

July: The Rest of the Story - JVM Weekly vol. 139
The new edition of JVM Weekly is here and... and like always, there is a lot of "Rest" in "Rest of the Story".


I’ve gathered many interesting links in July that didn’t make it into previous issues. Many aren’t extensive enough for a full section, but they still seem compelling enough to share. And to wrap things up, I’m adding a few (this month - a lot…) of releases and updates.
Today’s theme will be mountain‑inspired, because in my mind I’m still in Szczyrk 😁.
1. Missed in July

And today we’re kicking off with something delightfully out‑of‑left‑field — a programming language… and not even one that runs on the JVM 😉.
But straight to the point:
Jank is an experimental programming language that tries to marry Lisp‑style syntax with the speed of native machine code via LLVM. The main idea is to let devs write in a style familiar from Clojure (which the author cites as his inspiration — so now you know why it landed on my radar) but deliver performance closer to C++. Jank’s design approach is refreshingly pragmatic: it doesn’t aim to be a “pure,” academic Lisp dialect, but a practical tool for writing expressive code.
The project isn’t brand‑new, but I recently stumbled upon it and got intrigued enough to share - apparently that Clojure soul in me is still alive and kicking.

Jank is very much a love letter to Clojure - borrowing its syntax, semantics and overall programming philosophy. It has a REPL‑centric workflow, S‑expressions, macro support, and the whole “code as data” vibe. What’s more, Jank’s author, Jeaye Wilkerson, was an active Clojure user, which shows in the effort to stay as compatible as possible - many idioms and patterns you know from Clojure work straight out of the box in Jank. It also inherits plenty of functional goodies like immutability and persistent data structures.

While Clojure is famously expressive and has won a loyal following in the functional world, its big pain point has always been raw performance - like it or not, the numbers speak for themselves. Jank keeps the spiritual and syntactic closeness to Clojure but compiles to native machine code (thanks to LLVM), widening the range of use cases. Most of you probably haven’t heard of it yet simply because the devs still have some miles to cover - but the GitHub repo shows very active work.
When the alpha release drops, you can bet I’ll come back to this topic.
So, since we are already on the topic of JVM languages, we will have a series of Kotlin novelties and we will start with FlowMarbles.
For those who are not familiar - Kotlin Flow is part of the kotlinx.coroutines library, enabling reactive programming based on the so‑called cold streams – a sequence of data emitted over time that starts only after subscription. Flow supports all the “cool” things from reactive programming: asynchrony, back‑pressure, data transformations (e.g. map, filter, flatMapConcat) and error handling. Additionally, it uses coroutines, so it is lightweight and integrates well with idioms and libraries typical for modern Kotlin. At the same time, due to the fact that it uses the Reactive Streams model, reasoning about ordering can be complicated. But fortunately, there are appropriate tools that can help us understand how Flow works under the hood.
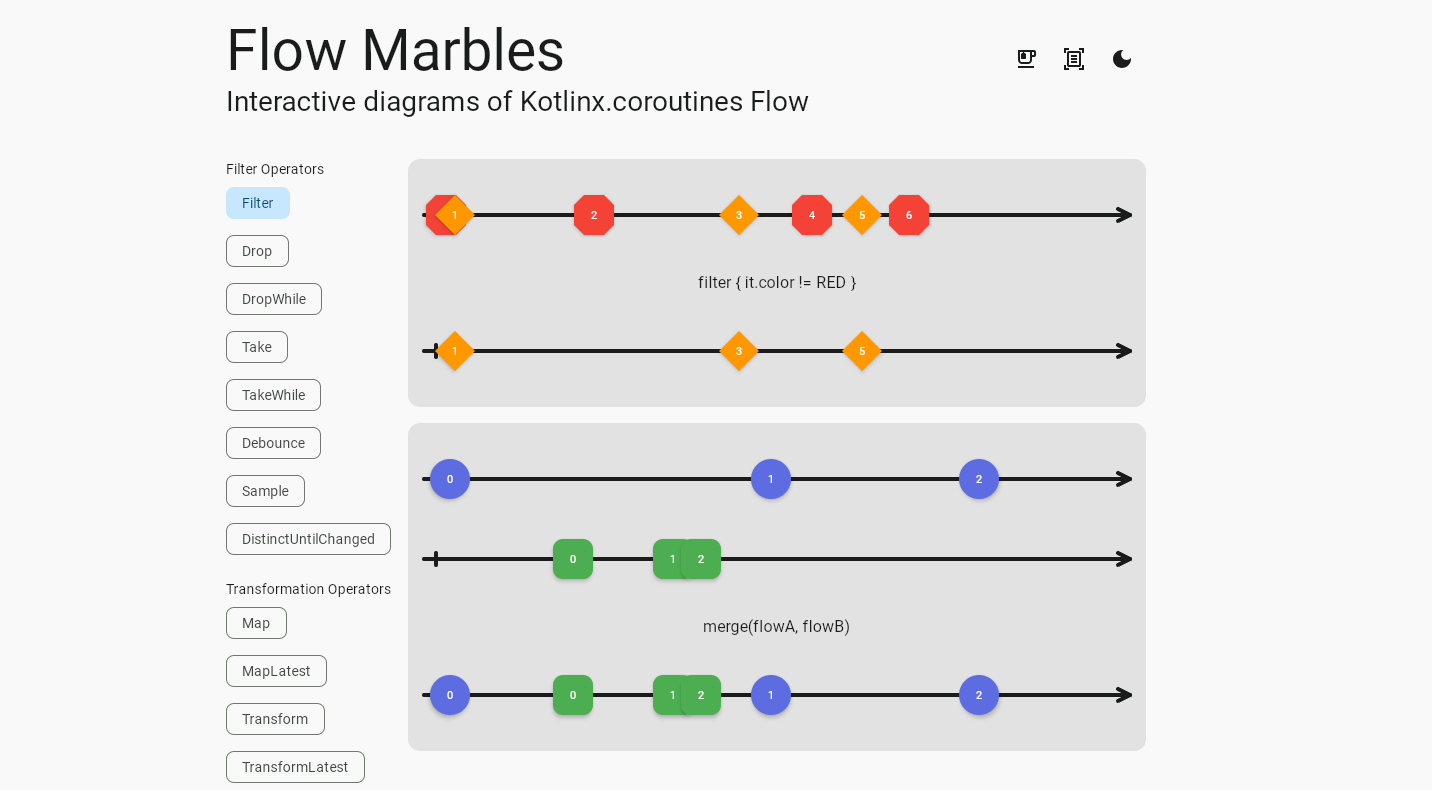
FlowMarbles is an interactive tool created precisely for visualizing the operation of Flow, using marble diagrams to present the behavior of stream operators. The user can choose a specific operator (e.g. Debounce, Merge, FlatMapLatest), and FlowMarbles will show step by step how data flows through the stream and in what way it is transformed.
Thanks to this, instead of only reading documentation or experimenting in code, one can intuitively “see” Flow’s behavior over time — which can be invaluable when we delve deeper into asynchronous APIs and want to understand nuances such as queuing or canceling previous subscriptions.
The inspiration for FlowMarbles was the now‑cult RxMarbles, the operator visualizer from the RxJS library. It was precisely this tool that popularized the idea of marble diagrams in the reactive world. It is also worth mentioning the tool from SoftwareMill - Kafka Visualization - which translate this concept to Apache Kafka, showing how messages are sent between producers and consumers, taking partitions and offsets into account. These tools share a common goal: to make complex reactive or streaming systems easier to understand through simple and attractive visualizations. It’s nice that we have a Kotlin‑oriented implementation.
And that’s not the end of Kotlin’s innards. JetBrains Research published in July the article Fuzzing the Kotlin compiler (JetBrains Research), in which they describe the application of fuzzing techniques to testing the Kotlin compiler – including the new K2 version. Fuzzing involves feeding random, incorrect, or unexpected input data to trigger unforeseen exceptions, compiler crashes, or incorrect code generation – issues that traditional tests often miss. The project was developed in collaboration with TU Delft and uses advanced approaches such as generative fuzzing (based on evolutionary/genetic algorithms) and mutate‑based fuzzing, which made it possible to uncover numerous critical bugs, e.g., in K2.
This complements JetBrains’s earlier work under the kotlinx.fuzz project, which originally focused on fuzzing Kotlin‑written libraries, particularly ones like kotlinx.serialization or collections. There, they created a user‑friendly API, a Gradle plugin, and a JUnit engine to write fuzz tests directly in Kotlin and automate result analysis. As a result, both stages – fuzzing the Kotlin tooling ecosystem and the compiler itself – showed that this approach can reveal subtle bugs in library functions, the parser, and code generation that standard tests overlooked.
JetBrains (a lot of JetBrains news) also announced a new Unified Distribution Plan for IntelliJ IDEA, which aims to simplify the distribution and licensing model by merging the Community and Ultimate editions into a single, unified IDE. Instead of two separate installers and environments, users will download one version of IntelliJ IDEA that includes all features by default but activates only those appropriate to their license - free (Community) or commercial (Ultimate).
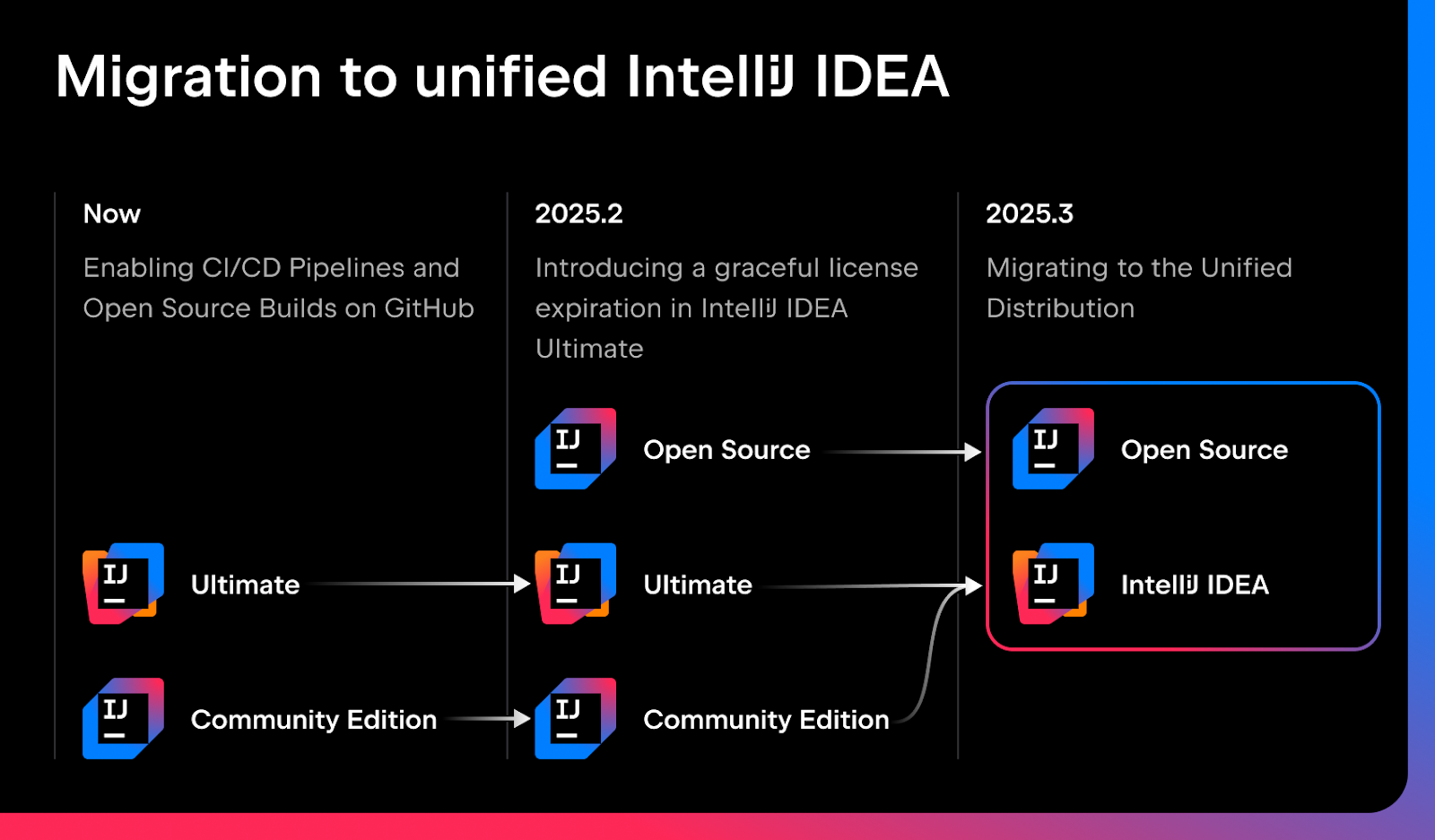
Thanks to this, JetBrains wants to reduce fragmentation, make IDE deployment easier in corporate environments, and enable smoother transitions between editions without the need for reinstallation. The new model does not change the licensing terms or the open‑source nature of the Community edition, but brings the approach closer to that known from other editors, where functionalities are enabled dynamically based on configuration and permissions.
Kotlin Foundation announced the start of the 2025 Grant Program, whose goal is to support open source projects, educational initiatives, and tools developing the Kotlin ecosystem.
Within the program, one can obtain funding for the development of libraries, integrations, training materials, or community activities – especially if they align with the foundation’s strategic goals, such as Kotlin adoption beyond Android, improving ergonomics, or developer tooling. Perhaps some readers will be interested in applying (and if you have something interesting, let me know too - I’ll gladly give you some space in the newsletter).
And now we move on to Java… well, kinda 😁
WASM the hard way - porting the Chicory compiler to Android, which I wanted to share with you, describes porting Chicory - a purely Java WebAssembly runtime, one of my favorite community projects - from the JVM to Android’s ART. Because Android executes DEX (Dalvik) bytecode, not JVM bytecode, simply generating JVM classes on the fly doesn’t work for dynamically loaded Wasm modules. Edoardo Vacchi therefore built a new Chicory backend - chicory-compiler-android - targeted at Android, which emits DEX directly on the device using DexMaker, adapting the JVM’s stack model to ART’s register model.

A simple fixed-register assignment strategy was used (accepting extra moves and non‑optimal register usage) to keep the compiler in check, and for modules known ahead of time the JVM compiler is still used at build time. On the runtime side, the team encountered Android’s stack and memory limits (e.g., the default 1 MB thread stack and large Intermediate Representations in DexMaker). Workarounds include offloading heavy tasks from the main thread, splitting generated classes into smaller chunks (about 200 methods per chunk), and falling back to the interpreter for very large functions.
The project is still under development, but it makes for a very interesting low‑level article - and the current implementation was enough to pass the spec tests and run a real module - the “fetch” servlet on mcp.run. So you know, production ready 😁
OCI Generative AI is a fully managed Oracle Cloud Infrastructure service that makes the latest language models (including Meta Llama and Cohere Command - “sleeper” of models targeted for agentic applications) available to enterprises via console or REST API, allowing them to generate text, conduct conversations, create embeddings and – if needed – fine‑tune models on isolated GPU clusters.
Daniel Kec from the Helidon team announced that these capabilities are being brought directly into the LangChain4j ecosystem and the Helidon framework: new classes OciGenAiChatModel / OciGenAiStreamingChatModel (for Llama models) and their counterparts for Cohere allow calling OCI Generative AI services just like any other LangChain4j backend, and thanks to the aforementioned GPU clusters the solution is suitable for production hosting and fine‑tuning scenarios, opening the way to further Helidon integrations with RAG tools and AI agents.
And now something for those who are currently looking for a job.

The article I cracked 5 senior Java interviews in 30 days — my complete battle‑tested strategy is the author’s account of the preparation and approach that allowed her to “crack” five Senior Java interviews in 30 days - including at Amazon, Infosys, Capgemini, TCS, and Cognizant. The main thesis: at the senior level, what matters is not encyclopedic knowledge of details like “how a HashMap works,” but what you have actually built, scaled, debugged, designed, and led. The author promises specifics: sample questions, design scenarios, leadership threads, and elements of the interviewers’ “psychology.”
The text is aimed at people with roughly 8–10 years of experience who, between deadlines, are looking for a clear preparation plan and want to better understand the expectations placed on seniors. It describes which topics and behaviors make a difference when evaluating a candidate at this level and how recruiters view them - so that you can stand out from among 1,000 similar Spring Boot Developer CVs.

Another listicle - I reviewed 500 pull requests — here’s what every Java dev gets wrong - is a brief report based on over 500 Java PR reviews, written not to “call anyone out,” but to name the most common slip‑ups and suggest simpler, more predictable patterns. The article contains 12 tips that are worth at least skimming - and even if I’m not a fan of clickbait titles, you might find something useful in there for yourself.
And finally in this section, OmniFish, who described in the article Big changes in Maven Central the significant changes in how Maven Central works. Until now, publishing to Maven Central required using a staging system (e.g., OSSRH and the Nexus Staging Maven Plugin), which allowed artifacts to be “deployed” for verification before reaching the public repository. Now Sonatype is introducing a simplified model in which staging is removed in favor of direct publishing, which greatly speeds up the entire process but at the same time deprives teams of the ability to manually approve versions or inspect issues before publication.
These changes – although intended to simplify and automate the workflow – have caused a great upheaval in the community. The disappearance of classic staging means the loss of visible metadata, more difficult debugging of publishing errors, and unintuitive behavior in multi‑module projects. OmniFish, as the maintainer of the OmniFaces project and an active participant in the Jakarta EE ecosystem, warns that the change was implemented without sufficient documentation and migration tools. Moreover, teams publishing from GitHub Actions may be surprised by the unexpected lack of control over the process, making this “progress” (it’s kinda is as it will lower the barrier to entry for new projects) a rather risky move for many mature open‑source projects.
2. Release Radar

Koog 0.3.0
Koog is an open, Kotlin‑based framework for building AI agents – from simple “single‑run” to complex call‑strategy graphs – running in the JVM/KMP ecosystem and written in idiomatic Kotlin. It offers a DSL for defining behaviors, tool support (including MCP), streaming, history compression, tracing and memory, and on top of that is multiplatform (JVM/JS/WASM). The goal is clear – so that JVM developers get a full set of programmable “building blocks” for agents without having to escape into other languages or services (like Python).
In the new 0.3.0 release the project formalizes which capabilities a given LLM model supports (e.g. Tools, ToolChoice, JSON Schema, Vision, MultipleChoices, Moderation, Audio) and maintains its own map of these for providers (Google, OpenAI, Anthropic, Ollama, OpenRouter). Release 0.3.0 also expands the practical reach of the features: agent persistence appears (checkpoints/restore), durable vector document storage* for RAG, native OpenTelemetry and moderation built into the framework, parallel execution of graph branches (i.e. parallelizing our “agents” work), ReAct + Retry pattern support and multiple‑choice reasoning on the model side. There are also new integrations: image input from Ollama, full WASM (running in the browser) and Amazon Bedrock – all tied together with a “capabilities” layer to write model‑agnostic code, and have behaviors (tools/vision/schema) predictable across providers.

Koog is a young project, but already you can find some publications on the topic. John O'Reilly showed an end‑to‑end scenario with Koog + MCP: the agent fetches emission data (ClimateTrace), generates Compose UI code and - via the JetBrains MCP server – adds files to an Android Studio project, with concrete tool calls visible in the logs; the whole thing was driven by the Gemini model. On the other hand, Denis Domanskii from the JetBrains team described an interesting anti‑pattern “addiction to tool‑calling” dynamic in the post When Tool-Calling Becomes an Addiction: Debugging LLM Patterns in Koog: after dozens of messages, the model would always call tools, ignoring the request to summarize - the workaround was to gather history into a single “block” (changing the conversation structure) instead of adding instructions. This insight made its way into Koog as an automation in RetrieveFactsFromHistory and shows how much magic still lives in agents.
Micronaut 4.9.0
The new Micronaut 4.9.0 is mainly a modernization of the core framework: moving to Netty 4.2 brings a newer allocator and better I/O diagnostics, and the optional Event‑loop Carrier mode allows running virtual threads without abandoning the proven Netty model – easing migration from reactive to “loom‑style” code. Added to that are new annotations: @ClassImport lets you treat compiled classes as if they were sources, and @Mixin introduces a safe way to “stitch on” annotations (for now in Java). More stable serving comes via native HTTP/3 support, a new Graceful Shutdown API and a fluid CacheControl API, and Kotlinists can now build on KSP 2 and Kotlin 2.0. Finally, Micronaut Data implements the brand‑new Jakarta Data 1.0 specification, so CRUDs and queries are more standardized regardless of the chosen backend.
The second pillar of the release is updates in the module ecosystem. An experimental ProjectGen appears – an API for generating full Maven/Gradle projects, which will speed up scaffolding and onboarding, and Micronaut gRPC gains the ability to accept ProtoBuf messages in JSON form over HTTP 1.1. The cloud layer has been refreshed: AWS SDK, a new micronaut-azure-tracing module for Azure Monitor, updates for GCP, Oracle Cloud and a bundle of database, Reactor, Nimbus JWT, Logback, Spring 6.2.8 or Infinispan dependencies also got fresh BOMs.
Simply…

Async Profiler 4.1
Async Profiler is a low‑overhead, sampling JVM profiler that doesn’t suffer from the safepoint sampling bug; it sees both Java and native/kernel stacks, can profile CPU, allocations and (for some time) native memory, and generate JFR or flame graphs. It works with HotSpot/OpenJDK and can also trace non‑Java threads (GC/JIT), making it a good tool for diagnosing the “full” runtime, not just the application code.
Version 4.1 brings primarily experimental support for the OpenTelemetry profiling signal (OTLP output format and dumpOtlp API, plus a JFR → OTLP converter), JDK 25 support and “production‑grade” polishing of native memory profiling: full nativemem on macOS, jemalloc support and visibility of allocations inside the profiler itself. Added to that are quality‑of‑life improvements: automatic JVM detection in non‑Java processes and attaching to it, a native API for adding custom events in JFR, the --all option (collecting the maximum set of events at once), recording which CPU the sample was taken on, better leak‑detection heuristics (ignoring the last 10% of allocations), --fdtransfer support for kprobes/uprobes and fixes for ARM64 stack unwinding.
At the same time, Johannes Bechberger published ap‑loader 4.1‑10 – a new version of the project that packs all async‑profiler binaries into a single JAR and provides a simple interface (including javaagent mode and programmatic use with jattach).
In this release it was aligned with async‑profiler 4.1, dropped support for <4.0, refreshed JFR conversion support and cleaned up the code – making it easier to plug the newest profiler into custom tools, CI or applications without juggling native libraries per platform.
EclipseStore 3.0
EclipseStore began as MicroStream – a lightweight, pure‑Java persistence layer that stores objects exactly as they live in memory, without O/R mappings or a separate query language. Version 1.0.0 in 2023 was a technical “re‑branding” of MicroStream 8.1.1 under the Eclipse Foundation umbrella. Since then, the 2.x releases have added, among other things, re‑entrant locks for concurrency control, an object‑lifecycle observation API and a package of stability fixes, laying the groundwork for today’s big leap.
Released earlier this week, Eclipse Store 3.0.0 brings several strategic novelties. Besides the flag‑ship GigaMap (more on that shortly) there is storage-graph analysis – a diagnostic tool that can export just the structure (without data), find missing objects or “orphaned” references and suggest recovery steps, dramatically shortening post‑mortem time after a failure. At the same time, Eclipse Data Grid debuts – a separate project configured “infrastructure‑as‑code,” allowing you to run EclipseStore clusters in Kubernetes and take advantage of horizontal scaling without sacrificing the ACID event log. In practice this means the same object model can now smoothly move from a single JVM to a multi‑node grid while preserving the existing API semantics.
But GigaMap is the most important 3.0 feature. It is a specialized collection mapping keys to objects using an off‑heap bitmap index. The index is stored off‑heap, so it bypasses the GC and allows lightning‑fast lookups even in billions of records. On first access GigaMap automatically, lazily loads the requested object and its subgraph, minimizing RAM and application startup time; the remaining entries are represented only by identifiers until actually used. Since the integration is transparent, you can substitute the collection in place of any Map<K,V> in your domain model, and EclipseStore will handle synchronization and transactional consistency. The result is real‑time cache/analytics at a fraction of the memory and I/O cost, without manual reference management or custom indexing structures.
3. Github All-Star

Inferkt
We start with a mix of Kotlin and AI. InferKt is a Kotlin Multiplatform binding to llama.cpp, providing a single, shared API for running LLM models locally on Android and iOS - without any server or network connection. The library lets you, in just a few lines, load a .gguf model, set up parameters, and invoke inference (completions or chat), with events emitted as a stream, token by token. Additionally, it supports GPU acceleration on iOS via Metal.
kflite
Another similar project is kflite by Shadman Adman, also a Kotlin Multiplatform library, which this time lets you run TensorFlow Lite (LiteRT) models by loading .tflite files from resources (via composeResources)—without writing per‑platform glue code. On iOS you only need to include the TensorFlowLite CocoaPods.
kotlinx‑serialization‑csv‑durable
Staying in the Kotlin world - this time without AI (well, maybe a bit) - here’s a handy ETL building block.
kotlinx-serialization-csv-durable is a CSV format implementation for kotlinx.serialization, designed to be “durable”—it also handles tricky cases like nested objects, lists/sub‑lists, and polymorphism. When data structures can’t be unambiguously mapped to columns (e.g., a variable number of elements), the library automatically writes that field as a string (by default JSON) as a safe fallback. The parser tolerates non‑standard CSV (different line endings), and the encoder/decoder can work as a Sequence stream, making it suitable for larger datasets.
I’m honestly surprised pure CSV can handle all that 😅
What it gives developers: pain‑free exporting/importing of complex data classes to CSV, preserving all data. Simple fields become columns (e.g., year, make, model), nested fields flatten with dots (e.g., owner.name), and lists use indices (e.g., packages.0, packages.1). Anything that can’t be deterministically flattened ends up in a JSON fallback column—so nothing is lost and you don’t need custom adapters, at least for a first‑pass import.
Kappa
Kappa is an OpenAPI 3.1 validation library, the successor to the now‑archived openapi4j. It allows you to validate HTTP requests and responses against your API spec (OAS 3.1) using a JSON Schema draft‑2020‑12 validator. There are ready‑made integrations for Spring (configuration/filters, test annotations) and adapters for Servlet API, Undertow, Vert.x, RestAssured, and more.
If you work contract‑first, you can enforce spec compliance at runtime (e.g., in a filter) and in contract tests/MockMvc, catching drift between code and spec and breaking changes in CI. A single source of truth (OpenAPI) becomes a quality gate: fewer hand‑rolled assertions, consistent error messages, easier negative tests, and lower risk of client/server miscommunication.
ForceTerm
ForceTerm is a cross‑platform Java terminal emulator built on JetBrains’ jediterm (the library behind IntelliJ/Android Studio terminals). The app runs on Windows/macOS/Linux, features a modern Swing UI (tabs via JTabbedPane, keyboard shortcuts, light/dark themes via FlatLaf) and is distributed in convenient packages: MSI for Windows, a bundled app for macOS, and AppImage for Linux. Thanks to jediterm, you get a pure‑Java terminal with local PTY and SSH sessions.

Will anyone replace their daily driver? I’m sticking with Warp, but having a portable Java terminal whose internals you can peek at is pretty cool - even if I’d still recommend checking out the original jediterm sources first.
And bonus points for Star Wars references - below is my collection that my lovely wife let me display center‑stage in our living room 😁.

PS: “Revenge of the Sith” is my favorite episode. I will happily argue that.

Neptune‑32
And while we’re on homemade projects, a terminal emulator is nothing - LPC4, author of Neptune‑32 built, in Java, their own 32‑bit CPU emulator with assembler and a custom instruction set 🥶.

The project has a small, self‑contained world: 32 general‑purpose registers, memory‑mapped I/O, stack/heap, ROM for syscalls, and simulated RAM/VRAM with a 128×128 RGBA framebuffer plus keyboard/console devices. The assembler supports labels, immediates, register addressing, and macros—with arithmetic, logic, jumps, syscalls, and shift instructions available. It’s a sandbox for running your own programs and experimenting with ISA design.
It’s a hands‑on playground for learning CPU architecture, assembly, and compilers—you can see how high‑level code translates to instructions and how stack, memory, and I/O work. It also gives a space to experiment with instruction design, syscalls, and schedulers without hardware costs and under full control (easy debugging, ISA tweaks).
Having written an NES emulator in Kotlin myself (I do things like that to fight previously mentioned existential crisis), I hugely respect such projects - I know the effort involved. BTW: There’s a fun Reddit thread accompanying it.
Slicer
Slicer by Matouš Kučera is a JVM bytecode decompiler and disassembler that runs… in the browser. The author notes it’s still WIP but already usable: it can decompile/disassemble classes, show control‑flow graphs for methods, visualize inheritance, inspect class file properties (versions, modifiers, supertypes, constant pool), and search constants or class members in a “workspace.” Everything runs locally - no files are sent to a server- because the decompiler/disassembler was ported to JavaScript via TeaVM.
The question “why not Swing/JavaFX/SWT?” is answered: TeaVM doesn’t support those UI toolkits, and if it did you’d just port existing tools, which “would be less creative” (showing that the spirit of experimentation in the community lives on).

Overall, Slicer is a neat example of how even seemingly closed‑off reverse‑engineering tools for the JVM can be brought into the browser.
hyperfiddle/electric
We started with Clojure, we end with Clojure.
Hyperfiddle/Electric is “full‑stack differential dataflow for UI” - a new web‑app programming model in Clojure/ClojureScript where you write frontend and backend in one expression. The Electric compiler automatically determines the network boundary from your code and splits the program into cooperating client‑ and server‑side parts. Reactivity is a language feature (reactive if/for/lambda), and functions remain “true” Lisp functions with recursion, closures, and macros.

Instead of request/response frameworks or ORMs wrestling with over/under‑fetching and “request waterfalls,” Electric builds a streaming DAG and resolves data flow at compile time. For developers, this means less glue code between layers (DTOs, HTTP clients, manual caching), fewer duplicated models and states on both sides, and a predictable reactive UI without juggling dozens of observable/async types. You simply compose your domain logic, and the tool “thinks for you” about network needs: it anticipates the other side’s requirements, limits redundant transfers, and eliminates request waterfalls - even across deep nesting, loops, or functional calls.
The Clojure community always delivers interesting ideas - still sad that Time‑Travel Debugging never caught on more widely.
