and tosses out jokes. It’s a long, two-hour stream, but if you’ve got a couple of monitors it’s worth a look, because it goes well beyond a simple “hello world.”
Staying on the “agent” theme, Guillaume Laforge (yes, the Groovy-and-Google-Cloud guy) has published an ADK Java GitHub template that lets you clone a ready-to-run repo with a pom.xml, a HelloWeatherAgent class, and scripts for both the CLI and the web-based ADK Dev UI. In other words: a “Hello World” Gemini agent in five minutes - no Spring, no LangChain4j required.
The template is explained in a companion post on Medium, ties in with the official Google Cloud quick-starts and the growing adk-samples collection, and ships with clear README instructions for swapping in Gemini 2 Flash or deploying straight to Cloud Run. In LinkedIn comments (where I first spotted it), developers praise the “time-to-first-prompt,” so this looks like a neat way to get hands-on with ADK.
On 2 June Apple revealed that its global Password Monitoring service - the backend that scans billions of passwords a day for leaks - has had a full-on “organ transplant,” moving from Java to Swift.
The fresh codebase delivers +40 % throughput, keeps P99 latency under 1 ms, and - music to every FinOps ear - cuts almost 50 % of the Kubernetes cluster reservations thanks to a 90 % drop in RAM usage.
Apple engineers explain that even after heavy G1 GC tuning, the old Java 8 service still suffered from long pause times during traffic spikes and sluggish cold-starts. Swift, with deterministic ARC and an AOT binary, let them shrink each service from “tens of GB” down to “hundreds of MB.” Bonus: the codebase melted by 85 % of its lines, shifting the team from deep class hierarchies to protocol-oriented generics.
On Reddit, r/swift is buzzing that “Apple is finally pushing Swift beyond iOS,” speculating which server-side workloads might be next. Over on r/programming and r/java, the hot question is whether anyone benchmarked against a modern JVM - Java 21 with Virtual Threads isn’t mentioned - so some readers see the move as “we dog-food our own stack” marketing.

As always with a rewrite, the debate is how much gain comes from the language itself versus brushing cobwebs off a decade-old monolith. Some hail Swift’s leaner memory footprint as a game-changer; others counter that any green-field rewrite would shed weight. A few commenters note that Oracle’s 2023 license-gate may have nudged Apple toward its home-grown ecosystem - though Cupertino was already on OpenJDK, so it’s sending the thread into the familiar GC-vs-AOT and “my language vs. yours” skirmish (see the Slashdot roundup here).
So there you have it: conclusive, irrefutable proof that Java is - obviously - dead. 😉

But that’s not the end of Apple’s news. At WWDC25 the Apple Swift team unveiled the swift-java project: an open-source toolchain (JavaKit, SwiftKit, the swift-java CLI) that lets Swift and Java code interoperate in both directions without risky rewrites—you can add new Swift modules to an existing JVM app, or gradually adopt Java libraries in iOS/macOS projects. Konrad Malawski (greetings, ktoso—Kraków remembers!) compared the two runtimes (GC, classes, generics, error handling) and stressed that their similarities allow mapping most APIs almost 1 : 1.
It’s intriguing to wonder whether the whole effort was driven by the Password Monitoring migration mentioned earlier.

While demonstrating Java → Swift, Konrad showed a laborious JNI example and then the same function built with swift-java: the generator produced the declarations, the @JavaImplementation and @JavaMethod macros removed all boilerplate, and Gradle integration automatically pulled in dependencies (e.g., Apache Commons CSV). As a result, Swift could call Java methods, iterate over collections like native sequences, and use crypto libraries without touching C headers.
In the opposite direction - “Swift → Java” - swift-java generates, for an entire Swift package, a Java wrapper class using the new Foreign Function & Memory API (from JDK 22). Java can construct Swift structures inside SwiftArena contexts, and closing the arena (e.g., via try-with-resources) deterministically frees native memory, sparing the GC. The whole bundle is published as a JAR artifact that Java consumes like any other library.
The project is still experimental and is being developed on GitHub under the swiftlang organization.
A quick licensing tidbit: UK universities have just signed - via the Jisc consortium (a British non-profit that provides networking, IT services and digital resources to higher-education, research and the wider public sector) - a five-year framework worth up to £9.86 m (≈ €11.5 m) for Oracle’s Java SE Universal subscription. Under the deal they get an amnesty on any back fees dating back to January 2023 and a flat “per-head” licence rate instead of full list price - terms Jisc calculates will save the sector about £45 m overall. The agreement was hammered out after Oracle began sending individual universities letters threatening Java audits - buying in bulk was meant to head off multi-million-pound claims and simplify licensing across multi-campus institutions.
Reactions, however, are far from enthusiastic. Critics ask why academia didn’t switch to free OpenJDK builds, given Oracle’s new model counts every staff member and student - even those who never touch Java - potentially driving costs up as enrolment grows. Others note that although the sector dodged historical fees, it is still paying a “peace-of-mind tax” of almost £2 m a year, and they worry Oracle could raise prices or tighten usage definitions next time around. In short, Jisc’s decision serves as a warning: if you don’t track every JDK install, you pay - either the licence fee or the audit bill.
The author of the JediTermFX library posted a GIF of the legendary DOOM running… inside a JavaFX terminal. The trick was to pipe the “doom-ascii” port through the emulator, which renders characters on a Canvas; to enhance the effect, the background was set to #282828 and maxRefreshRate was bumped from 50 Hz to 80 Hz. The game does load more slowly, but the community unanimously agreed that swapping pixels for ASCII was worth it for the pure “wow” factor.
JediTermFX itself is a JavaFX port of the Swing-based JediTerm from JetBrains. Thanks to its pure-JavaFX components, it can be dropped into any desktop app as a fully fledged terminal emulator. The DOOM demo is therefore meant more to showcase the library’s flexibility than to aim for a speed-run - but it still sparked a lively discussion that JavaFX can still surprise.
And to wrap things up - still (surprisingly) on-topic… KotlinConf!
JetBrains has posted full recordings of more than a hundred sessions on the conference site. You can filter the playlist by day (22 and 23 May) and by theme: server-side Kotlin with Spring Boot 4, Wasm-Compose, agent-powered LLMs in LangChain4j, Valhalla-ready immutability, KMP inside Google Workspace, or a case study on migrating millions of lines of Java → Kotlin at Uber.
I already did a KotlinConf roundup a few weeks ago, but since the chance has come up, let me drop in the recording of my own talk:
Highly recommended are the last three minutes—playing Super Mario Bros. live on stage at KotlinConf, in front of hundreds of people, on an emulator I built myself… easily the highlight of my entire speaking “career.”
2. Release Radar

Kotlin 2.2
And we smoothly kick off the Release Radar with Kotlin 2.2!
The new release ships stable versions of three previously experimental features - each best shown with a short example:
Guard conditions in when:
when (user) {
is Admin && user.active -> grantAdminAccess()
is Guest -> showSignup()
else -> showHome()
}Non-local break / continue:
outer@ for (row in board) { // not a fan of this syntax :P
for (cell in row) {
if (cell == null) continue@outer // skip the whole row
}
println("Full row: $row")
}Multi-character interpolation (multi-$):
val json = $"{{ \"name\": ${user.name}, \"age\": ${user.age} }}"Thanks to these, you can write DSLs and validators without piles of else braces, and matchers become much more readable.
As a bonus, the long-awaited context parameters mechanism enters Preview - successor to context receivers, allowing you to inject dependencies without a full-blown DI framework:
context(Database, Logger)
fun <T : Entity> T.save() = transaction {
log("Saving $this")
db.insert(this)
}Sounds like “lightweight DI without a framework” - and that’s exactly how it works.
Interesting things are also happening under the hood. By default, every default body in an interface now ends up in a real JVM default method (you can disable this with -jvm-default). The byte-code generator already supports the Java 24format, and the new -Xwarning-level switch lets you raise the sensitivity of all warnings at once - from “quiet” to “treat as error.” The kotlin-metadata library can now write annotations on its own, without manual signature mangling—greatly easing life for APT and KSP authors.
The standard library stabilizes the Base64 API (now four variants, including Pem) and HexFormat. In addition, the compiler now enables the OptimizeNonSkippingGroups flag by default, removing hundreds of unnecessary recomputations in Compose and other reactive libraries. The brand-new Build Tools API debuts - a layer separating the KGP plugin from the compiler version; you can therefore run the project on KGP 2.2 but compile code with engine 2.1 or nightly 2.3 without breaking the entire CI.
Additionally, the new release sees Kotlin say goodbye to Ant support, removes the kotlin-android-extensions plugin, and replaces the kotlinOptions{} block in Gradle with compilerOptions{} (the old call now raises an error). The REPL hides behind -Xrepl, and several deprecated Native plugin properties (including destinationDir) head to the trash.
Spring Modulith 1.4
Now it’s Spring Modulith’s turn. If the name doesn’t ring a bell, it’s a toolbox for building modular monoliths on Spring Boot that enforces module boundaries, generates relationship diagrams, and helps you test domain behavior.
Its latest 1.4 release cranks up Spring’s modular heart: ApplicationModule(s) and the documentation generator have been improved, an SPI was added for automatic discovery of @NamedInterface, and a fix in JavaPackage removes the annoying “bouncing” between packages. Integration tests using @ApplicationModuleTest can now inject beans straight from the src/test directory, and if AssertJ is on your classpath, global PublishedEvents become instantly assertable (ah, that Spring magic).
Performance is up in the event-publication registry, which now distinguishes structurally identical events, and the runtime has moved to Micrometer Observations, giving you automatic ModulithEventMetrics counters with zero extra code (did I mention that lean magic?). The release also bumps Spring Boot to 3.5, Spring Framework to 6.2, and ArchUnit to 1.4.
Vaadin 24.8
The headline feature in Vaadin 24.8 is the preview of Signals - declarative state management that automatically refreshes the view when the model value changes. Add to that a simplified file-upload and download API, so the logic boils down to a single method call. On the component side the Flow Card becomes official, and Grid i18n is on the way. Meanwhile, the Modernization Toolkit now covers roughly 80 % of typical Vaadin 7 applications, making legacy migrations (almost) painless.
From a DevEx standpoint it’s worth noting the revamped backups in Control Center based on CloudNativePG. The skeleton project from 24.8 ships with ready-made TestContainers integration and a default security configuration.
Quarkus 3.23
Quarkus 3.23 brings two headline features. Hibernate Reactive can now work with named datasources, meaning the reactive ORM finally matches its classic sibling for multi-database setups and lets you route traffic to specific connection pools with a single entry in application.properties.
The other big addition is OIDC Bearer Step-Up Authentication - an OAuth 2.0 draft implementation that lets endpoints demand a higher Authentication Context Class Reference (ACR) level and automatically return an insufficient_user_authentication challenge when the token is too weak. In practice, a single-page app can prompt the user for an extra FIDO factor only for critical operations, while the backend handles the protocol. As a bonus, there’s a complete set of examples in a new subsection of the OIDC guide.
Ktor 3.2.0
Ktor 3.2.0 packs in a host of long-awaited improvements: a built-in DI module (coroutine-friendly, with automatic closing of AutoCloseable resources and optional integration with Koin 4.1), a new HTMX plugin that lets you add attributes and routes without extra HTML glue, and YAML/HOCON configurations that can now be deserialized directly into data classes - eliminating manual mappings. Gradle users get a version catalog alongside the Maven BOM, and “suspend modules” allow complex dependency graphs to initialize asynchronously and in parallel.
From an operational perspective, the biggest change is Unix domain socket support in the CIO engine, eliminating TCP overhead for processes on the same host - just call unixConnector("/tmp/app.sock") on the server side and unixSocket() on the client. The release also brings official templates on start.ktor.io with ready-made configurations for DI and HTMX.
MicroProfile 7.1
MicroProfile 7.1 landed on 17 June 2025 and is largely a minor update: it brings Telemetry 2.1 (runs its TCK on JDK 23 and tidies up thread-count metrics) plus OpenAPI 4.1 with compatibility fixes for specification 3.1. The rest of the platform is unchanged - still Config 3.1, Fault Tolerance 4.1, Health 4.0, JWT 2.1, Rest Client 4.0 -and the minimum requirement remains Jakarta EE 10 Core Profile on Java 11+. Any runtime that passes the aggregate TCKs can immediately declare compliance with 7.1, and the first certified implementation is Open Liberty 25.0.0.7-beta.
Powertools for AWS Lambda (Java) 2.0.0

We’ve also welcomed a brand-new release of Powertools for AWS Lambda. Version 2.0, announced by creator Philipp Page, doubles down on deeper integration with the Java ecosystem: the completely redesigned Logging Utility now uses the native SLF4J API with a choice of log4j2 or logback, streamlining MDC handling and letting you attach structured fields without custom helpers. The Metrics Utility catches up with its Python, TypeScript and .NET siblings (new @FlushMetrics annotation, MetricsFactory.getMetricsInstance() factory), while Parallel Batch Processing can spread SQS/Kinesis/DynamoDB Streams items across threads, automatically carrying over the logging context.
There’s also modularization of Idempotency and Parameters (smaller packages), retirement of powertools-sqs in favour of the generic batch module, and a bump of the minimum Java version from 8 to 11—shrinking the overall artifact size.
P.S. Vadym Kazulkin has put together a set of samples for Powertools, and they’re a great showcase of what the project can do. Highly recommended as a dessert read!
CheerpJ 4.1
And to wrap things up, CheerpJ—the WebAssembly-based JVM for the browser—has released version 4.1. Despite an earlier roadmap pointing to 5.0, this update already delivers a preview of Java 17 support, with the final version still slated for later this year. The package also brings full SSL and audio for Java 11 mode, an improved networking stack, better mobile usability for Swing/AWT, broad performance optimizations, and a handful of bug fixes. Thanks to community feedback on 4.0, overall stability has improved and critical Java 11 issues have been ironed out, so upgrading is as simple as bumping the loader version and clearing the browser cache.

The project’s flagship demo remains Browsercraft - an unmodified Minecraft 1.2.5 that runs in the browser via new JNI WebAssembly modules capable of loading native LWJGL and OpenGL libraries on the fly.
This proves CheerpJ can handle heavyweight desktop applications and lets you mix Java and JS in Library Mode without recompilation. The tool stays free for FOSS projects and solo developers, and the team has queued up stable Java 17 support, NPM integration, and additional JNI-Wasm layers for future releases.
3. Github All-Star

HeliBoard
Let’s start with an Android project that’s both niche and fascinating - and it just dropped a new release. HeliBoard is a fork of OpenBoard that has become the most popular “zero-cloud” keyboard - the app doesn’t even request Internet permission, so no keystrokes ever leave your device. On top of that it’s fully customizable: you edit layout files yourself, tweak themes to match Material You, add custom dictionaries or emoji, and back up your settings with a single tap. It’s a keyboard for nerds and security freaks alike, and I recommend browsing the code - I did once and found tons of clever solutions in there.
Kestra
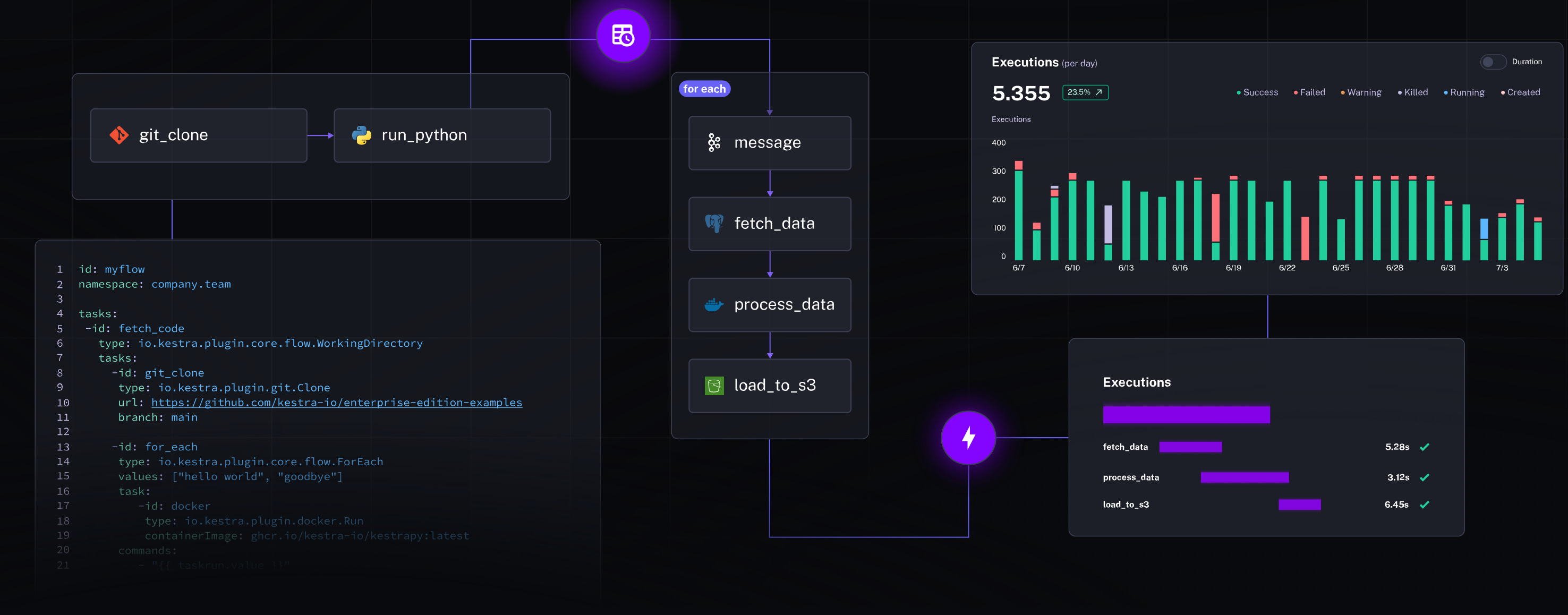
Kestra is a written-in-Java, event-driven orchestrator that blends IaC-style YAML with a handy UI: you define flows in just a few lines and then run them - either on a cron schedule or in reaction to events - without writing Python like most competitors require. The platform runs on-prem, in the cloud, and in multi-cloud mode, letting you scale each component independently because the whole thing is built on microservices. It ships with key plugins (SQL, Airbyte, dbt, GraphQL, LangChain4j, Salesforce, and dozens more), versions everything via Git-Ops, and benefits from JVM speed - which is why TechCrunch once called it “Terraform for workflows.”
The latest 0.23 release (17–19 June 2025) adds a Multi-Panel Editor with Code / No-Code switching, an all-new form-based flow editor (good-bye mandatory YAML), and flow unit tests that you can run right from the UI. So if you’re after an orchestrator that combines Java’s speed with “draw-and-run” convenience, Kestra is quickly becoming a ⭐ - and not just on GitHub.
MCP for Beginners
Time for something purely educational!
A week ago Microsoft dropped a full, open-source Model Context Protocol (MCP) for Beginners course on GitHub—a standard that lets AI agents talk to external APIs, databases, or files instead of staying stuck in an “LLM cage.” The repo has already racked up 4 000 + stars and nearly a thousand forks, offering lessons in five languages: C#, Java, TypeScript/JavaScript, and Python. The tagline? “From zero to your own MCP server without spending a dollar.”First you learn the architecture and messaging, then spin up your first server, and finally build a client that plugs in LLMs and debugs everything with the inspector.
The material is organized into clear modules 00 – 10—from the intro and security to “Lessons from Early Adoption” and an Azure AI Travel Agents case study. The source includes ready-made samples, a set of Dockerfiles, translations auto-updated by GitHub Actions, and an active Community Hub/Discord where Microsoft runs an “AI Repo of the Week” series focused on MCP—so support and the roadmap are as lively as the protocol itself. If you want to add the buzzword agentic systems to your résumé or build your own Copilot-style workflow, this repo is the perfect starting point.
JVM Rainbow
To finish, something truly unique from the “don’t try this at home” genre.

“One app, four languages” sums up JVM Rainbow, a fresh example from Hakky54 showing how to make Java 21, Kotlin, Scala 2.13, and Groovy coexist in a single Gradle project. Part of the java-tutorials collection, it answers the classic question: Can you mix languages without separate modules? Each language is compiled by its own task, and the class files land in a shared build/classes directory; thanks to the order declared in build.gradle.kts, all the code sees each other—Kotlin can call Scala, Groovy can call Java, and vice versa.
The project walks you through multi-language compilation setup (plugins org.jetbrains.kotlin.jvm, scala, groovy), shows how to resolve class conflicts, and sets a common byte-code target. The README guides you through each language’s configuration, while the tests demonstrate Java/JUnit 5 invoking Groovy functions and ScalaTest exercising Kotlin services. For teams facing migration (e.g., gradually rewriting Groovy to Kotlin) the repo is a ready proof-of-concept: open it in IntelliJ, run ./gradlew test, and the whole polyglot package bundles into a single JAR - no module circus or multi-stage CI required. If you’ve always wanted to play with the full JVM language palette but didn’t know where to start, JVM Rainbow is definitely worth a look.
You probably know that the ending of this edition can be only one:
See you next week!
awesome article
What jokes? Oh, you mean like this one?
AI walks into a bar.
Bartender: What’ll you have?
AI: What’s everybody else having?
(Rimshot)
Bartender: I don’t know. Want me to ask around?
AI: No, just give me the WiFi password.
(Rimshot again)