

December / January Wrap Up and Release Radar - JVM Weekly vol. 160
I’ve gathered many interesting links that didn’t make it into previous issues. Many aren’t extensive enough for a full section, but they still seem compelling enough to share.


Also: we’re publishing this issue a week earlier than usual, because I’m on vacation next one 😉. To make up for it, this edition is a combined one (December + January). December edition didn’t happened due to holidays - so we’ll catch up with one solid package.
1. Missed in December / January

Let’s start with a small celebration - JetBrains is marking an extraordinary milestone: IntelliJ IDEA turns 25 this year! 🎉 The first release of the IDE appeared in January 2001 and was one of the very first Java development environments to offer advanced code navigation and built-in refactoring capabilities. I have to admit, it never occurred to me that it’s only five years younger than Java itself 😃.
To celebrate the anniversary, JetBrains prepared a special page with a game in which Runzo - the mascot of the Run button - breaks free from the IDE and travels across the IntelliJ IDEA universe.
PS: The game was created by Alexander Chatzizacharias - if you’ve never seen his talks, make sure to catch up. Pure joy and true hacker energy.
InfoQ has released the Java Trends Report 2025, and it’s packed with insights.
In the 2024 edition, you could still feel the post–AI-carnival sobriety (“wild west”, less of a hammer-for-everything mindset, more common sense).
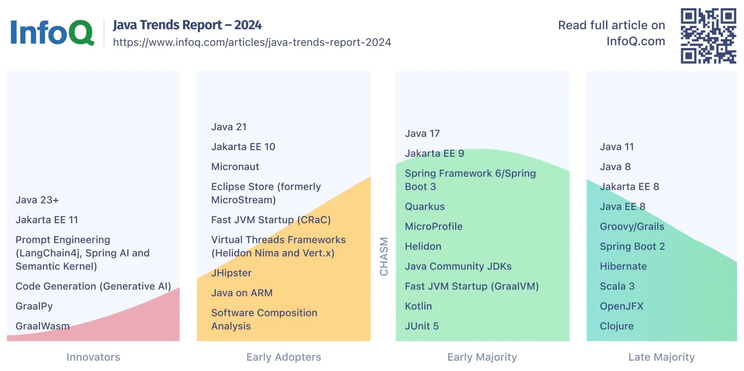
In 2025, AI on the JVM looks less like an exotic animal in a zoo and more like a new neighbor in the apartment block: it has its own frameworks and libraries (the report mentions, among others, Spring AI, LangChain4j, and friends), so the conversation shifts from “should we?” to “how do we deliver this sensibly?”.
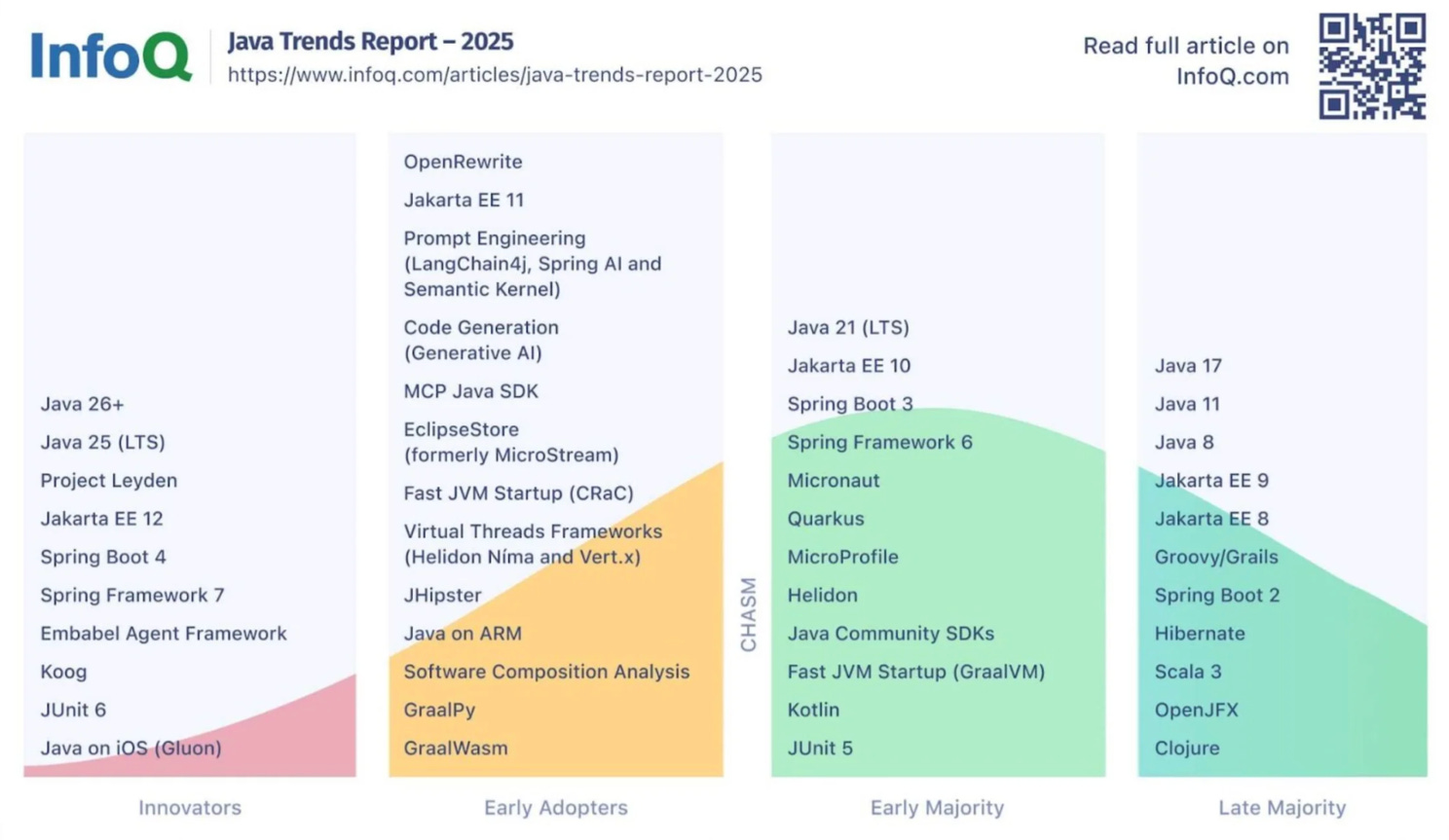
The second big change is modernization - in 2025 it’s no longer a side note but a full-fledged program, with automation front and center. The report explicitly points to OpenRewrite is there as the dominant tool for industrial-scale upgrades and refactoring, which sounds like another step toward a world where we stop doing “heroic migrations” and start simply… running them in the pipeline. And when it comes to Java versions: 2024 liked to count adoption (17, 11, 8… and a cautious approach to 21), while 2025 leans harder into the “baseline” narrative - Java 17+ as the new normal, with Java 25 as a symbolic anchor: “modernity isn’t a hobby, it’s the standard.”
As you see, there is far more different changes - personally, I’m still eager to see Java on Arm and CRaC moved to Early Majority, but we probably need to wait till the 2026.
Here we go again - not a repeat of Log4Shell, but still serious. On December 19, 2025, a new vulnerability (CVE-2025-68161) was disclosed in Apache Log4j Core, affecting versions from 2.0-beta9 up to 2.25.2. December once again reminded us that security-related technical debt never truly disappears, even four years after the original Log4Shell incident.
The issue resides in the SocketAppender component, which sends logs over the network to a remote log server. Affected versions did not properly enforce TLS hostname verification, meaning the client could accept any certificate issued by a trusted CA - even for the wrong domain. This opens the door to Man-in-the-Middle attacks and potential leakage of sensitive data often found in logs (tokens, personal data, SQL fragments).
The fix is straightforward: upgrade to Log4j 2.25.3, which restores strict hostname verification. As always, teams should urgently scan not only direct but also transitive dependencies - Log4j has a habit of hiding where you least expect it.
Adam Bien AirHacks delivers as always, but this episode is a real gem. In the latest AirHacks.fm conversation, Thomas Wuerthinger walks through the current direction and future of GraalVM - from changes in release cadence and a focus on Java LTS versions only, through the growing importance of Python and AI, to the increasingly tight integration with Oracle Database.
The discussion spans Oracle Multilingual Engine, running Python and JavaScript directly inside the database, native images as stored procedures, database-native serverless and scale-to-zero, CRaC-like application snapshotting in user space, WebAssembly as a deployment target for edge functions, and very concrete insights into why native image matters beyond startup time...
Together, it paints a picture of GraalVM evolving from a startup-time optimization tool into a foundational platform for running business logic closer to the data. And taking into account recent lack of insight into project, such a peek into the belly of the beast is always interesting.
An important update for the unit testing community: Tim van der Lippe has announced that he is stepping down as a maintainer of Mockito after a decade of work. His departure is a loud warning signal about the relationship between platform developers and library maintainers in the Java ecosystem.
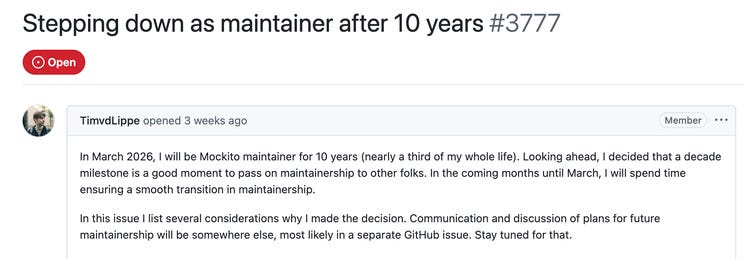
At the technical core of the issue are changes introduced in OpenJDK starting with Java 22, related to dynamic JVM agent attachment. Mockito relies on deep bytecode manipulation at runtime to mock final classes, static methods, or private methods - historically achieved via dynamically attaching a Java agent. In the name of security (“Integrity by Default”), the JVM now requires explicit user opt-in for such behavior. While the goal is reasonable from a platform security perspective, Tim argues that the changes were effectively a “done deal,” introduced without providing alternative APIs that would allow library authors to achieve the same goals in a supported, safe way.
Tim’s exit - and his move to the Servo project written in Rust - highlights a deeper, systemic problem. Libraries like Mockito are critical infrastructure for millions of Java tests. When platform-level decisions force hundreds of hours of unpaid work onto volunteer maintainers, the model starts to break down. The ecosystem doesn’t just lose code - it loses hard-won expertise. The fact that a maintainer of Tim’s caliber is seeking “joy in programming” outside the JVM should be a moment of reflection for Java’s architects - even if it’s very hard to argue with their argumentation about cleaning up the platform.
And last but not least in that section... we started with the celebration, we will end with a celebration: We have another Polish Java Champion - Grzegorz Piwowarek!

Grzegorz is the leader of Warsaw Java User Group, a program committee member of JDD and 4Developers, author of 4comprehension.com - and also the current maintainer of Vavr. Over the years, he has delivered 150+ conference talks and 85+ hands-on workshops, shaping both the Polish and international Java communities.
A well-deserved recognition - and a perfect segue into the next section.
We are starting Release Radar.
2. Release Radar

Vavr 0.11.0
The segue was a natural one: the library now maintained by Grzegorz, Vavr, has just released Vavr 0.11.0 - its first minor release in several years.
For these who do not remember - Vavr is a non-commercial functional library for Java 8+, designed to reduce boilerplate through immutable collections, pattern matching, and monadic types such as Option, Try, and Either.
The most notable addition is a lazy for-comprehension API that accepts functions instead of eagerly evaluated values, enabling more efficient operation chaining. Vavr now also integrates JSpecify annotations, improving null-safety support in IDEs and static analysis tools. Future cancellation has been refined as well: tasks that have not yet started can now be cancelled. The release also introduces several new APIs, including Either/Validation.cond(), Value.mapTo(U), Value.mapToVoid(), and Try.toEither(Throwable -> L).
From here, project is shifting focus toward Vavr 1.0.0, which is expected to bring a significant increase in the required Java version.
More details are available in the Release Notes.
Kotlin 2.3.0
JetBrains has released Kotlin 2.3.0 with a rich set of improvements across the language and its ecosystems. At the language level, more features are now stable and enabled by default, a checker for unused return values has been added, and explicit backing fields provide finer control over properties. Kotlin/JVM now adds support for Java 25.
Meanwhile, Kotlin/Native improves interoperability through Swift export and delivers faster release build times. Kotlin/Wasm gains fully qualified names and a new exception-handling proposal enabled by default, along with compact Latin-1 string storage.
Kotlin/JS introduces experimental export of suspend functions, a new representation for LongArray, and unified access to companion objects. Gradle 9.0 is now fully supported, together with a new API for registering generated sources. The standard library brings a stable time-measurement API and improved UUID generation and parsing, while the Compose compiler adds stack traces for minified Android applications.
More details are available in the Release Notes and video with new features demoed:
IntelliJ IDEA 2025.3
And now it’s time for the birthday star!
As I already mentioned in my year-in-review (this is what happens when there’s no Rest of the Story edition in December), JetBrains has introduced a fundamental change to its distribution model: IntelliJ IDEA 2025.3 is now a unified product, with no separate Community and Ultimate editions. This is a real shift for developers who previously had to choose between a free but limited version and a paid, full-featured one. All features from the former Community edition remain free, and JetBrains has additionally made basic support for Spring, Jakarta EE, and template engines like Thymeleaf available at no cost.
This change means that even small teams and individual developers can now use professional tools for working with popular enterprise frameworks without extra expense. JetBrains is clearly betting on a model where advanced AI features and additional integrations remain paid, while a solid, high-quality foundation for everyday development is accessible to everyone.
Two feature highlights worth calling out in IntelliJ IDEA 2025.3 are the open, integrated AI experience and the new multi-agent workflow. JetBrains AI is no longer a black box: you can now see and track your AI credits directly inside the IDE, use multiple agents from a single chat interface, and work with both JetBrains’ own Junie and the natively integrated Claude Agent. On top of that, Bring Your Own Key (BYOK) lets you connect your own OpenAI, Anthropic, or OpenAI-compatible local models, giving teams far more control over providers, costs, and data flows.
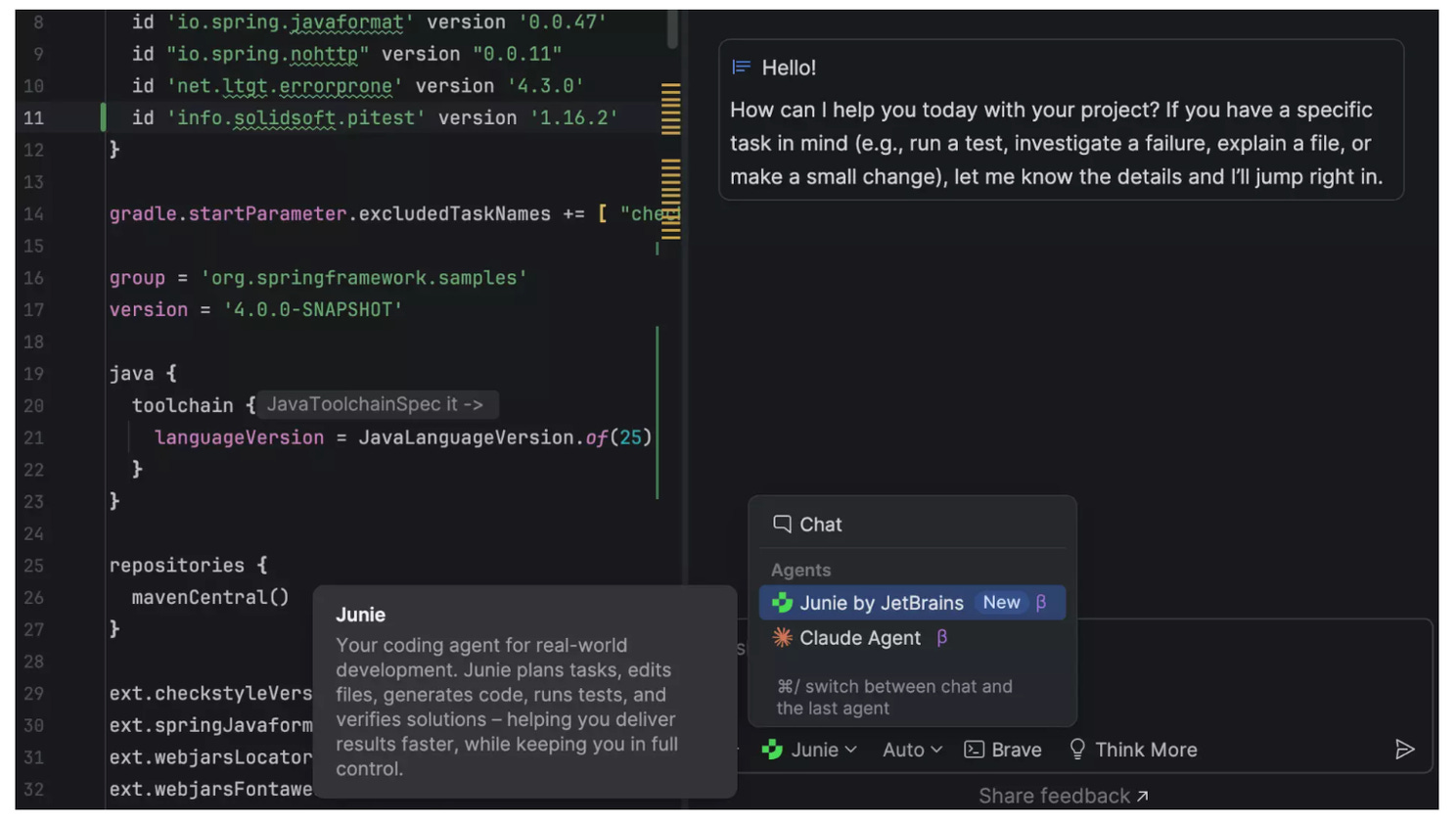
Another notable feature is command completion, which brings IDE actions directly into code completion. Typing . now shows not only code and postfix completions, but also relevant actions, while .. filters the list to actions only. You can preview exactly what an action will do before applying it, reducing context switches and shortcut hunting. It’s a small change with a big impact on flow - making powerful IDE features feel like a natural extension of typing code rather than something hidden behind menus or keymaps.
More details are available on the What’s New page. And here you can find video where 👩🏻💻 Marit van Dijk, Marco Behler, 👓 Anton Arhipov and Siva Prasad Reddy K present new editor capabilities.
WildFly 39
WildFly 39 brings improvements in clustering, an area that matters whenever you run applications on more than one node. A key part of this is better TLS support for JGroups - a Java library used by WildFly (and many other systems) to handle node discovery, group membership, and reliable message exchange between servers in a cluster. With this release, TLS can now be configured directly for TCP-based JGroups transports, making it easier to secure inter-node communication and potentially replace older encryption setups such as ASYM_ENCRYPT with the simpler AUTH mechanism.
WildFly 39 also adds time-based HTTP session eviction, giving administrators more flexible control over memory usage when session data sizes vary widely. Alongside these features, the release updates core components and fixes multiple security issues, enforces stricter HTTP compliance by always requiring the Host header for HTTP/1.1+ requests, and introduces a 1GB limit for deployments uploaded over HTTP.
Full details are available in the Release Notes.
JobRunr 8.4
JobRunr 8.4 continues its Kotlin-first push with improved Bazel compatibility, auto-configured serialization, and full support for Micronaut 4.10.
JobRunr is a background job processing library for Java and Kotlin that lets you define and run reliable, persistent background tasks (such as emails, data processing, or scheduled work) using plain Java or Kotlin code, without requiring a separate queue system. In this release, Kotlin lambdas compiled with Bazel’s rules_kotlin now work seamlessly, fixing long-standing NullPointerException issues when enqueueing Kotlin lambdas. Serialization gets smarter as well: KotlinxSerializationJsonMapper is automatically detected and configured when kotlinx-serialization-json is present on the classpath, while Jackson3JsonMapper now supports custom polymorphic type validators for improved security.
JobRunr Pro adds flexible license key loading, configurable graceful shutdown when the storage layer becomes unavailable, and dashboard improvements like logout and exception-type filtering.
More details are available in the Release Notes.
Gradle 9.3.0
Gradle 9.3.0 is a release that significantly improves the developer experience, especially around testing.
The headline feature is a completely redesigned HTML test report: instead of a flat list of tests, it now presents a hierarchical structure that mirrors your actual code organization.
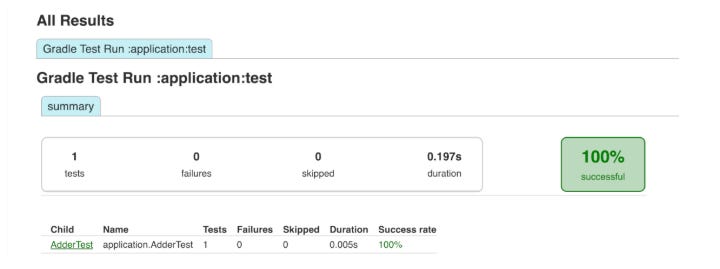
Nested tests appear nested, parameterized tests are grouped under their defining method, and test suites clearly contain the classes they execute. Even more importantly, test output (stdout/stderr) is no longer merged at the class level - you can now see exactly which test produced which log line. This may sound minor, but in practice it means no more digging through hundreds of lines of output asking “which test actually failed?”. For builds aggregating tests from multiple subprojects, the report now also handles overlapping names correctly and shows each source as a separate tab.
For build and plugin authors, there are several practical improvements as well. The new AttributeContainer.named() API allows for more concise configuration of dependency resolution attributes, while TestKit gains getOutputReader(), enabling streaming of test output instead of loading massive logs into memory during integration tests. The release also fixes two security vulnerabilities related to dependency repositories: previously, repositories were not reliably disabled after hostname or timeout errors, potentially exposing builds to malicious artifacts. Repository disabling is now stricter, and all Gradle distributions are shipped with PGP signatures (.asc), aligning with broader efforts to improve supply chain integrity.
More details are available in the Release Notes.
Spock 2.4
Spock Framework 2.4 - one of the most popular mock tests frameworks - is a long-awaited version which arrives more than three years after 2.3 (September 2022) and its most important change is support for Groovy 5.0, which is a major milestone for the ecosystem. Groovy 5 requires Java 11+ and introduces its own breaking changes, forcing substantial internal refactoring in Spock (the _ identifier becoming a reserved keyword in Java 9+ was a particularly painful example). At the same time, Spock continues to support Groovy 2.5, 3.0, 4.0, and now 5.0, allowing teams to upgrade at their own pace.
More details are available in the Release Notes.
Spring gRPC 1.0.0 GA
Spring gRPC 1.0.0 is the first official, fully supported integration of gRPC into the Spring ecosystem, with full compatibility for Spring Boot 4 and Spring Framework 7. One important architectural decision stands out: the autoconfiguration and starter dependencies are deprecated right at the 1.0 release. This is intentional - Spring gRPC 1.1 (targeting Spring Boot 4.1) will move all autoconfiguration directly into Spring Boot itself. In practice, Spring gRPC 1.0 acts as a transitional release, giving teams time to upgrade while signaling that gRPC support will soon be a first-class, built-in Spring Boot feature. The framework requires Java 17 as a baseline and already supports Java 25 as the latest LTS, with JSpecify annotations aligning it with Spring Framework 7’s stronger focus on null-safety and Kotlin-friendly APIs.
From a developer experience perspective, the key theme is simplicity. To get started, you add the spring-grpc-spring-boot-starter, define your .proto file, and implement a Spring @Service that extends the generated ImplBase (or implements BindableService). The gRPC server starts automatically on port 9090 - no manual wiring required. This is a major improvement over older community solutions (such as the now-abandoned LogNet starter), which required extensive configuration. Out of the box, you get integration with Spring Security (OAuth2, TLS/mTLS), Micrometer for observability, and Spring Boot DevTools for hot reload.
Spring Tools 5.0.0
Spring Tools 5.0.0 is also an important update. The headline feature is Logical Structure View - a conceptual project view that organizes code by Spring stereotypes (controllers, services, repositories, entities) instead of folders and packages. This reflects how developers actually reason about Spring architectures and was designed in collaboration with Spring Modulith and jMolecules. The view supports custom stereotypes via META-INF/jmolecules-stereotypes.json or @Stereotype annotations and automatically aligns with Spring Modulith when present. On top of that, Spring Tools 5 delivers deep support for Spring Boot 4 and Spring Framework 7: API versioning with CodeLens summaries and validation, functional bean definitions via the new BeanRegistrar API, AOT repositories in Spring Data with SQL visualization, and automatic JSpecify-based null-safety analysis.
The second major pillar of this release is AI-native tooling. Spring Tools 5 integrates with Cursor and Copilot, but the most interesting addition is an embedded Model Context Protocol (MCP) server. This experimental feature allows AI coding assistants - including CLI-based tools like Claude Code - to access rich, Spring-specific context such as resolved classpaths, Spring Boot versions, bean definitions, dependencies, and architectural stereotypes. The MCP server runs inside Spring Tools and works only with an open project, but in return enables far more precise and architecture-aware AI assistance. The release also introduces AI-powered code actions for explaining SQL queries, SpEL expressions, pointcuts, and converting functional web routes.
More details are available in the Release Notes.
Hibernate ORM 7.2.0
Hibernate ORM 7.2.0 is headlined by experimental support for reading data from read-only replicas of the primary database. The release adds the new @EmbeddedTable annotation, significantly simplifying the mapping of embedded values to separate tables and reducing the need for verbose @AttributeOverride and @AssociationOverride configurations.
It also introduces FindMultipleOption, filling a long-standing gap in Session#findMultiple configuration, enables creation of child StatelessSession instances that share transactional context with a parent, expands the hibernate-vector module with SQL Server support, and adds regular expression support in HQL along with further enhancements to the SchemaManager.
More details are available in the Release Notes.
TornadoVM 2.x - GPU acceleration for Java, now more practical
TornadoVM 2.x represents a major step toward making GPU and accelerator offloading practical for JVM applications. Whereas earlier versions of TornadoVM were primarily research-oriented, 2.0 and subsequent 2.1+ releases usher in a more production-ready SDK with prebuilt binaries and easier integration into Java projects (available via standard dependencies and soon also via SDKMAN!) instead of requiring building from source.
The core idea remains the same: TornadoVM acts as a plugin for OpenJDK/GraalVM that compiles and offloads parts of your Java code to heterogeneous hardware like dedicated GPUs, integrated GPUs, FPGAs, and multi-core CPUs - targeting backends such as OpenCL, NVIDIA PTX, and SPIR-V - without rewriting in CUDA or native languages. It accomplishes this by generating accelerator-friendly kernels from annotated Java code, managing data movement between the JVM and device memory, and handling execution on the target hardware.
The 2.x series introduces important performance-oriented features: native support for INT8 data types on PTX/OpenCL (critical for quantized machine-learning workloads), FP32↔FP16 conversion across all backends for efficient half-precision computation, zero-copy native arrays that eliminate host↔device transfer overhead, and support for half-float operations such as Q8_0 matrices that boost throughput in ML kernels like those used in LLM inference.
Subsequent releases (e.g., 2.1.0) include enhancements such as improved FP16 handling and expanded array support. TornadoVM keeps two complementary APIs: a high-level Loop Parallel API using annotations like @Parallel and @Reduce for data parallelism, and a lower-level Kernel API with explicit control over threads, local memory, and barriers for experienced accelerator programmers - all while preserving multi-vendor portability.
TornadoInsight
Tooling around the SDK is improving too, with IDE support. TornadoInsight is an IntelliJ IDEA plugin developed alongside TornadoVM 2.x that fundamentally improves the developer experience of GPU acceleration in Java by making what used to be opaque and log-driven fully visible inside the IDE. Instead of manually inspecting kernel dumps and thread logs, developers get a graphical TaskGraph visualization showing how Java code is compiled into GPU kernels, how tasks depend on each other, where host <-> device memory transfers occur, and which phases are the real performance bottlenecks.
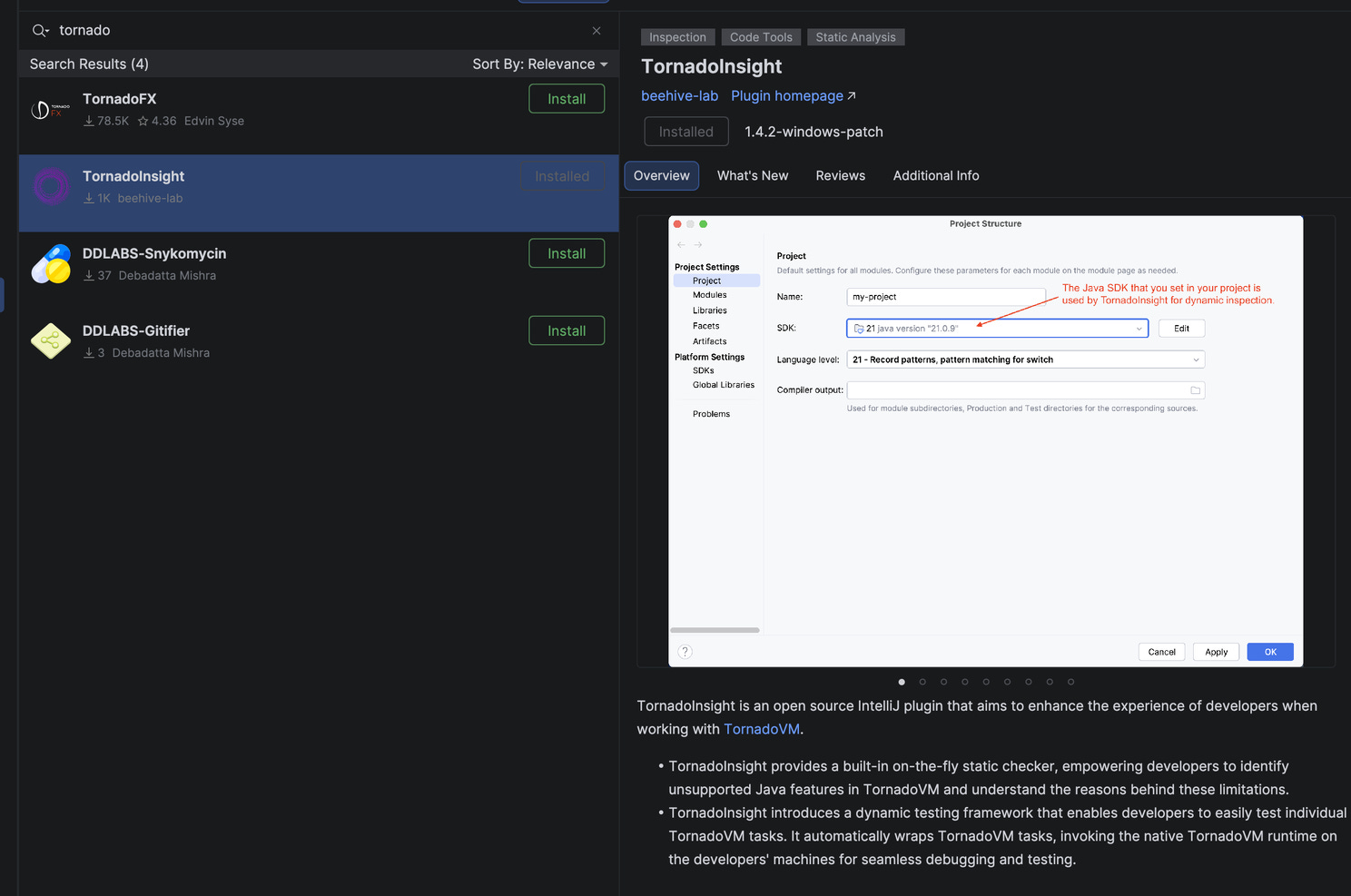
The plugin integrates with the IntelliJ profiler to break execution down into compilation time, memory transfer overhead, and actual kernel runtime, and adds navigation between Java source and generated GPU code, syntax highlighting for TornadoVM’s intermediate bytecode, and side-by-side device comparison across different GPUs or backends.
For teams optimizing compute-heavy workloads or porting CUDA/OpenCL code to TornadoVM, TornadoInsight goal is to turn GPU acceleration from trial-and-error into an inspectable, iterative workflow.
LangChain4j 1.10.0
The headline feature of LangChain4j 1.10.0 is the Model Catalog, a unified discovery and configuration layer for providers like Anthropic, Gemini, OpenAI, and Mistral, allowing developers to reference models by semantic names instead of hard-coding specific model IDs - and enabling automatic upgrades or graceful fallbacks to cheaper models without redeploying applications. The Anthropic integration received a significant upgrade with structured outputs (direct JSON-to-POJO deserialization via JSON Schema), strictTools mode to reduce tool-calling hallucinations, access to raw HTTP/SSE events for advanced observability, and native PDF input via URL.
On the production side, new AgentListener and AgentMonitor APIs provide fine-grained visibility into agent reasoning steps, tool usage, latency, and token consumption, which is critical for debugging and cost control. AI Services now support per-call tuning via ChatRequestParameters, MCP support has been hardened for real-world networking scenarios, OpenAI integration adds native transcription support, Gemini improves schema handling and batch processing, and the deprecated GitHub Models module signals a pragmatic focus on mainstream providers.
Full details are available in the Release Notes.
OmniFaces 5.0
Anyone remember what OmniFaces actually is? 😉 If you’ve ever built a serious Java Server Faces application (I’m so sorry), the answer comes back fast - and OmniFaces 5.0 - set of JSF components - proves it’s very much alive. Released in December 2025, this major version cleans up years of legacy decisions and aligns the project with Jakarta EE 11, raising the baseline to Java 17 and Faces 4.1.
The most visible change is the switch to a URN-based XML namespace (xmlns:o=”omnifaces”), merging the old UI and functions namespaces into one (with full backward compatibility across the 5.x line). All APIs deprecated in 4.x were physically removed, several components were renamed for consistency with Jakarta Faces, resource handling was modernized, and bundled JavaScript was migrated to TypeScript.
At the same time, OmniFaces adds small but practical new APIs (like HTML5 doctype detection and safe HTTP response resets) and continues to support cloud-native deployments via a Quarkus extension - a reminder that despite its “legacy” reputation, the JSF ecosystem still has an active community solving real enterprise problems (so sorry, once again).
More details are available in the Release Notes.
3. GitHub All-Stars

Juicemacs
Juicemacs is a project by Kana (gudzpoz) that’s both crazy and brilliant at the same time - a reimplementation of the legendary Emacs editor in Java, built on top of the Graal Truffle framework. Thanks to Truffle, Emacs Lisp (ELisp) code can be JIT-compiled to native machine code, potentially delivering performance that classic C-based Emacs can’t reach (due to Lisp evaluator, not C).
Juicemacs currently ships with two working interpreters (one AST-based and one bytecode-based) and enough built-in functionality to support pdump. It’s a fascinating demonstration of GraalVM’s polyglot power - running languages like ELisp on a shared runtime with full interoperability. The author presented the project at EmacsConf 2025, showcasing experimental optimizations such as constant folding for stable global variables.
BTW: There are two fantastic blog[1] posts[2] about creating the projects. I will play a bit with this and probably return to the topic in one of the future editions.
Annote
Staying in the Lisp regions - Annote is… an experiment you have to see to believe.
Annote is an interpreter that executes Java annotations as a programming language - variables, conditionals, loops, I/O, arithmetic, and method calls, all expressed via @Var, @If, @Loop, @Print, and similar annotations. Just... take a look.
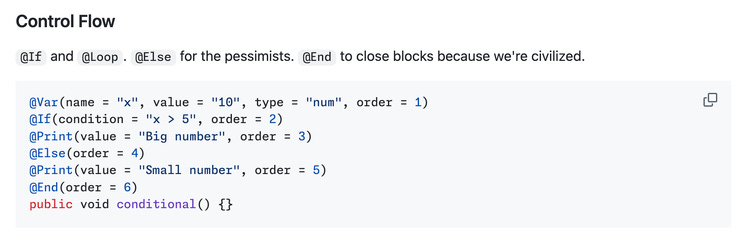
Java annotations were designed for metadata. Spring uses them for dependency injection. Lombok for code generation. JPA for ORM mapping. Annote uses them to write entire programs. Is it practical? Absolutely not. Is it a fascinating experiment that exposes the limits of Java’s annotation system? Definitely.

But in positive sense! I think we just found 2026’s edition of Annotatomania.
MIT licensed - because even cursed code deserves freedom.
BTW: I love how this repository was weaponized in ongoing war with Skynet 😀

Hardwood
Hardwood is a minimalist implementation of Apache Parquet for Java, created by Gunnar Morling (yeah, the one behind 1BRC). It provides an API compatible with parquet-java, enabling migration with minimal code changes.
Parquet is a columnar file format for tabular data, optimized for analytics by enabling efficient storage, compression, and fast reads of only the needed columns (e.g. in Spark or BigQuery).
In benchmark tests on 44 million rows, Hardwood processes data in about 19 seconds, compared to 84 seconds for parquet-java. It achieves this by parallelizing column processing across CPU cores. For projects dealing with large Parquet datasets, this is a very compelling alternative.
jMigrate
jMigrate is a small, lightweight database schema migration library positioned as an alternative to Flyway and Liquibase for projects that need less overhead. A single call to JMigrate.migrate() at application startup is enough to apply all pending migrations.
jMigrate compares the current set of migration scripts with the state recorded in database tables. If the state is “dirty,” it automatically rolls back to the last clean point and reapplies subsequent migrations. Production safety is handled via the allowExecutingDownScripts flag - recommended to be set to false in production to prevent accidental data loss.
zone-scope
zone-scope is a real-time audio visualization tool written in Java/Swing. It supports live audio capture (via JACK or JavaSound), loading audio files with precomputed FFT, and a spectrometer with adjustable frequency response (20 Hz–14 kHz) and a logarithmic frequency scale.
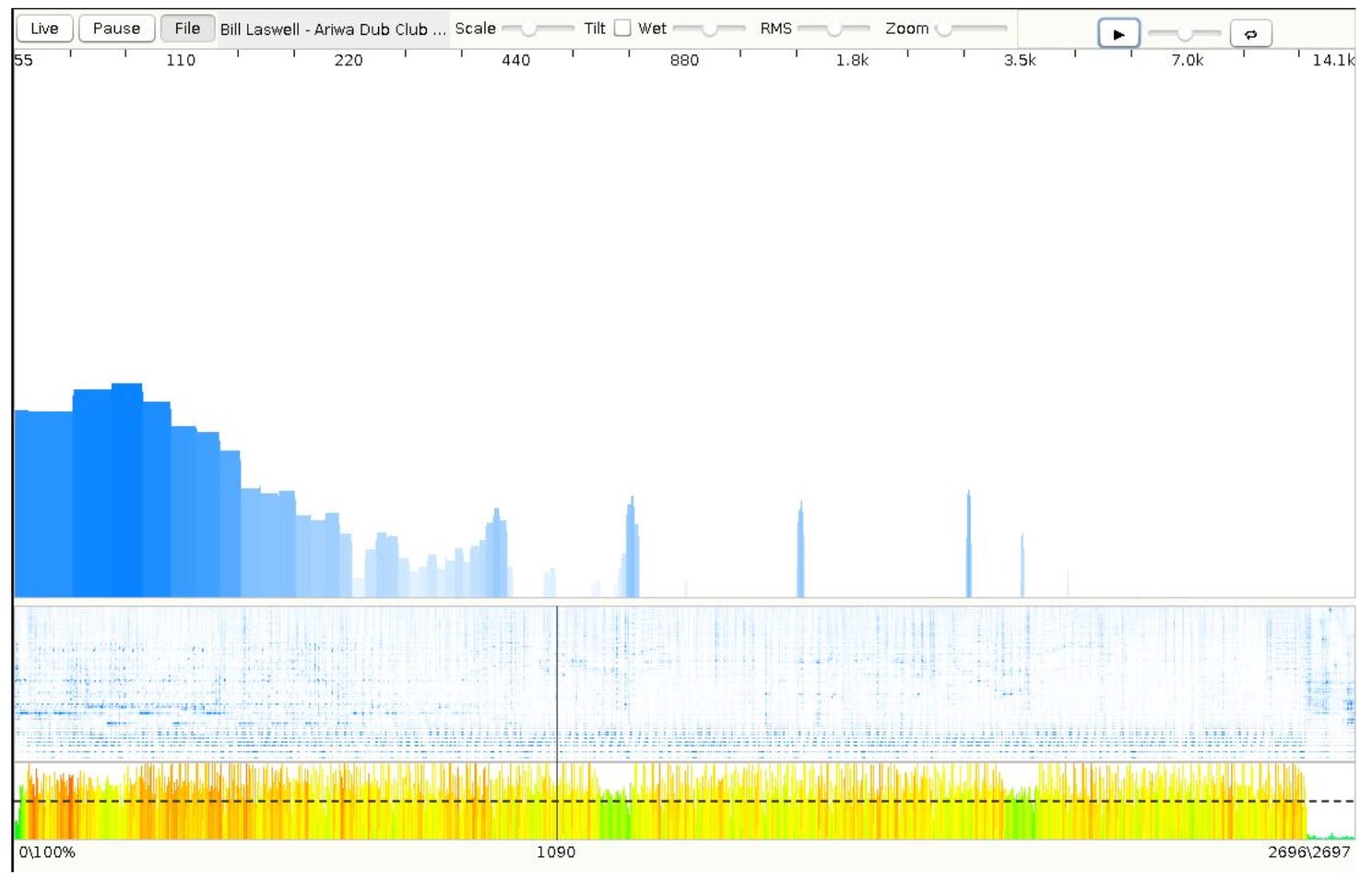
Its standout feature is a zero-copy real-time processing path — allocation-free audio callbacks suitable for continuous visualization. The project requires Java 21+ and is part of the larger JudahZone ecosystem for live looping. It’s a strong example that modern Java is perfectly capable of low-latency, multimedia-heavy workloads as well.