

JobRunr brings Carbon Aware Scheduling to JVM: Saving the planet one job at a time - JVM Weekly vol. 138
This time, we’re highlighting four important projects that have been released recently. Trust me, each of them have something section-worthy!


1. JobRunr v8 brings Carbon Aware Jobs

I have always liked the topic of sustainability — partly because it’s hard to find a better “business” reason to work on performance, and partly because it addresses the “challenges of our times,” where many standards are still emerging and the regulatory landscape is quite… nascent. And “nascent” is a very interesting place for an engineer. That’s why today we’ll start with JobRunr… and you’ll soon see how these issues connect.
But first, for those who don’t know the project: JobRunr is an open-source library that simplifies background job execution at scales from a single application to an entire cluster. Like Quartz Scheduler or Spring Batch (and in the .NET world – Hangfire), it lets you queue fire-and-forget, delayed, or recurring jobs using plain lambdas (the JDK 1.8 style), stores metadata in durable storage, and offers a lightweight dashboard for monitoring, retries, and scaling. Because of this, it often replaces cron scripts, Airflow, or custom batch jobs, while remaining a free, open solution suitable for production use (with the option to upgrade to a Pro version).
Last week, version v8.0 was released, which—besides the Carbon Aware Jobs that I have already partly spoiled and will explain shortly—introduces several long-awaited features: Kotlin Serialization support, a completely redesigned notification center in the dashboard, new autoscaling metrics for Kubernetes (with KEDA support), and a separate Multi-Cluster Dashboard allowing viewing multiple clusters from a single console. There are more changes (e.g., @AsyncJob, label cleanup, ending Redis/Elasticsearch support in OSS), but I think it’s time to move to the main course.
Because what makes me write about JobRunr here rather than in the usual Release Radar is the Carbon Aware Jobs feature. The idea is simple: instead of running a job at a fixed time, the engine takes into account CO₂ intensity forecasts of the power grid (starting with ENTSO-E for EU data centers) and shifts execution to consume the “cleanest” electricity possible. Thanks to this, generating invoices, training ML models, or updating CDN caches can “wait” an hour or two, reducing emissions without infrastructure changes and with minimal code effort.
From an API perspective, it’s trivial: just add a margin to your JobRunr cron definition, e.g., [PT1H/PT3H], or use helper methods like CarbonAware.dailyBetween(...). JobRunr then creates a “Pending” job with a green leaf icon that waits until the forecast indicates the optimal window; then it changes status to “Scheduled,” then “Enqueued,” and finally “Processing.” Developers can see in the dashboard why a specific time was chosen and which region’s data was used. In the future, there are plans to extend data sources to AWS, Azure, and GCP, allowing use beyond Europe.
Here is a short demo by Ronald Dehuysser, the project author:
Speaking of sustainability - although sustainability has somewhat disappeared from many agendas, JobRunr is not the only JVM ecosystem project addressing this problem.
For example, on GitHub you can find carbonintensityio/scheduler, which extends Spring Boot or Quarkus with a feature inspired by JobRunr, offering the @GreenScheduled annotation that dynamically shifts method execution into “green” windows based on public CO₂ emission forecast APIs (currently supporting only the Netherlands, with more regions coming). Green Software Foundation develops the Carbon Aware SDK with a ready Java client - a library that doesn’t schedule jobs per se but provides a unified interface for carbon intensity forecasts and metrics. It can be integrated into your own throttling algorithms, builds, or CI/CD pipelines; - UBS bank already used it to “cool down” a massive risk model.
And if your app runs in Kubernetes, you can add Microsoft’s Carbon Aware KEDA Operator, which, based on Carbon Aware SDK forecasts, raises or throttles maxReplicas for each ScaledObject, limiting scaling during emission peaks without code changes. As you see, the JVM ecosystem is gaining a whole palette of tools (and we haven’t even mentioned runtimes like ever-green (pun intended) GraalVM or Azul Platform Prime, which Anthony Layton recently covered in the context of Azul’s platform).
JobRunr fits into this broader context, which, while less media-hyped, remains an important engineering challenge. Smart energy use fits well as part of the solution.

2. By embracing the actor model, Akka lays foundation for Agentic Software for the enterprise

Now it’s time for the next project - Akka - a proven actor toolkit for the JVM that’s been around for fifteen years (I remember its launch, so every day I thank my lucky stars my back hasn’t given out yet). Akka’s actor model (“actor = state + message + supervision”) allows building reactive microservices and real-time systems with guaranteed high availability.
Fun fact/personal note - my master’s thesis was actually about reactive architectures, and I even managed to publish one conference paper on it on the way to a PhD that never happened.

Now the Akka team (formerly known as Lightbend; rebranded as Akka to emphasize their flagship platform’s importance) is proposing a new identity: a full-fledged agentic AI platform - an ecosystem of components for running and supervising networks of autonomous agents based on LLMs and external tools.
The metamorphosis plan consists of four tightly integrated modules: Akka Orchestration, Akka Agents, Akka Memory, and Akka Streaming. The set will enable creation, orchestration, and evaluation of agents that can react in real time, while promising all the operational features that have historically led many companies to use Akka. The release happened July 14, a public webinar happens on the 17th (today), although tons of info and demo examples are already available - so we can see Akka’s vision for its platform.
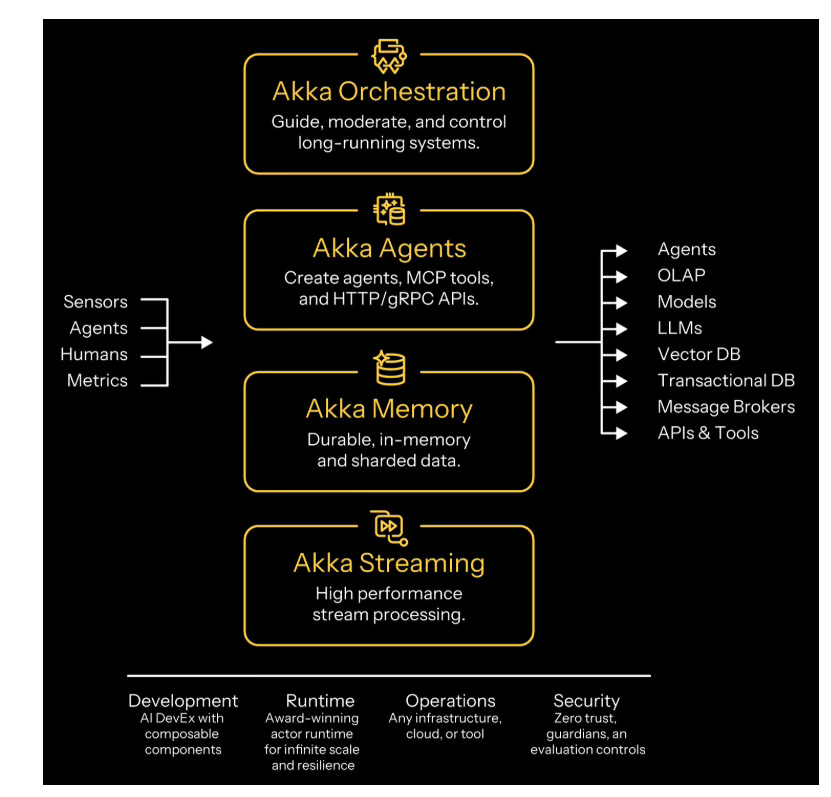
In practice, they will deliver an SDK with a declarative effects() API, where you define the prompt, model, MCP tools, but memory is implicit to everything you build. The Agent Testkit is for local and CI testing of multi-agent systems. Here you will find example of multi-agent application. Important disclaimer - for years Akka was (mostly) used by Scala developers, but since Akka 3.0 they focus solely on Java API, so if you are scared by Scala, not to worry.
The most interesting element from my perspective is the upcoming Evaluation Console for tracking costs, performance, and quality, providing evaluation into agentic workloads. The whole thing inherits Akka’s cluster properties - including memory replication of agents across regions and zero-downtime rollouts.
There are many agent architectures on the market, but I feel actors naturally fit this model. Crucially, an actor is also a long-lived process - persisting in memory, continuously handling interactions, and naturally maintaining context over time. This makes it particularly well-suited for modeling agents that require stateful, ongoing conversations and coordination. Stripping out all the magic, a single agent is roughly “a streaming LLM consumer”: it has its own state (memory), reacts to messages (prompts and tool callbacks), can delegate work to other actors/agents, and is supervised with restart and cluster sharding mechanisms.
Because of this, agent interactions map one-to-one onto asynchronous messages, and scaling agents becomes the same problem Akka has solved for years — just with a new, intelligent core, so they have some experience here.

Overall, you feel a strongly enterprise flavor in this rather “hacker-ish” solution world: control plane with multi-region failover, zero-trust mTLS, guardian agents for cost limits, rolling updates without downtime. It’s clear that Akka’s solution targets Enterprise very specifically.
And speaking of enterprise...
3. Modern, minimal, modular - Jakarta EE 11 redefines the platform baseline

Over the last five years, the enterprise Java landscape has changed beyond recognition: after the move from Oracle to the Eclipse Foundation and the memorable “namespace swap” from javax to jakarta (EE 9), subsequent releases have systematically pruned legacy APIs, focusing instead on lightness and cloud-nativeness. First, the Core Profile was introduced — just a handful (a small number in Jakarta EE terms) of specs needed to run a microservice on Functions-as-a-Service; then the new Web Profile appeared, with a slimmed-down MVC/REST stack; and finally, a two-year cadence of full releases and simplified Maven TCKs was established.
Against this background, Jakarta EE 11, officially released at the end of June, is the culmination of this “slimming down” operation. The platform now requires a minimum of JDK 17 (with LTS 21 supported), embraces Java Records and Pattern Matching into the standard, and at the same time removes the SecurityManager, prunes Managed Beans, and discards all optional, long-unmaintained specifications. We also get updated CDI 4.1 and consolidated Core/Web/Platform BOMs. The first certifications (GlassFish, Payara, OpenLiberty) appeared on launch day.
At the same time, version 11 debuts brand-new or reworked standards: Jakarta Data 1.0 and Jakarta Concurrency 3.1 (with Virtual Threads).
Jakarta Data 1.0 is a data processing standard directly inspired by the popular Repository pattern. Simply define an interface with methods like findByEmailAndStatus, annotate it with @Repository, and the runtime generates the full implementation—regardless of whether underneath is JPA, Mongo, or DynamoDB. It also offers built-in pagination (offset and cursor), a simple query DSL, and full CDI integration, so repositories can be injected like any other bean. In other words, it’s “Spring Data without Spring.”
The other star is Jakarta Concurrency 3.1, the first specification in the ecosystem to formally support Virtual Threads from JDK 21. You add virtual=true in @ManagedExecutorDefinition, and the app can natively handle parallel requests without juggling thread pools. The API also becomes more “CDI-centric”: you can inject executors or schedulers with qualifiers, schedule tasks with the @Schedule annotation, all while integrating with Flow/Reactive Streams and a new, much faster TCK. Together with Jakarta Data and the slimmed Core profile, this clearly points to a direction of shedding decade-old baggage.
Jakarta EE 12 is already looming on the horizon, with its plan voted on in May aiming for a full platform release between June and July 2026, after earlier Core (January 31) and Web Profile (March 31) milestones. Java 21 will be mandatory, but every implementation and TCK must also run on JDK 25, encouraging spec authors to use the latest language features without looking back. Tasks on the list include mandatory HTTP/3, further Virtual Threads enhancements (not only in Concurrency but also REST, WebSocket, Servlet), adding module-info.class in every artifact, and fully modularizing TCKs into spec-specific repos.
Functionally, we’ll see the debut of Jakarta Config (a fork of MicroProfile Config), Jakarta HTTP 1.0, and Jakarta Query 1.0, plus solid upgrades mainly focused on removing EJB: CDI 5, REST 5, Persistence 4, Security 5, Data 1.1, Servlet 6.2 — along with minor lifts in almost every package. Behind the scenes, the cleanup after SecurityManager continues and Application Client is deprecated (planned removal in EE 13), so future releases will be even lighter and more “cloud-native.”

PS: Recently, Payara held a virtual conference announcing the launch of Qube - a platform for automating Jakarta EE workloads on Kubernetes - and partnerships with Azul. You can watch the recordings here.
And now for a quick Kotlin ecosystem update - plus a small announcement

Regular JVM Weekly readers have probably already heard about Kotlin Notebook: the .ipynb environment built into IntelliJ IDEA that marries the best bits of Jupyter with the full power of an IDE. In a single view you get code, narrative, and live results, complete with autocompletion, refactoring tools, and direct access to every class in your project. That makes the notebook perfect for lightning‑fast experiments and for living, executable documentation (my personal favourite use‑case).
With IntelliJ IDEA 2025.1 the path from “idea” to “first cell” is even shorter. The first polish is visible from the get-go: you can spin up a notebook inside a project, as a scratch file, or straight from the Welcome screen. The toolbar gained one‑click buttons for restarting the kernel, running all cells, and force‑stopping runaway evaluations. Dependencies are just as easy: type %use ktor‑client, pull in the whole Ktor stack, and start making strongly‑typed HTTP calls or auto‑deserialising JSON - perfect for microservice testing and exploring without ever leaving the IDE.
If you like to poke at data (which, aspirationally at least, seems to be half of all developers these days) you’ll love the beefed‑up integration with Kotlin DataFrame and Kandy Charts. Tables now render as paginated, sortable views with drill‑down and CSV export, and one extra line (%use kandy) turns those tables into interactive plots you can copy to the clipboard or save as images.
Add the option to switch the notebook to any module’s classpath (❤️) and you get a nice lab for rapid prototyping and syntax‑checking any library that crosses your mind.
I recommend you to check How to Use Kotlin Notebooks for Productive Development by Ilya Muradyan and Teodor Irkhin (Product Manager for Kotlin), but they say a picture is worth a thousand words - so who knows how to price a video? Here’s a short clip that walks through everything new in Kotlin Notebook.
Never tried Kotlin Notebook? I’ve got a treat for you!
If you’re in Kraków Today (I know, pretty short notice, sorry 🥶) and speak Polish, drop by the Kraków Kotlin User Group meetup, co‑hosted by VirtusLab (my company ❤️) and JetBrains. Together with Jakub Chrzanowski, Lead Developer Advocate at JetBrains, we have two talks lined up: I’ll show how to write a NES emulator in pure Kotlin, with all the quirks (an expanded version of my KotlinConf talk), and Jakub - star of the evening - will give you a hands‑on tour of Kotlin Notebook: pulling data, visualising results, and running IntelliJ platform code right from a notebook, no plugin required. It’s shaping up to be a fantastic night, so come say hi!
Heads‑up 🇵🇱: the event will be entirely in Polish (sorry), but if you’re in town and understand “the language of Mickiewicz,” I’d love to high‑five you in person - I will be both speaker and a host 🙂
PS2: Organizational note: there will be no newsletter next week - I’m taking some well-deserved (I hope so at least) vacation 😄 - so the next edition will appear at the end of the month in the “July - Rest of the Story” …
…which (as usual after ANY break), will be a really long marathon… 🥶
PS3: From the collection “JVM Weekly in strange places”: the Walk of Fame in Cannes. Not on vacation - that’s next week - nor even at a conference.
Surprisingly, I’m at work 😅
