

Java 25 and GraalVM for JDK 25 Released - JVM Weekly vol. 145
Today is (or on Tuesday was) the day!


1. JDK 25 Released!
So, let's start with the announcement from the Oracle Technical Blog, and the Launch Stream with Java Developer Relation Team. If you want deep insight, that is your best source of information:
However, if you want to stay, like always, it is time to get through the full list!
Exegi Monumentum - New Stable APIs

JEP 506: Scoped Values
JEP 506 completes the series of preview versions starting with Java 20 and introduces Scoped Values as a stable feature of the platform. A Scoped Value is a container for an immutable value visible only within the dynamic scope of calls: a method establishes the binding, and the entire chain of its direct and indirect calls - including newly created child threads - can access that value. This mechanism is lighter than ThreadLocal, uses less memory (critical when dealing with millions of virtual threads), and eliminates side-effects related to forgotten cleanup.
Problem it solves: ThreadLocal is often overused to pass context across application layers. Its values are inherited by child threads, causing memory overhead, and lacking a clear “end of life” forces manual remove(), risking leaks. In the era of virtual threads, where each request can get its own lightweight thread, the cost of these copies becomes prohibitive. A way to pass immutable data with a clearly visible lifetime and safe inheritance by child threads was needed.
The solution: Scoped Values are typically declared as static final. The method ScopedValue.where(key, value).run(runnable) (or call) binds the value for the duration of the given block. Within this block, any call to key.get() returns the value, and once the block exits, the binding disappears, preventing leaks. Bindings are automatically inherited by threads created within the scope (e.g., via StructuredTaskScope), so child code sees the same context without memory copying.
import static java.lang.ScopedValue.where;
import java.lang.ScopedValue;
public class Example {
private static final ScopedValue<String> USER_ID = ScopedValue.newInstance();
public static void main(String[] args) {
where(USER_ID, "42").run(() -> { // establish binding
greet(); // within the scope
}); // USER_ID.get(); → IllegalStateException outside scope
}
private static void greet() {
System.out.println("Hello, user " + USER_ID.get());
}
}What changed since the fourth preview (JEP 487): The only functional change is the removal of support for null in ScopedValue.orElse; it now always requires a non-null fallback value. Other than that, the feature simply leaves preview status, completing its long refinement cycle and allowing both users and library authors to adopt it confidently.
JEP 511: Module Import Declarations
JEP 511 finalizes the import module declaration, which allows a single statement to import all packages exported by a given module and those of the modules it "reads." This simplifies the use of modular libraries in non-modular code and shortens .java files by eliminating long lists of imports.
Problem it solves: Since the module system was introduced, non-modular code had to rely on regular imports and possibly define a module to access full APIs. In practice, this led to duplicate import lists, discouraging use of modular libraries and thus hindering adoption. Wildcard package imports (import p.*;) didn’t help because a library might expose many packages from multiple dependent modules with non-obvious names.
The solution: The new syntax
import module M;acts like a wildcard import at the module level. After this declaration, the compiler sees all public classes from packages exported by module M, as well as those from modules required by M. The declaration works in both modular and non-modular source files and does not require module-info.java. It was previously tested under JEP 476 (JDK 23) and JEP 494 (JDK 24) and is now stabilized without changes.
Usage example
// Grants access to all exported classes from java.sql
import module java.sql;
public class Demo {
public static void main(String[] args) throws Exception {
var conn = java.sql.DriverManager.getConnection("jdbc:sqlite:test.db");
// ...
}
}After compilation, the code behaves as if it contained a regular import for every package exported by java.sql, without requiring the project to be modular.
JEP 512: Compact Source Files and Instance Main Methods
JEP 512 finalizes (after four preview versions) the "simplified path" for small programs. It enables compact source files without class declarations, with an instance main() method, and a new java.lang.IO class for basic input/output. The goal is to reduce boilerplate for beginners and small CLI tools, while maintaining compatibility with existing tools and a smooth upgrade path to production code.
Problem it solves: The traditional public static void main(String[] args) and mandatory class/package/import declarations introduce newcomers to complex concepts (access modifiers, static, arrays, System.out) before they can do anything useful. They also make writing quick scripts and CLI tools harder. Previous workarounds like single-file execution, still required full class syntax.
The solution: A "compact source file" may contain only fields and methods. The compiler generates an invisible, final class in the unnamed package and requires an executable main method.
main can be non-static and parameterless. If such a method exists, the launcher creates an instance via the default constructor and calls it. The java.lang.IO class (previously in java.io) offers five static print/println/readln methods, removing the need to know about System.out or BufferedReader. Packages from java.base are automatically imported, so List.of() and others are available without import.
// File: HelloWorld.jc (.java still works)
void main() {
IO.println("Hello, World!");
}You can run the program like any single-file Java source:
java HelloWorld.java
or compile and run it in the usual two-step flow.
What has changed since the preview version?: The name was changed from “simple source file” to “compact source file”, and static import of IO methods are no longer implicit to avoid "magic" behavior.
JEP 513: Flexible Constructor Bodies
JEP 513 allows constructors to contain regular statements before calling another constructor (super(…) or this(…)). These statements may not use the still-unfinished object (i.e., call methods on this) but can assign fields, validate arguments, calculate intermediate values, or log events.
This change closes a long-standing gap between the JVM - which has always allowed this, and the language, which required super(…) or this(…) to be the constructor’s first statement.
Problem it solves: Until now, you couldn’t even validate constructor parameters or initialize fields before calling another constructor. This was especially frustrating when migrating complex Java code to Kotlin, where Kotlin had its own semantics. It led to awkward code (duplicated validation, factories instead of constructors, static helper methods) and created artificial limitations not enforced by the JVM.
The solution: The language spec is relaxed: constructor bodies may contain any statements before an explicit super(…)/this(…) call, as long as:
Every execution path contains exactly one such call (to avoid race conditions),
code before the call does not access the incomplete instance except by assigning its fields,
The call is not inside a try block.
The JVM’s rules on safe object initialization (e.g., superclass constructor is called once) remain unchanged - no VM changes are needed.
class Point {
private final int x, y;
Point(int x, int y) {
if (x < 0 || y < 0) // validation before super()
throw new IllegalArgumentException();
this.x = x; // allowed field assignment
this.y = y;
// super() is implicitly called
}
}
class ColoredPoint extends Point {
private final Color color;
ColoredPoint(int x, int y, Color c) {
Objects.requireNonNull(c); // validate and assign
this.color = c;
super(x, y); // explicit call after prior statements
}
}
With flexible constructors, code becomes more natural: validation and initialization logically precede base constructor calls, and developers don’t need workarounds or code duplication.
JEP 510: Key Derivation Function API
JEP 510 stabilizes - without further changes - the interface introduced in JDK 24 as a preview: a small but critical component of the cryptography library that allows implementation-agnostic use of KDFs (Key Derivation Functions), such as HKDF or Argon2. These functions derive new keys from a base secret key, salt, and context data.
Problem it solves: Java had a rich set of cryptographic primitives but lacked a unified API for key derivation functions (KDFs). Each project implemented HKDF or Argon2 differently, with inconsistent conventions and no standard integration with Security Providers. This hindered the use of post-quantum schemes like Hybrid Public Key Encryption, which rely on KDFs in their key establishment.
The solution: A new factory class KDF.getInstance("HKDF-SHA256") provides a ready-made HKDF implementation. Future algorithms (e.g., Argon2) can be added by external providers, written in Java or native code. Parameters are passed via specialized classes like HKDFParameterSpec, and the result is returned as a SecretKey or byte array. This lets TLS libraries, KEM modules (JEP 452), and PKCS#11 drivers rely on a shared API rather than duplicating code.
// Create an HKDF object and derive an AES-256 key
KDF kdf = KDF.getInstance("HKDF-SHA256");
AlgorithmParameterSpec params =
HKDFParameterSpec.ofExtract()
.addIKM(initialKeyMaterial)
.addSalt(salt)
.thenExpand(info, 32);
SecretKey aesKey = kdf.deriveKey("AES", params);Changes since preview (JEP 478): The only change is the removal of the "preview" status - the API signature, KDF/KDFSpi classes, and parameter objects remain the same.
Performance - VM Internals

JEP 519: Compact Object Header
JEP 519 promotes compact object headers (introduced in JDK 24 as an experimental feature) to a fully supported production option in JDK 25. When the flag -XX:+UseCompactObjectHeaders is enabled, each object in HotSpot uses only one machine word for its header instead of two, reducing memory requirements and improving data locality. Compressed headers remain disabled by default, but no longer require -XX:+UnlockExperimentalVMOptions.
Problem it solves: The standard 64-bit HotSpot object header consists of two words: a mark word and a class pointer. With millions of objects, this results in tens of megabytes of pure overhead. The previous -XX:+UseCompressedClassPointers option only partially reduced that cost; full 64-bit headers still doubled GC traffic and hurt CPU cache efficiency.
The solution: The compact format combines the mark word, a compressed class pointer, and a few bits of meta-information into a single 64-bit value. The JVM retains full header functionality (e.g., hashCode, synchronization, biased locking) while freeing up the second word for application data. The option has undergone large-scale production testing (e.g., at Amazon across hundreds of services) and is ready for widespread use. Users enable it with a single flag:
java -XX:+UseCompactObjectHeaders -jar app.jarFour extra bits are reserved for future projects (like Valhalla), allowing the format to evolve without resizing the header again.
JEP 521: Generational Shenandoah
JEP 521 promotes the generational mode of the Shenandoah GC from experimental (introduced in JEP 404 in JDK 24) to a fully supported production option. You can now run the generational GC with just -XX:+UseShenandoahGC -XX:ShenandoahGCMode=generational, without unlocking experimental flags.
Problem it solves: Shenandoah's single-generation mode eliminates long stop-the-world pauses but loses the benefits of generational heap design: most objects die young, so it's cheaper to reclaim them in a young generation and avoid frequent scans of long-lived data. ZGC already has a generational mode in production (JEP 439), leaving Shenandoah users to choose between low latency and efficient young object collection.
The solution: After a year of stabilization and testing, the generational mode reached production quality: all bugs were resolved, and memory/CPU usage now matches or outperforms the single-generation version. In JDK 25, the -XX:+UnlockExperimentalVMOptions requirement is removed, and all other Shenandoah options remain unchanged, making migration as simple as flipping a flag. The default mode is still single-generation, but JDKs can now safely enable the generational variant in production environments.
You can learn more in New in Java25: Generational Shenandoah GC is no longer experimental by the The Perf Parlor.
JEP 503: Remove the 32-bit x86 Port
JEP 503 removes all source code and build support for the 32-bit x86 architecture from the JDK mainline. The port was already marked for removal in JDK 24 (JEP 501), and now, in JDK 25, its elimination simplifies building, testing, and future development by removing the need to maintain 32-bit-specific code paths.
Problem it solves: Maintaining the 32-bit x86 code required additional testing, CI setup, and separate branches in HotSpot, slowing down development and increasing regression risk. The server market switched to 64-bit over a decade ago, and even the last major 32-bit client system - Windows 10 32-bit - loses support in October 2025. New features (e.g., advanced virtual thread scheduling) had to either ignore 32-bit or implement costly workarounds, offering no real value to users.
The solution: All code, build scripts, and tests dependent on x86_32 were removed. The build system (make/Gradle) no longer generates 32-bit artifacts. Documentation and supported platform lists were updated to clearly state the minimum hardware requirements: Intel/AMD x86-64 or other supported 64-bit architectures.
Users still wishing to run the JDK on 32-bit x86 systems can do so using the so-called Zero JDK.
JEP 514: Ahead-of-Time Command-Line Ergonomics
JEP 514 simplifies use of Ahead-of-Time (AOT) class caches by adding a single flag that combines training the application and generating the cache in one java invocation.
Problem: AOT caches (introduced in JEP 483) speed up application startup by using pre-loaded and pre-linked classes stored in .aot files. Until now, using them required two separate steps: first recording workload behavior with -XX:AOTMode=record, then building the cache with -XX:AOTMode=create. This discouraged regular use and left behind intermediate config files.
The solution: The new option -XX:AOTCacheOutput=<file> instructs the java launcher to handle both steps internally: it runs the app in training mode, then automatically builds the cache. The temporary configuration file is created and deleted behind the scenes, so users only see a single artifact: the .aot file. A new environment variable JDK_AOT_VM_OPTIONS allows specifying options solely for the cache creation phase (e.g., memory limits) without affecting the training run.
The old two-step flags remain supported for advanced use cases.
# One-step cache creation
java -XX:AOTCacheOutput=app.aot -cp app.jar com.example.App
# Run with an existing cache (as before)
java -XX:AOTCache=app.aot -cp app.jar com.example.AppThis makes daily AOT cache generation as easy as adding a flag - likely boosting adoption and laying the groundwork for future optimizations under Project Leyden.
JEP 515: Ahead-of-Time Method Profiling
JEP 515 extends AOT caches by allowing method execution profiles to be saved during the application’s “training” run. On subsequent (production) runs, HotSpot can load these profiles immediately, allowing the JIT compiler to generate highly optimized native code from the very first second. This helps the application reach peak performance much faster.
Problem it solves: Currently, the JVM spends the first few seconds (or minutes) collecting stats to identify “hot” methods. This warm-up period delays peak performance and, in serverless or short-lived jobs (e.g., cronjobs), may account for most of the process’s lifetime. The AOT cache from JEP 483 eliminates class loading and linking delays, but doesn’t help the JIT, which still waits for profile data.
The solution: During the training run, the JVM saves not just class data to the AOT cache but also complete method execution profiles. This same .aot file can then be reused in production, where profiles are available immediately - allowing the JIT to compile hot methods right away without guessing. This shorter warm-up translates to reduced CPU spikes and better response times.
The workflow and flags remain identical to those introduced in JEP 514.
Observability

JEP 509: JFR CPU-Time Profiling (Experimental)
JEP 509 extends JDK Flight Recorder with support for sampling CPU time per thread on Linux. Unlike traditional "execution-time" profiling, the new jdk.CPUTimeSample event precisely shows how many CPU time individual methods consume, making it easier to identify true throughput bottlenecks.
Problem it solves: Existing "execution-time" profiling mixes actual computation with idle time (e.g., blocking I/O). As a result, a method that spends 90% of its time waiting may look just as “hot” as a compute-heavy method, even though it barely uses the CPU. Without CPU-time metrics, it’s hard to determine what’s really taxing the processor, especially in I/O-heavy applications.
The solution: JFR will use Linux's CPU-timer mechanism to sample the stack of every thread running Java code at fixed intervals of CPU time. Each signal triggers a jdk.CPUTimeSample event with a stack trace, which is recorded alongside the existing jdk.ExecutionSample events in the JFR file. Sampling frequency is configurable (e.g., throttle=10ms or 500/s), and any lost samples are reported via a new event jdk.CPUTimeSamplesLost.
This feature is marked as @Experimental, but doesn’t require any special JVM flags - just enable the event.
# Start recording with CPU-time sampling (500 samples/sec) and save to file
java -XX:StartFlightRecording=jdk.CPUTimeSample#enabled=true,\
jdk.CPUTimeSample#throttle=500/s,filename=cpu.jfr MyApp
You can then use jfr view cpu-time-hot-methods cpu.jfr or generate flame graphs in JDK Mission Control to instantly see which methods burn the most CPU time.
You can learn more details in Java 25’s new CPU-Time Profiler by JEPs author, Johannes Bechberger. Thanks for the correction to this part Johannes, much appreciated
JEP 520: JFR Method Timing & Tracing
JEP 520 enhances JDK Flight Recorder in JDK 25 with two new events for each method call: jdk.MethodTrace (who calls whom) and jdk.MethodTiming (precise duration), implemented using lightweight bytecode instrumentation at runtime. This enables full method-level tracing without custom logging or the sampling inaccuracy common to traditional profilers.
Problem it solves: Until now, full “call tracing” required manually adding logs or using Java Agents, which could be cumbersome. JFR only offered stack sampling, which didn’t provide method durations or call counts - making it hard to pinpoint small but frequently invoked hot spots.
The solution: HotSpot introduces an optional instrumentation pass: when the new events are enabled, it inserts lightweight timing and method ID recording into the prologue and epilogue of methods.
Each method call produces a pair of events: MethodTrace → MethodTiming. JFR aggregates them into comprehensive reports showing number of calls, total time, and mean time per call. The filter=package|class|method option can be used to narrow the scope to selected packages, minimizing overhead.
# Run the app and trace methods from the com.example.service package
java -XX:StartFlightRecording=method-trace,settings=default,\
jdk.MethodTrace#filter=com/example/service/**,filename=trace.jfr -jar app.jarIn JDK Mission Control, you get a table of methods with columns like "Calls", "Total ns", and "Mean ns", plus a call tree, allowing you to quickly identify the most expensive hot paths in just one short recording session.
New Frontier - New APIs

JEP 502: Stable Values (Preview)
JEP 502 introduces the StableValue<T> class, enabling deferred immutability. A StableValue starts out “empty,” but can be initialized exactly once on first access. After being set, the JVM treats it as a constant - offering the same optimizations as a final field -without requiring eager initialization. This allows large applications to start faster by deferring the creation of expensive objects until they’re truly needed.
Problem it solves: Final fields guarantee immutability and enable optimizations like constant folding, but must be initialized immediately - in a constructor or static initializer. For heavyweight components (loggers, network connections, repositories), this slows down startup and often initializes resources that may never be used. Alternatives (lazy holders, double-checked locking, concurrent maps) either give up on optimizations or require complex, error-prone synchronization code.
The solution: StableValue offers the best of both worlds: thread-safe, one-time initialization and deferred evaluation. Methods like orElseSet(…), supplier(…), and list(…) support common usage patterns - from single values to lazy suppliers and on-demand lists. If the StableValue field is itself final, the JVM can optimize access as if the field were always constant, with no need to check for null or synchronize.
// Example: lazy, thread-safe logger initialization
import java.util.logging.Logger;
import java.lang.StableValue;
class OrderController {
private final StableValue<Logger> logger = StableValue.of();
private Logger getLogger() {
return logger.orElseSet(() -> Logger.getLogger(OrderController.class.getName()));
}
void submitOrder() {
getLogger().info("order started");
// …
getLogger().info("order submitted");
}
}
After the first call to getLogger(), the Logger is created and stored; later calls reuse the same instance. The JVM can optimize access just like with a final field, with no null checks or synchronization overhead.
JEP 470: PEM Encodings of Cryptographic Objects (Preview)
JEP 470 adds small, immutable classes PEMEncoder and PEMDecoder for converting X.509 keys, certificates, or CRLs between binary DER format and text-based PEM, simplifying cryptographic workflows in Java.
Problem it solves DER (Distinguished Encoding Rules) is a binary format for ASN.1 structures - great for machines but unreadable and hard to transmit. PEM (Privacy-Enhanced Mail) wraps DER in Base64 and adds
-----BEGIN …-----
headers, making it easier to email, store in Git, or include in server configs.
Until now, Java lacked an official API for DER ↔ PEM conversion. Developers had to write custom parsers or rely on third-party libraries, increasing the risk of bugs and complicating security-related code.
The solution: JEP 470 introduces two static entry points (PEMEncoder.of() and PEMDecoder.of()) with an API style similar to Base64. The method encodeToString(obj) produces PEM-formatted output, optionally encrypting private keys with a password. The method decode(text, type) reconstructs the object and validates headers.
For rare object types, there's a generic PEMRecord class, and extensibility is ensured via the marker interface DEREncodable.
// Minimal example - converting a private key to PEM and back
String pem = PEMEncoder.of().encodeToString(privateKey); // DER → PEM
PrivateKey key = PEMDecoder.of().decode(pem, PrivateKey.class); // PEM → DERJEP 505: Structured Concurrency (Fifth Preview)
JEP 505 significantly revamps the Structured Concurrency API, now in its fifth preview. The API treats groups of concurrent tasks as a single "family unit" of work, enabling unified cancellation, exception propagation, and observability. This makes concurrent code more readable and helps prevent thread leaks.
The problem it solves: Traditional concurrency using ExecutorService and Future allows launching threads anywhere, but does not enforce parent-child relationships. If one task fails, others may keep running, leading to resource leaks, slow cancellation, and confusing thread dumps. In servers using lightweight virtual threads, this is especially problematic due to the high concurrency.
The solution: The StructuredTaskScope class creates a scope (now initialized via the static method open()) in which you fork subtasks and wait for their completion or failure. The default policy is “all succeed or first failure,” but you can customize this by passing a Joiner strategy. The code clearly models parent-child task relationships: if one task throws, others are canceled, and the scope ends with an exception - no leaks.
What changed in the 5th preview?
New way to create scopes: Instead of using constructors like new StructuredTaskScope.ShutdownOnFailure(), you now use the static factory StructuredTaskScope.open(...). The default version waits for all subtasks to succeed or stops on the first failure.
Joiner instead of subclasses: The logic for deciding when the scope is "done" has been moved into the Joiner interface. Built-in factories include anySuccessfulResultOrThrow() (first success wins) and allSuccessfulOrThrow() (all must succeed). You can also write your own strategies without subclassing.
join() returns results directly: join() now returns a result based on the Joiner (e.g., Stream<Subtask<?>> or a single result) or throws FailedException. The old two-step join().throwIfFailed() is gone.
Builder-style configuration: The open() method accepts a lambda configurator to set the scope name, timeouts (withTimeout(Duration)), or custom thread factories - making it easy to assign readable thread names or deadlines.
New exceptions and stricter rules: Invalid usage (e.g., calling fork() outside the owning thread) throws StructureViolationException, and timeouts throw TimeoutException. The scope enforces correct usage via try-with-resources.
Improved observability: The thread dump’s JSON format now includes StructuredTaskScope hierarchy, so tools can visualize the full task tree in one place.
Quick example with the new API
Response handle() throws InterruptedException {
try (var scope = StructuredTaskScope.open()) { // default policy
var user = scope.fork(() -> findUser()); // subtask 1
var order = scope.fork(() -> fetchOrder()); // subtask 2
scope.join(); // waits & propagates
return new Response(user.get(), order.get()); // combine if successful
} // auto-cancel on failure
}The code clearly defines thread lifetime boundaries: everything happens inside a try block; if one subtask fails, the other is canceled automatically, and the exception propagates to the parent thread.
Nihil Novi Sub Sole - (Forever) Preview Features

JEP 507: Primitive Types in Patterns, instanceof and switch (Third Preview)
JEP 507 brings back, for the third time, the preview feature that extends pattern matching to primitive types (int, long, double, etc.) across all pattern contexts. This means that both instanceof and switch can now match and safely cast primitive values without boxing, unifying data handling in Java.
Problem it solves: Previous versions of pattern matching only supported reference types. Differentiating between int, double, or boolean required verbose if statements or traditional switch cases, followed by manual casting. This led to repetitive, noisy code and often triggered autoboxing when working with collections or streams. The lack of a unified syntax made it harder to write generic tools that operate on both primitive and object types.
The solution: JEP 507 extends compiler rules so that primitive types can be used anywhere a class type pattern was previously allowed:
instanceof now supports patterns like obj instanceof int i, which automatically casts and binds to i.
switch expressions and statements accept primitive patterns in all branches, allowing elegant dispatch for both reference and primitive values.
Patterns can be nested (e.g., inside records or arrays), enabling a consistent model for data deconstruction.
// instanceof with a primitive pattern
Object o = 42;
if (o instanceof int n) {
System.out.println("Double the value: " + (n * 2));
}
// switch using both primitive and reference patterns
static String describe(Number num) {
return switch (num) {
case int i -> "int %d".formatted(i);
case long l -> "long %d".formatted(l);
case double d -> "double %.2f".formatted(d);
case Float f -> "Float %.2f".formatted(f);
default -> "other number";
};
}The third preview introduces no semantic changes compared to the second (JEP 488). The authors simply seek more feedback from real-world projects before finalizing the feature.
JEP 508: Vector API (Tenth Incubation)
JDK 25 delivers the tenth incubation release of the Vector API, found in the jdk.incubator.vector module. This API lets developers write explicit vectorized algorithms in plain Java. The JIT compiler (C2) maps the code at runtime to SIMD instructions (e.g., AVX, SSE, NEON, SVE), allowing applications to achieve performance far beyond traditional scalar loops.
Problem it solves: HotSpot's automatic vectorization is fragile: it supports a limited set of operations, depends heavily on loop shapes, and can break with minor code changes. Developers who rely on SIMD power (for ML, signal processing, cryptography) often resort to JNI or specialized C/C++ libraries. The Vector API removes this barrier-offering a high-level abstraction that guarantees Java expressions will be translated into vector instructions without writing native code and while retaining portability.
The solution: Vector API centers around three key classes: VectorSpecies<E> describes the shape (e.g., 256 bits as 8 ints), the abstract Vector<E> represents the data, and operations are selected from VectorOperators.
The tenth incubation brings one API change and two notable implementation improvements:
VectorShuffle + MemorySegment - Shuffle tables can now directly read/write off-heap data using the Foreign Memory API.
FFM-based linkage – instead of HotSpot-specific stubs, the API now calls SVML/SLEEF native math functions via the Foreign Function & Memory API, reducing C++ complexity and improving maintainability.
Auto-vectorization for Float16 – basic operations (add, mul, div, sqrt, fma) on half-precision floats are now automatically mapped to SIMD instructions on supported x86-64 processors.
The API remains in incubator status: to compile, you must include the module (--add-modules jdk.incubator.vector) and enable preview features (--enable-preview). It’s expected to move to preview only once Project Valhalla delivers value classes.
// Simple SIMD loop: c[i] = -(a[i]^2 + b[i]^2)
static final VectorSpecies<Float> S = FloatVector.SPECIES_PREFERRED;
void vec(float[] a, float[] b, float[] c) {
for (int i = 0; i < S.loopBound(a.length); i += S.length()) {
var va = FloatVector.fromArray(S, a, i);
var vb = FloatVector.fromArray(S, b, i);
va.mul(va).add(vb.mul(vb)).neg().intoArray(c, i);
}
// scalar fallback for array tail
}This example is directly translated by HotSpot into AVX/NEON instructions, delivering throughput far exceeding that of an equivalent scalar loop.
2. The Dark Matter of JDK 25 - improvements the JEPs don’t mention

One does not live by JEPs alone, so this time I decided to look at what’s really happening under the hood and which smaller-scale improvements have landed. A few of them seem quite practical—or just plain interesting.
API improvements
One of the most noticeable trends is the steady smoothing of rough edges in the core libraries and the removal of boilerplate. Java developers have spent years writing the same loops for reading files and finally blocks for closing resources. JDK 25 says “enough!”, introducing several small but very satisfying changes.
Path path = Path.of("config.properties");
BufferedReader br = Files.newBufferedReader(path, StandardCharsets.UTF_8);
List<String> lines = new ArrayList<>();
try {
String line;
while ((line = br.readLine()) != null) {
lines.add(line);
}
} finally {
try { br.close(); } catch (IOException ignore) {}
}The java.io.Reader class gained readAllAsString() and readAllLines(), modeled after the well-known methods in java.nio.file.Files. It’s a simple answer to the common need to read an entire stream, eliminating error-prone buffered loops.
And yes, I know this has existed in various utility libraries, and most people have moved to java.nio anyway - but still worth sharing.
Similarly, the compression classes Inflater and Deflater, which manage native resources, finally implement AutoCloseable. Previously you had to remember to call end(), a frequent source of memory leaks. Now you can use them safely in a try-with-resources block, which guarantees automatic resource cleanup and makes your code much more reliable. These are pure ergonomics - less code to write and fewer places to make mistakes.
The new HTTP client has gained the ability to set the maximum size of the response body it will accept. This is a key defensive mechanism that protects your application from DoS attacks or server bugs that could otherwise lead to an OutOfMemoryError.
try {
HttpResponse<Path> res = client.send(req,
HttpResponse.BodyHandlers.limiting(
HttpResponse.BodyHandlers.ofFile(out), MAX_BYTES)
);
} catch (IOException e) {
System.err.println("Transmission aborted (> " + MAX_BYTES + " B): " + e.getMessage());
try { Files.deleteIfExists(out); } catch (IOException ignore) {}
}
Under-the-hood optimizations
There’s magic happening under the JVM’s hood as well, and changes in the garbage collectors show a clear trend: Java is becoming a better citizen in cloud and containerized environments. G1 GC has gained an experimental feature that lets it automatically return unused heap memory to the operating system during periods of low application activity. Previously, if an app had a temporary spike in memory needs, it could hang on to that memory “just in case” for a long time.
ZGC, on the other hand, has learned not to try deduplicating String objects that are “young” and likely to die soon. This prevents short-lived objects from being kept alive unnecessarily, which used to create extra work for the GC. Although these changes are transparent, their effect is tangible. Temporarily releasing memory via G1 can directly translate into lower cloud bills, and a smarter ZGC means better performance for text-heavy applications—all without changing a single line of code.
A few other changes, while small, are quite interesting. The specifications of StringBuilder/StringBuffer for toString(), substring(), and subSequence() in JDK 25 have been relaxed (JDK-8138614): there is no longer a requirement that a “new” String object must be created every time. The implementation may return an already existing String (OpenJDK explicitly gives the example of returning the canonical empty string "" instead of creating a new object), as long as the value matches. This opens the door to small allocation optimizations. Still, don’t compare strings with == - even if it happens to work, there are no guarantees.
New uses of ForkJoinPool
As a reminder: ForkJoinPool is a specialized thread pool for “divide and conquer” tasks. It uses a work-stealing model: each worker has its own task deque, and when it runs out of work, it “steals” tasks from the tail of other workers’ deques, keeping CPUs busy without excessive synchronization. In practice, ForkJoinPool powers parallel streams, the default execution of many CompletableFuture.*Async operations (when you don’t provide an executor), and components based on Flow/SubmissionPublisher. In the world of virtual threads, the default scheduler is also built on ForkJoinPool mechanisms, which makes it efficient to interleave very many lightweight tasks.
We’ve now gotten another significant ForkJoinPool update (JDK-8319447): it now implements ScheduledExecutorService. Under the hood, a lightweight “DelayScheduler” is started lazily on the first call to a schedule* method, making delayed and periodic tasks (e.g., timeouts) scale better and cheaper - especially in networked applications where most timeouts end up being cancelled anyway.
In addition, the ForkJoinPool API now includes methods like schedule(...), scheduleAtFixedRate(...), scheduleWithFixedDelay(...), plus helpers such as getDelayedTaskCount() and cancelDelayedTasksOnShutdown(). Also, all asynchronous methods in CompletableFuture without an explicitly provided executor will now use the common ForkJoinPool, which unifies behavior and avoids spinning up a new thread per task in certain scenarios.
New Capabilities in Tools and JFR
Apart of things from the JEPs, JDK Flight Recorder has gained a powerful new annotation, @Contextual (JDK-8356698). It allows fields in custom JFR events to be marked so they can be linked with other events occurring in the same thread. In practice, this means that analytical tools can now easily correlate high-level information (e.g., a transaction ID from an HTTP request) with low-level JVM events (e.g., lock contention or an I/O operation) that happened during the processing of that request. This is a fundamental shift for system observability.
It’s also worth noting a change in the jpackage tool (JDK-8345185), which will no longer include service bindings by default when creating an executable image. As a result, generated applications may be smaller, but they might also miss some necessary modules if they relied on that mechanism. Developers who need the previous behavior must now explicitly add the --bind-services option to their configuration.
This is just the tip of the iceberg. Each JDK release brings hundreds of such improvements - you can find the list here.
3. GraalVM for JDK 25 is here

As usual, a new GraalVM release landed alongside the JDK. GraalVM for JDK 25 fully supports JDK 25, including all new language features, updated APIs, the standard class libraries, and baseline VM improvements. Front and center is preliminary optimization for the Java Vector API, which translates high-level vector operations into ultra-fast, native CPU SIMD instructions, as well as improved support for the Foreign Function & Memory (FFM, “Panama”) API, with AArch64 support on macOS and Linux. At the same time, beyond JVM compatibility, the project itself brings quite a bit that’s new.
Improvements in the Graal Compiler and Native Image
Let’s start with the heavy engineering, because - as usual with GraalVM - there’s interesting stuff under the hood. Whole-Program Sparse Conditional Constant Propagation (and now that you’ve read it, try saying that out loud—I dare you 😁) is going stable. It is an advanced static analysis that runs during native-image build (AOT). The WP-SCCP algorithm analyzes the application’s entire call graph, starting from known constants (e.g., literals, final static values) and propagating them through all feasible execution paths. If, for example, a method is always invoked with a constant argument (say, true), the compiler can “paste” that value in and simplify the code. More importantly, if an if condition always evaluates to false based on this analysis, that whole branch is marked as dead code and removed entirely from the final binary. “Sparse” means the algorithm only touches the parts needed for propagation, so it’s fast; “Whole-Program” means it sees the entire application at once, letting it aggressively prune unused dependencies and constructs that a method-at-a-time JIT typically can’t eliminate as boldly. Pure witchcraft.

Another addition is a static profiler based on XGBoost (eXtreme Gradient Boosting—an open-source ML library) and a trained machine-learning model (GraalNN). Traditional profile-guided optimization (PGO) requires running the application to gather data on which code paths are “hot.” How does the new mechanism work? Instead of executing the code, GraalVM uses XGBoost to predict which methods will be invoked most often. The model was trained on a large corpus of open-source software and “learned” code patterns that correlate with high call frequency (e.g., methods inside nested loops, utility methods, etc.). Based on these predictions, the compiler can optimize the anticipated hot paths more aggressively - for example, by inlining more aggressively - even without prior program runs.
On the front of performance, the GraalVM 25 brings the new -H:Preserve option, which is an experimental flag in native-image that fundamentally changes the migration story for complex applications. Previously, a major hurdle in adopting Native Image was its strict closed-world assumption. The build process's static analysis can't predict dynamic behavior like reflection, JNI, or serialization. This forced developers to manually create detailed JSON files listing every single class, method, and field that might be accessed dynamically - a tedious and error-prone task, especially with large frameworks like Spring or Hibernate which rely heavily on such "magic.".
The -H:Preserve flag offers a solution to this problem. Instead of requiring surgical precision, it allows developers to adopt a "just in case" strategy. For example, -H:Preserve=package=com.example.mypackage instructs native-image to keep all classes within that package, regardless of whether static analysis finds a path to them. This eliminates the need for most manual configuration for reflection and other dynamic features. The trade-off is a potentially larger binary, but the benefit is a drastically simplified and faster migration path for legacy enterprise applications, lowering the barrier to entry for GraalVM adoption.

In parallel, the new experimental Tracing Agent addresses the challenge of generating accurate configuration from a different angle. The original agent ran on a standard JVM to observe an application's behavior and generate the necessary metadata. However, an application's runtime behavior on the HotSpot JVM can have subtle differences compared to its behavior as a compiled native executable running on the SubstrateVM.
The new agent solves this by running directly in native mode. It traces the application's execution within the actual native environment, providing a much more precise picture of which types are loaded and which resources are accessed at runtime. This results in higher-fidelity metadata that perfectly matches the application's true needs. This improved accuracy not only prevents runtime errors like ClassNotFoundException caused by incomplete configuration but also allows the compiler to be more confident in its optimizations. With more accurate data, the compiler can more effectively perform dead-code elimination, helping to build even smaller and more optimized applications.
The next aspect is advanced obfuscation. Native Image already adds several layers of protection: it removes dead code, restricts unauthorized reflection and deserialization, performs aggressive optimizations, and compiles your bytecode to machine code. In this release, the GraalVM team added advanced obfuscation (experimental feature), making native images even harder to reverse-engineer to help protect your intellectual property. It obfuscates the names of modules, packages, classes, methods, fields, and source files in both user code and dependencies.

Finally, the introduction of the new Dynamic Access Report tool is a direct response to one of the biggest challenges of working with Native Image: diagnosing problems that stem from the dynamic nature of Java. The native-image compiler relies on the closed-world assumption, where the entire application must be fully analyzed at build time. However, static analysis cannot detect calls based on reflection, dynamic proxies, or resource loading that depend on data only available at runtime. This led to a frustrating workflow: a developer would compile the application, run it, and then encounter runtime errors (like ClassNotFoundException), forcing them to 'guess' what configuration was missing.
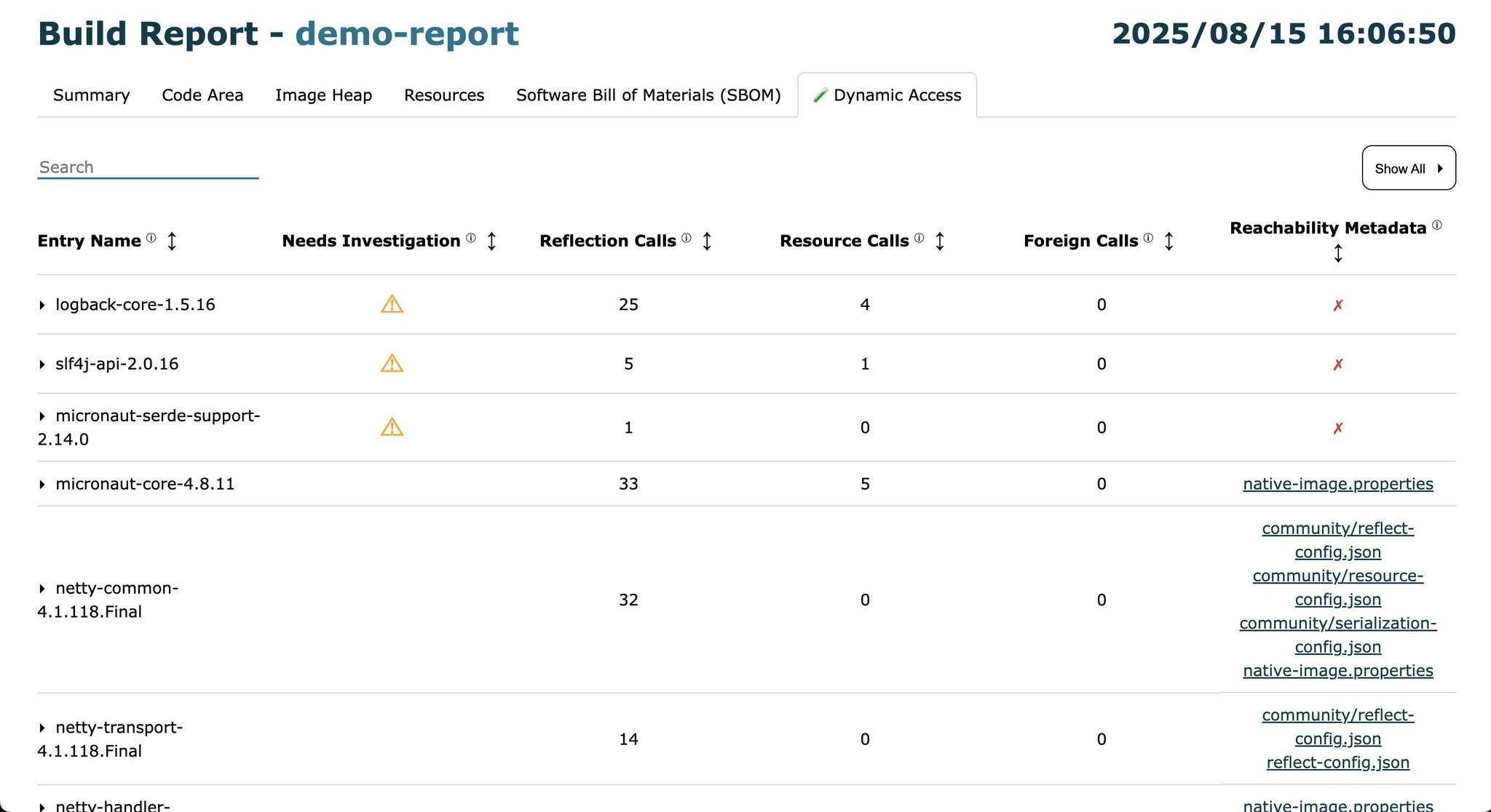
The Dynamic Access Report changes this process, transforming it from reactive to proactive. The tool acts like a specialized 'doctor' for the application, generating a detailed report that pinpoints the exact locations in the source code where dynamic features requiring special configuration are used. Instead of waiting for a runtime error, the developer gets a list of specific points to address, such as: "the process() method in the DataHandler class uses Class.forName(), which requires registration in a configuration file." As a result, the tool not only speeds up the process of locating the source of a problem but also serves an educational role by helping developers understand how their application interacts with the dynamic elements of the JVM. This makes the build process more transparent, predictable, and significantly less error-prone.
Advances in the JS, Python, and WebAssembly runtimes
Language implementations were updated as well. GraalJS now enables ECMAScript 2025 mode by default, giving developers immediate access to the latest JavaScript features with zero extra configuration. The move to Node.js 22.17.1 ensures compatibility with the current Node ecosystem and brings important security and performance fixes. On the Python side, GraalPy makes a major quality-of-life improvement for Windows users by providing a fully functional REPL, enabling convenient interactive development and testing on that platform.
The most impressive change, however, is in GraalWasm. We already mentioned the Vector API, and there’s one concrete use worth calling out—its integration with WebAssembly SIMD. When the GraalWasm engine encounters SIMD instructions in Wasm code, it doesn’t emulate them in software. Instead, GraalWasm’s translator maps those low-level operations to high-level Java Vector API types and methods. The Graal compiler (JIT or AOT) then takes those and, as described above, compiles them into optimal, native SIMD instructions for the host. This creates a highly efficient pipeline: Wasm SIMD → Java Vector API → Native CPU SIMD, eliminating emulation overhead and approaching near-native performance.
An intrinsic (compiler intrinsic) is a special function the compiler “understands” at a fundamental level. Instead of emitting standard call/return sequences (pushing arguments, jumping to a function address, returning), the compiler replaces the call directly with one or more specific, highly optimized machine instructions. The same mechanism applies to ARM instructions.
And ARM is my little hobbyhorse - on Saturday I’ll be speaking about it at the Confitura Conference conference in Warsaw this week, with plenty on similar mechanisms 😉

Polyglot Runtime and Truffle Framework updates
Release 25 brings foundational improvements to the very core of GraalVM’s technology, directly impacting performance, security, and ease of use across all supported languages.
Changes in the Polyglot Runtime and Truffle Framework are key. The decision to publish all POM artifacts for languages and tools under an open-source license effectively means developers using build systems like Maven or Gradle can manage dependencies and integrate GraalVM languages into their projects much more easily, without licensing hurdles. Equally important is strengthened memory isolation between isolates - separate “mini-VMs” within a single process, each with its own heap. Stronger isolation ensures code in one context can’t “see” data from another, and crashes/leaks are better contained within their sandbox. This is critical for multi-tenancy (many customers on one instance) and for running not-fully-trusted code.
Truffle itself received two significant optimizations. Deoptimization-cycle detection addresses cases where the JIT optimizes a fragment too aggressively and then has to back out—over and over. The mechanism now detects this ping-pong and stabilizes execution, improving p95/p99 latencies. The extended Dynamic Object Model Layout is smarter about “laying out” shapeshifting objects (typical for JS/Python), yielding faster field access and less costly dynamism on hot paths.
Heads-up: rumors about big GraalVM changes came from an unfortunately worded Oracle post. Right now it looks more like a communications misstep than a real overhaul. Let’s hold judgment until the GraalVM team posts something official; for now, things look steady, though the formal release post is still pending.
4. Sneak peak into the future - Project Valhalla's first big JEP

And speaking of long journeys, let's peak into the future, because the community is buzzing as the holy grail (pun intended) of JVM optimization - Project Valhalla - has finally taken a monumental step forward. After more than a decade of work, the first major JEP from this project has officially been proposed: JEP 401: Value Classes and Objects (Preview). It addresses one of Java’s fundamental problems: the memory and performance overhead associated with objects.
JEP 401 introduces value classes - a special kind of class that gives up object identity (you can’t use == to compare references or synchronize on them) in exchange for massive performance gains. They are perfect for immutable data carriers, such as DTOs or coordinates. It’s the realization of the idea: “code like a class, run like an int.”
The main benefit is flattening objects in memory. Without headers and identity, the JVM can lay them out as densely as primitives, for example in arrays as a single contiguous block of data: [x0, y0, x1, y1, ...]. This leads to drastic memory savings, better cache locality, and reduced pressure on the Garbage Collector.
Although this is a giant milestone, it’s still just the beginning. JEP 401 is currently in preview and won’t land in JDK 25, but there’s hope for its arrival in JDK 26 or 27 - as a Preview, of course. The first version will come with limitations - for example, flattening will mainly apply to objects that fit within a machine word, to avoid concurrency issues. Further steps, such as support for generics, will be delivered in subsequent JEPs. One thing, however, is certain: the path to a much more memory-efficient Java has now been clearly marked.

See you next week!