

Code Reflection ❤️ Triton: Further improvements to GPU programming in Java - JVM Weekly vol. 74
Today we return to text form, with new JEPs, Code Reflection and a mega interesting Release Radar.


1. New JEPs - improvements to CDS, Generational ZGC and Markdown in documentation

JEP draft: (draft) Unified storage for application cache (aka "new CDS workflow")
It's rare for me to report on JEPs at this early stage, but I particularly liked this one. Unified storage for application cache (aka "new CDS workflow) aims to unify the storage location for application cache data, being a new iteration of the Class-Data Sharing mechanism. It aims to expand the use of CDS, at the moment used to store class metadata, so that it can be used as a cache for a wider range of data types, such as AOT compiled methods. It is also planned to clean up the way CDS is handled (which has evolved in an ad hoc manner over the years) by introducing a single -XX:CacheDataStore flag, which specifies the location of the store. Initially, the store will consist of a single file, but in the future, it may contain multiple files, potentially hierarchical.
For now, this is all we know at this early stage, so details may still change. However, it still gives us a preview of how the various mechanisms to improve cold start applications will combine in the future.
JEP draft: Deprecate Non-Generational ZGC
Continuing the theme of drafts, another of the interesting new features is Deprecate Non-Generational ZGC. The Generational variant of ZGC has only just been introduced to ZGC, and plans are already emerging to deprecate the non-generational version, with the intention of removing it in future releases. The main aim is to reduce maintenance costs and the technical debt arising from operating two different modes of operation. Non-Generational ZGC, although it will not be removed as part of this JEP and will probably stay with us for longer, will become the less preferred mode as Generational ZGC, introduced in JEP 439, is seen as a better solution in most use cases.
JEP 467: Markdown Documentation Comments
JEP 467, on the other hand, is finally a JEP-candidate that aims to make it possible to write JavaDoc documentation in Markdown, instead of solely in a mixture of HTML and JavaDoc tags. Let's face it, Markdown has for years been the solution that reigns supreme when it comes to creating technical documentation, and has de facto become the standard to the point where pretty much every IDE or Code Editor has great support for it.

The aim, of course, is to make API comments easier to write and read. Creating documentation is a difficult, tedious process regardless of the markup chosen, and having to use HTML (ergo a quasi-XML language), which is less intuitive for humans, does not help. Recently, there has been a trend that and more often generated from other markup languages that are more 'human-friendly'. Markdown is not only a popular markup language for simple documents, it is easy to read, create and transform into HTML, making it an ideal choice for documentation comments, which are usually not complex structured documents.... and we probably wouldn't want them to become such.
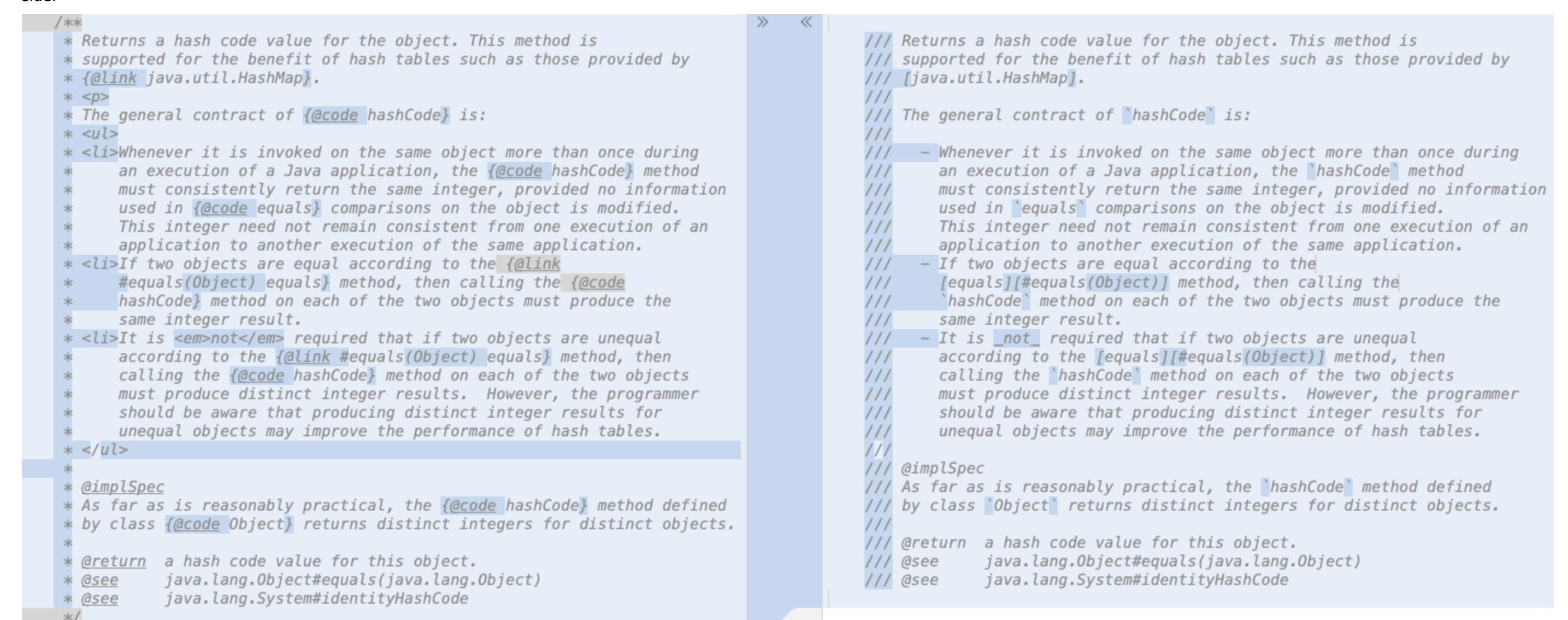
How should this work in practice? Using the comment example for the hashCode method, you can see the difference in using Markdown, where lines start with /// instead of the traditional /** ... */. HTML is not required to indicate a paragraph break; a blank line is sufficient. HTML elements such as <ul> and <li> are replaced by Markdown bulleted list tags, using - to indicate the start of each list element. Instead of <em>, underscores (_) are used to indicate a font change, and instances of the {@code ...} tag are replaced by reverse apostrophe characters (`) to indicate a fixed-width font, often used for code samples.
It has probably also been a long time since any JEP has been so heavily discussed on Reddit. The feedback from the community, apart from the general enthusiasm (for that certainly accompanies the solution), reveals several major concerns. Firstly, many find the requirement to use three slashes for documentation comments inconvenient, suggesting an attempt to develop some sort of more concise notation - and that one I strongly agree, although the fact that all lines have the same prefix on the other hand affects readability. In addition, the discussion raises concerns about the long-term viability and flexibility of such a syntax choice (three slashes), wondering what will happen if the new markup language gains popularity in the future (Ron Pressler himself was involved in the conversation). Also pointed out is the lack of any meaningful alternative to JavaDoc tags, which continue to have to be mixed with Markdown in its classic form. Despite the above feedback, the reception is positive, and given that this is already a candidate JEP and not, for example, a Preview, I don't expect any more far-reaching changes.

2. Triton - Another approach to GPU programming from Project Babylon

Now, let's look at the Babylon project once again this year. For the recent publication of Paul Sandoz's Exploring Triton GPU programming for neural networks in Java, another attempt to use Code Reflection to straddle elbows in the AI problems space.
Triton is a domain-specific programming model and compiler that enables programmers writing in Python to create code that runs on GPUs, even those with little experience with GPUs and GPU-specific programming languages such as CUDA. This is because it hides the thread-based CUDA programming model from developers, allowing the Triton compiler to make better use of GPU hardware, for example by optimising cases that might otherwise require explicit synchronisation. Additionally, Triton's abstraction allows programmers to operate on tensors instead of scalar values, significantly simplifying and speeding up the process of developing code on the GPU.
Triton works with Python, however, but for Java too, a transfer window on the use of the Triton programming model opens up thanks to Code Reflection, developed as part of Project Babylon. As a reminder, Code Reflection allows Java programmes to be symbolically represented so that they can be analysed and automatically transformed into the Triton code model. This allows programmes written in Java to be compiled into code that runs on the GPU, similar to what Python does using Triton. The Babylon project in this context acts as a bridge between Java and GPU-specific solutions, opening the door for developers to the world of GPU programming with all its benefits, such as extended large-scale parallel computing capabilities.
On a technical level, the process begins by creating a Java code model through code reflection. This model is then analyzed and transformed into a Triton code model. During this transformation, appropriate types are assigned to the model elements. This step ensures that the Java code can be accurately converted into GPU-compatible code, resulting in a form that resembles the Triton MLIR.

If you're interested in learning more, the article provides detailed examples, such as how adding vectors in Java can be nearly as straightforward as in Python, even without features like operator overloading in Java. For further information, check out the original publication.
3. Release Radar

Quarkus 3.8
Let's dive into the Little but Big updates in Quarkus. The spotlight is on version 3.8, crowned as the new Long-Term Support (LTS) version. This version smoothly follows the 3.7 release, without introducing any groundbreaking features but rather refining it with a handful of fixes. Among these, the patch for CVE-2024-1597, concerning the PostgreSQL JDBC driver, stands out. For those who haven't upgraded since the last LTS version, 3.2, jumping to 3.8 will feel like a significant leap forward. You'll get to enjoy enhancements in OpenTelemetry, support for Java 21 (with JDK 17 as the new minimum requirement), OpenIDConnect support, and a suite of other upgrades.
Scala 3.4.0
Paweł Marks from VirtusLab has announced the release of a new version of Scala - Scala 3.4. Among the most important new features in the new release are certainly the stabilisation of important SIPs:
SIP-54 - simplifying the import of Extension Methods from various sources
SIP-53 - increasing the expressivity of type patterns.
SIP-56 - streamlining type inferencing, especially for functions such as
fold.
What's more, Scala 3.4.0 introduces improvements to the backend, optimising polymorphic lambdas by using JVM-derived lambdas, making Scala independent of anonymous classes. The new version also improves error reporting, including more informative messages for incompatible versions of TASTy.

Scala 3.4.0 also introduces the experimental @publicInBinary annotation, which allows certain definitions to be tagged as part of the binary API. The version also deprecates outdated constructs, such as wildcards of types _ and private[this] (and several others), in favour of more modern and concise alternatives. In general, I encourage you to take a look at the original Release Notes, as there are more interesting details for Scala users there.
Rainbow Gum
And now I have a real curiosity from the developers of jstachio, a framework that is a Java templating system based on mustache already described here in the past. This is because Rainbow Gum takes it upon itself to deal with the complexity and inefficiency of current Java logging frameworks, especially in the context of very fast-start applications. Traditional logging frameworks such as Log4J 2 and Logback are not only loaded with features that may not be necessary for all applications, but also rely on external configuration files that can slow down application initialisation and increase security risks, as the Log4Shell vulnerability has shown.

This creates the need for a more simplified, pre-configured logging solution that, without having years of development on its back, can quickly adapt to new Java features and a multitude of runtime environments.
Rainbow Gum is just such a lightweight implementation of SLF4J for JDK 21+, which aims to be easier to use while taking advantage of newer JDK technologies. Rainbow Gum does not offer as much flexibility as Logback or Log4J, but it simplifies configuration and initialisation. Rainbow Gum is designed to be compiler-friendly for the native Graal VM. By allowing the whole thing to be configured via the application code, Rainbow Gum allows developers to exploit to avoid the pitfalls associated with external configuration files, leading to faster application start-up and reduced vulnerability space.
public class GettingStartedExample implements RainbowGumProvider {
@Override
public Optional<RainbowGum> provide(LogConfig config) {
return RainbowGum.builder(config)
.route(r -> {
r.level(Level.DEBUG, "com.myapp");
r.appender("console", a -> {
a.encoder(new PatternEncoderBuilder("console")
.pattern("[%thread] %-5level %logger{15} - %msg%n")
.fromProperties(config.properties())
.build());
});
})
.optional();
}
}It's designed to be both modular and minimalist, yet it supports advanced features like color-coded logs and JSON support.
I wonder if Rainbow Gum is the harbinger of some new trend of libraries optimised for specific use with GraalVM and AOT.
Coat
And finally Coat, which is another of the representatives of my favourite category of small libraries that respond to a specific problem. The one that Coat solves is the need for efficient and "typesafe" management of configuration data. Traditionally, reading and integrating such behind an application involves manual parsing, validation and conversion to the necessary structures, which is error-prone and cumbersome. The manual nature of the process increases the risk of errors and inconsistencies, especially in complex applications where the configuration changes frequently or is required to be validated against specific criteria. In addition, developers often have to write special mappers to ensure that configuration values correspond to the expected types.
Coat offers a solution to the above problems through its annotation processor, which generates classes to read configuration values into typed objects. By defining an interface with the expected configuration data structure and using the appropriate annotation, Coat automatically creates concrete implementations.
@Coat.Confg(converters = {
UuidConverter.class,
CurrencyConverter.class,
})
public interface AppConfig {
public UUID uuid();
public Currency currency();
}
final AppConfig config = new ImmutableMyConfig(new File("/path/to/config.properties"));
try {
config.validate();
} catch (final ConfigValidationException ex) {
System.err.println("Error in config file:\n" + ex.getValidationResult().toString());
System.exit(1);
}
final UUID appName= config.uuid();
final Currency currency= config.currency();Support parsing, validation and conversion of configuration value types. Coat, requires no runtime dependencies and supports Java 11 or higher.
And finally, I will share a new hobby!
Cause when the world is playing Final Fantasy VII Rebirth and you're not because you're taking care of your 3-year-old daughter with pneumonia and she says: "Dad, let's make something out of clay."...

...creativity is activated.