

Code Remix Summit: Postcard from Miami - JVM Weekly vol. 175
A shorter edition from the other side of the world, because determinism is back in the game.


This edition will be shorter than usual. I’ve been travelling a lot, I’m on a conference tour, and this week I managed to squeeze in the Code Remix Summit organised by Moderne. So instead of the usual news roundup - a postcard from the conference, with short teasers for the talks worth catching up on via the recordings once they’re up.

Because it’s worth saying upfront: I was there on my own dime - well, okay, on VirtusLab dime, on the picture up there I’m with Tomasz Orzechowski, our COO - without an invitation from Moderne , without a “write something nice about us” contract. We were just curious about what was going on. And I have to say, it was worth it. Sincere feedback, not sponsored content.

Code Remix Summit was very focused - and that’s a big plus for me. The whole conference revolves around one theme: scaling code changes. OpenRewrite, automated migrations, agentic refactoring, tooling for agents. No blockchain, no microservices-vs-monolith panels. Each talk connects to the previous one, in the hallways you bump into people who actually understand your problems with a 4-million-line codebase, and after you come home you have a coherent map instead of a random bag of ideas. In a world of “a bit of everything” conferences (which I do enjoy, by the way) - this kind of change of pace makes a difference.
OK, let’s get to it. I’m going in order, so if any of the talks catches your eye, you’ll easily find it on the playlist once it shows up (if I understand correctly how this will work).
1. “Making Changes at Scale” - Morgan Stanley

The opening of the conference. Dov B. Katz and Khalid Elsawaf from Morgan Stanley - a year of experience with OpenRewrite and Moderne in production. Very often, keynotes at conferences like these are dull. Either they go full “transformation, future, paradigm shift”, or they dive into a granular demo that no one has the head for in the morning. I especially liked quote, that this is a first time work in Software Engineering (Code Review) shifts right. Thant’s very interesting insight.
This one hit exactly the middle - lots of concrete ideas, zero pretending they’ve already solved everything - and a fair bit of riffing on the now-popular “code is cheap, software engineering is still expensive”. A perfect rhythm for the opening.
2. “Diff Risk Score: AI-Driven Risk-Aware Software Development” - Meta
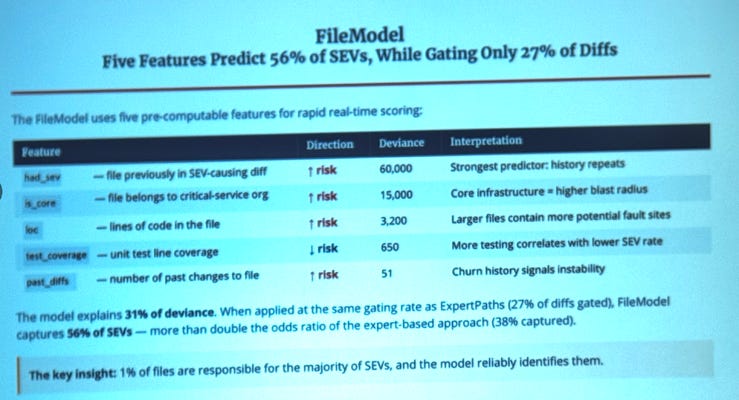
Rui Maranhao Abreu talked about Meta’s DRS - a model that predicts whether a given diff is likely to cause a customer-facing incident. Meta has wired this signal into the entire SDLC: from review, through testing, all the way to automated rollback plans.
What sold me the most was the part on Centrality - a graph of how a change ripples through the rest of the codebase, used as a model feature. Once again you can see that graphs are increasingly the core of developer tooling.
Bonus insight: figuring out which signal actually predicts risk - versus which one just looks pretty on a slide - is genuinely interesting work.
3. “Feature Flags: How to Ship Faster, Safer, and Smarter” - Wells Fargo

Dinesh Arora session was a bit more basic. What feature flags are, FF4J/Togglz in the demo, best practices. After the Meta and Morgan Stanley sessions - it’s a step down in complexity. But it was still interesting to hear what deployment challenges are showing up in banking. Wells Fargo has its own, very specific risk landscape, and that perspective made for a nice counterpoint.
4. “How Uber Migrated 75K JUnit4 Test Classes to JUnit5 Using OpenRewrite” - Uber

Anshuman Mishra and Kaushik Vejju - one of those sessions you go to conferences for if you’re into large-scale transformations. End-to-end, top-to-bottom migration: 75 thousand test classes, 400 thousand tests, 15M+ lines of code, 1.5M modified. Customisations for Uber’s monorepo, validation, rollout safety, CI integration. No magic, with concrete numbers. Anyone who’s ever tried something like that in their own organisation knows what I’m talking about.
Definitely worth at least flipping through the slides.
5. “Agentic Coding at Airbnb” - Airbnb

Szczepan Faber - yes, the Mockito creator, currently Engineering Leadership at Airbnb - on how they brought agentic coding into a monorepo with tens of millions of lines of code. Applications that have to be secure and compliant. Trade-offs, learnings, productivity impact. A very pragmatic approach to most of the problems - some things they have solved, some are still open, and they say so openly. A general overview of “how it’s done at Airbnb”. Refreshing.
6. “Shepherd: How We Handle Uber-Scale Migrations at Uber” - Uber

The gem of the conference. Anshuman Chadha and Sung Yoon Whang showed off Shepherd - Uber’s migration platform. 4.3M lines of code reworked, 30,000+ diffs across five monorepos, migrations going from “quarters of manual coordination” to “weeks with observability”. Deterministic compiler-aware transformations + AI-assisted remediation + ownership-aware routing + integrated validation.
I walked out of the session and immediately started looking for Shepherd-like solutions in the open source world - and I didn’t find any. This is exactly the level of abstraction where tools are missing today.
If you’ve got tokens to burn, you know what to do with them.
7. “Netflix’s Journey to Confident Automated Changes” - Netflix

Roberto Pérez Alcolea 🇲🇽 and Aubrey Chipman (what an energy, loved that!) showed how Netflix built a platform for deploying automated changes across thousands of repositories. The emphasis was on developer trust in automation: shift-left validation, feedback loops, impact analysis.
A few good ideas - for me mostly the thread around MCP as an interface to all this machinery, and the “beyond basic” skill repository.
Oh, and the slides were just fantastic design-wise, straight out of Wynwood Walls.

8. “Upgrade Your Java with AI: From Legacy Code to High-Performance Workloads” - AWS

Closing out my list. Vinicius Senger and Jonathan Vogel (both Senior Developer Advocates at AWS) - tying AI-assisted refactoring of legacy Java together with runtime analysis (Java Flight Recorder), a workflow built on top of Embabel agents. So not just “AI changes the code”, but also “AI checks whether the changed code actually runs faster in production”.
That missing loop - modernisation → measurable performance - is what a lot of tools still don’t have. Nice to see someone trying to close it. There’s a practical implementation - embabel/modernizer - to clone and play with on your own.
On top of that, if you remember Jonathan’s pieces from my “Rest of the Story” editions, here you could see the results of the research in practice... with a few extra goodies ready for part three 😁
Now a word about Moderne itself
After three days of listening to how Meta, Uber, Netflix, Morgan Stanley and Airbnb are putting OpenRewrite to work on production migrations, one common thread emerges. And this, in my view, is Moderne’s most important ideological move.
In a world where everything is heading toward the probabilistic - LLMs, agents, “maybe it’ll work, maybe not, but give it a shot” - Moderne is going against the grain. Deterministic, compiler-aware code transformations as the foundation. AI as a remedial layer where determinism ends. Not the other way around.

And that is a hugely healthy distribution of responsibility. If you know that a given refactor will always produce the same result on 4.3M lines of code - you can run it overnight without staring at the terminal. If you know an agent has bad days - you don’t want it deciding whether @RunWith gets swapped for @ExtendWith. Each of these talks - Meta with DRS, Uber with Shepherd, Netflix with their observability - was effectively about finding that boundary. Where does the deterministic part of the migration end, and where does “this is where the LLM has to step in” begin.
And this isn’t an idea that belongs to Moderne alone. Google has their Rosie - described in detail in Software Engineering at Google, and in the original Potvin/Levenberg CACM paper about the monorepo. Uber has Shepherd in a company-specific variant - the same piece from Anshuman Chadha’s talk, the same one they used to drive the JUnit 4 → 5 migration (orchestrating diffs across thousands of Bazel targets). Sourcegraph has been growing their Batch Changes since 2021, with changelog updates still going strong in April 2026.
And I have to admit - one of the bigger lessons from this trip was realising how much of this is out there in the industry. Listening to one talk after another, you can see that practically every organisation above a certain scale threshold has built its own variant of a large-scale-changes orchestrator. Most of them don’t have the motivation to talk about it publicly. And that’s exactly why a conference like Code Remix makes a difference - it’s one of the few moments in the year when these internal tools come out into the light.
The organisational problem of scaling changes can’t be solved with LLMs alone. LLMs are great at writing code. They’re poor at predictably repeating the same change 30,000 times in a row and reporting what went wrong.
Moderne is turning this into a product for the whole industry. Take Prethink - the concept is charmingly simple: instead of letting Claude search the codebase using tokens at runtime (expensive, slow, non-deterministic), you precompute a map of the system first. A set of OpenRewrite recipes generates data tables from the LST, the full dependency tree including transitive ones, an optional knowledge graph, plus architecture diagrams in FINOS CALM and Mermaid format. The result lands in CLAUDE.md and associated files - and the agent has it at hand before it even starts writing.
The open-source component lives under openrewrite/rewrite-prethink.
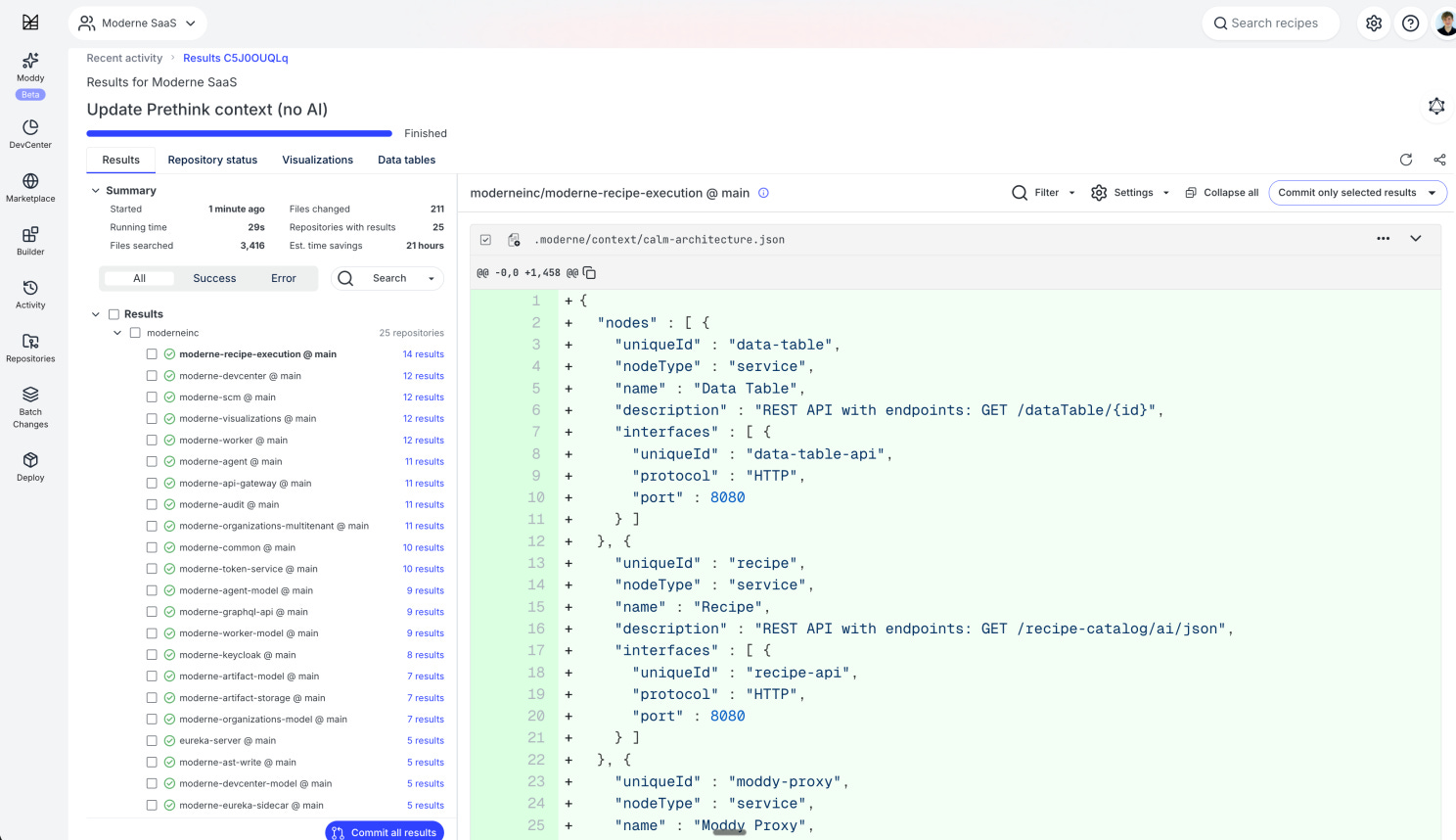
A small detail that closed the loop for me after I got back: CALM - that format Prethink uses for architecture diagrams - was open-sourced by Morgan Stanley in August 2025. The same firm that opened Code Remix with a talk about its year with OpenRewrite. The whole ecosystem is growing together, and you can see it.
Moderne’s cleanest framing goes like this: we’re shifting work from GPU inference to CPU precomputation. Cheap, deterministic calculation in the background. Expensive, probabilistic decisions in the foreground. And Prethink is the tangible form of that idea - something you can pull from GitHub and run today.
There’s also the community angle. Because just like with JobRunr - it’s really nice to see another generation of products growing out of Java open source. JobRunr grew from a library into a solid platform with a commercial variant. OpenRewrite grew from a little refactoring library into Moderne - a whole infrastructure for agents, an agent-tools company, as they now call themselves. This is exactly what the JVM ecosystem needs. Good patterns.
Cheers, Moderne team. Jonathan Schneider Rooz Mohazzabi Paula Paul Tim te Beek Matt Finkelstein Robert Sobieski (Poland strong!) Jaida Olvera Alters Antony Austin Jente Sondervorst and all the rest - it was a great job 😊
Also, I loved the dog - it was charming.

PS: I still remember the party at Devoxx Belgium 2024, BTW 😊
Whether you use OpenRewrite or not - “what’s deterministic and what’s probabilistic in my pipeline” is the question every mature developer platform will be asking itself in 2026.

-PS: A really nice moment - completely by chance I bumped into Jonathan Vogel in person (yes, the one from the AWS talk), who you may know from recent Rest of the Story editions. The internet is a weird place, but conferences still make a difference.

PS2: Tomorrow we’ll see each other at geecon in Kraków. I have a talk there about agentic architectures based on my Kotlin NES emulator that plays Final Fantasy I. Drop by - let’s chat in person.
PS3: From the JVM Weekly in Strange Places series: Miami Airport.